
はじめに
こんにちは。富士通研究所プラットフォーム革新PJの川上です。理化学研究所/富士通が共同で開発した新しいスーパーコンピュータ「富岳」が神戸市沖のポートアイランドに納入され、当初の予定を前倒しして今年度から試行運用が開始されました。6月には早速、スパコンランキングで世界初の同時4冠(TOP500, HPCG, HPL-AI, Graph500)を獲得するなど、幸先のよい立ち上がりを見せています。私が所属する部署では富岳を始め、富岳と同じCPUを搭載した弊社製品PRIMEHPC FX1000/700上でディープラーニング(DL)処理を高速に実現する技術の研究開発をしています。今回は、DL処理を高速に実現するoneDNNというライブラリソフトウェアを富岳向けに移植し、開発したソースコードを本家IntelのoneDNNに寄稿し、取り込まれた話をご紹介します。
ディープラーニング処理のソフトウェアスタック
ディープラーニング処理(以下、DL処理)を用いたアプリケーションは、通常、下図に示すように、フレームワーク層とライブラリ層の2層から成るソフトウェアスタックにより実現されます。ユーザーがDL処理を用いたアプリケーションを実行したい場合、フレームワークが用意するAPIを用い、処理を行いたいニューラルネットワークの定義や処理内容を記述します。フレームワークは与えられた定義や処理内容に基づき、ライブラリソフトウェアの機能を呼び出して、DL処理の計算を実際に実行します。DL処理を実行するシステムは、スパコン、クラウド、パソコン、スマホなどの様々な規模のものがあり、またシステムの中で実際に処理を行うH/WがCPUの場合もあれば、GPUの場合もあります。ソフトウェアスタックをこのような2階層にしておくことで、DL処理を実行するシステムやH/Wが違ったとしてもその違いはライブラリ層が吸収し、ユーザーには同じフレームワークを使うことを可能とすることで、ネットワーク定義の仕方や処理の記述方法などの使い勝手を共通化できるというメリットがあります。
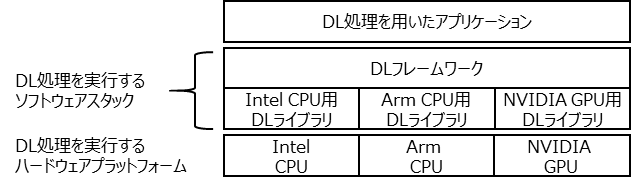
ライブラリソフトウェアはシステムやH/W性能を最大限に引き出すために、個別に最適化したものが用意されます。通常、H/Wの開発・製造ベンダが開発しており、Intel製CPU用のライブラリであればIntelが、NVIDIA製GPU用のライブラリであればNVIDIAが開発し、提供しています。富岳やFX1000/700にはArmv8-A命令セット(これはAndroidスマホやiPhoneに搭載されているCPUと同じ)に、High Performance Computing向けのScalable Vector Extension(SVE)という命令セットを追加拡張したCPU A64FXを搭載しています。Armv8-A命令セットに加えてSVE命令セット(以下、まとめてArmv8-A命令セットと呼ぶ)に対応したCPUはA64FXが世界初であるため、これに最適化されたDL処理ライブラリは存在していませんでした。
Armアーキテクチャ向けDL処理ライブラリ開発
私が所属する部署のミッションの1つは、富岳の上でDL処理を高速に動かすことです。Armv8-A命令セット向けのDL処理ライブラリは存在してなかったので、新規に開発する必要がありました。ただし、富士通が単独で新規ライブラリを開発したとしても、フレームワーク側から簡単に使える形になっていないと、実質、ユーザーが使えることになりません。我々は、Intelがx64命令セット向けに開発しているoneDNNというDLライブラリをArmv8-A命令セットに移植することにしました。oneDNNはCPUを使ったDL処理ライブラリのデファクトスタンダードであり、すでに様々なフレームワークでサポートされていました。そのためoneDNNのAPIを持つArmv8-A向けディープラーニングライブラリがあれば、フレームワークに手を入れることなくユーザーはライブラリを利用できます。 フレームワークと同様に、oneDNNもOpen Source Software (OSS)としてソースコードが公開(https://github.com/oneapi-src/oneDNN)されているため、それを入手しArmv8-A命令セット向けにコンパイルし直すことができます。しかし、oneDNNはx64命令セット向けにアセンブラレベルで最適化した実装を多数含んでいるため、元々のソースコードをそのままコンパイルし直しただけでは、まったく性能が出ませんでした。ここからが苦難のはじまりでしたが、なんとかArmv8-A向けoneDNNの開発を完了したのでした(詳細は後述します)。
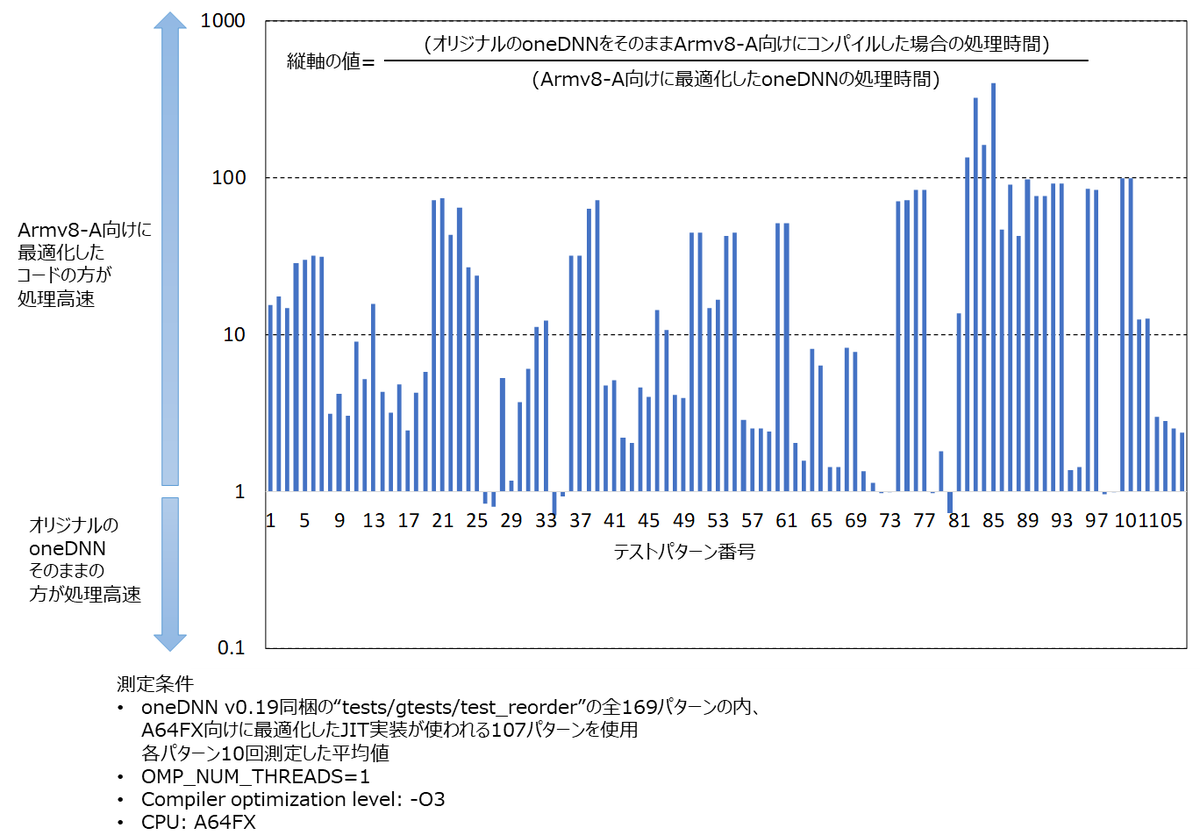
下図は我々がArmv8-A向けに最適化を行ったことによる処理速度向上の例です。oneDNNではDL処理で用いられるconvolution、batch_normalization、eltwise、pooling、reorderなどの様々な処理を行うことができます。下図はそのうちのreorder処理(データの型変換や順序を入れ替える処理)について、オリジナルのoneDNNのソースコードをそのままArmv8-A命令セット向けにコンパイルした場合と、我々が最適化実装を施した後のソースコードをコンパイルした場合の処理速度の比較です。オリジナルのoneDNNをそのままコンパイルして得られたソフトウェアでの処理速度を1として正規化しています。テストパターンの種類にもよりますが、最大約400倍も高速化されています(いくつかのテストパターンでは最適化により遅くなっているが、測定誤差や処理時間の絶対値が小さいため、フレームワークと結合して使う場合は問題にならない)。reorder以外の処理についても、Armv8-A向けに最適化することにより、文字通り、桁違いの処理速度向上を得ています。
本家oneDNNへソースコードを寄稿
oneDNNはOSSとしてソースコードが公開されているだけでなく、誰でも改善したソースコードのプルリクエスト(改善したソースコードをoneDNNの一部として取り込んでもらう要望)を出すことができるオープンな開発スタイルが採られています。プルリクエストを出したソースコードはレビューされ、バグがないこと、oneDNNの処理速度改善や機能拡張に貢献するものであることが認められれば、oneDNNの一部として正式に取り込まれます。oneDNNはx64命令セットを有するCPU向けに開発が始められたソフトウェアです。我々は、oneDNNをArmv8-A命令セット向けに移植、最適化した改造版oneDNNのソースコードをhttps://github.com/fujitsu/oneDNNで公開しています。しかし、富岳ユーザーおよび世の中のArmv8-A命令セットを採用するCPUのユーザーの事を考えた場合、DL処理ライブラリのデファクトである本家のoneDNNに最高にチューニングされた実装が最初から組み込まれていた方がよいと考えました。そこでIntelと協業し、我々の開発成果を積極的に本家oneDNNへプルリクエストしていくことを決めました。
ところで、oneDNNをArmv8-A命令セット向けに最適化するという改良は、後述するXbyak_aarch64という必須技術を組み込むなど非常に大がかりなものでした。小規模な改良の場合、ソースコードを修正してそのままプルリクエストを出せばよいです。しかし、ソースコード改変の規模が大きいものやフレームワークとの連携部分のAPIの変更などに関するプルリクエストを出す場合は、oneDNNでは事前にその修正内容や方針をRequest For Comments (RFC)というドキュメントにまとめる必要があります。そして、RFC自体のプルリクエストを出し、レビュー → マージという手順をとる取り決めになっています。さあ、世の中の富岳ユーザー、Armv8-Aユーザーのために一生懸命RFCを書きましたよ。日頃の論文を書くより真面目に書きました。頑張りました。書き上げました。RFCのプルリクエストを出しました。程なく、Intelの開発者の方からいろいろとRFCの内容について、質問が来ました。夜遅くまで一生懸命回答を書きました。そして寝ました。起きました。起きたら既に次の質問が書き込まれてました。Intelの開発者の方はアメリカ在住なので時差の関係で、書いて寝て起きたらすでに次の質問が来てました。めげずに回答を書きました。寝ました。起きました。次はIntelの開発者の方が、関係するからとArm社の開発者を召喚してました。2対1の戦いになりました。Armの開発者の方はイギリス在住です。Arm、Intelの時間差攻撃です。厳しい戦いでした。しかし、なんとかすべての質問に回答し終え、最終的には私の出したRFCを認めてもらいました(実際は、純粋に技術的な質疑のやりとりで、皆さんとても紳士的なやりとりをしてくださる、よい人ばかりです。時差の関係で回答を書いたらすぐに次の質問が来るというのは、むしろ質疑がスムーズに進んで、RFCマージまでの日数が短縮されるメリットがあります)。 RFCがマージされた後は、RFCに基づいて修正したソースコードについてプルリクエストを出すことになります。ここでもやはり、Arm、Intelの時間差攻撃を迎え撃ちつつ、なんとかソースコードのマージにたどり着きました。
さて、このArmv8-A命令セットに最適化したソースコードをIntelさんが開発を主導するOSSにマージするという成果ですが、「えっ、なんでそんなことできるの?」と弊社の中でどよめきが起きました。当然ですよね。Intelさんにとってみると競合他社を助けることになりますから。もちろん、第1の理由としてはIntelさんが他CPU向けにプルリクエストの門戸を開いてくれていたからと言うのがあります。Intelさんにはこの場を借りて感謝申し上げます。第2の理由は、我々が開発したソースコードが技術的にしっかりしたものであり、DL処理ライブラリの発展に貢献するものであると認められたのかなと思っています。この点は少し誇りに思っています。
Xbyak_aarch64の開発
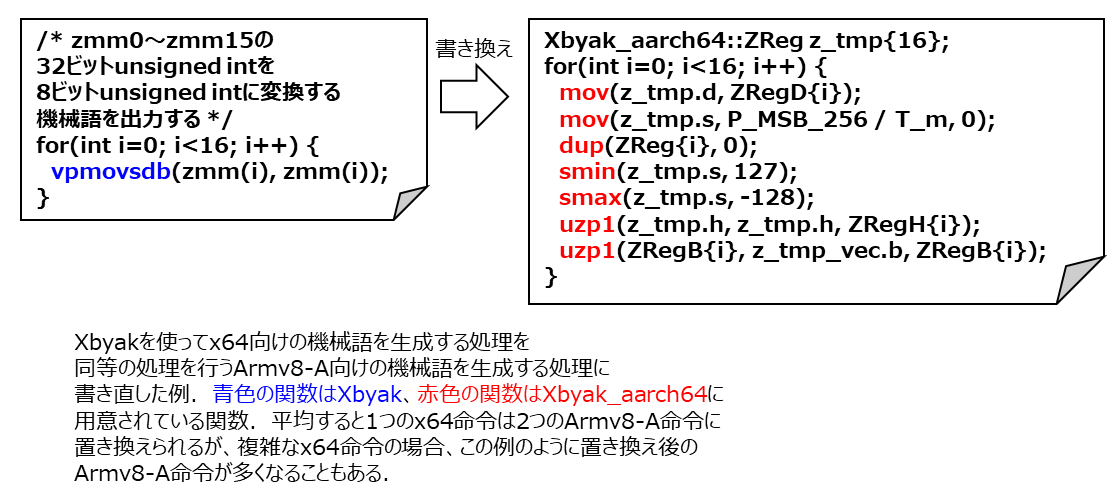
さて、ここからはoneDNNをArmv8-A命令セット向けに移植・最適化した際の少し突っ込んだ技術的な話をご紹介します。 Intelが開発したoneDNNにはキー技術の一つとして、XbyakというJITアセンブラを組み込んでいる点があります(下図参照)。

Xbyakはサイボウズラボの光成さんが開発し、OSSとして公開(https://github.com/herumi/xbyak)されているソフトウェアです。Xbyakは以下の特徴があります。
- アセンブラプログラムをC++で記述できる
- 実行時に実行コードを生成する
1の特徴だけ見ると、インラインアセンブラやintrinsic関数でアセンブラ命令を指定していくのと変わらないように思えるかもしれません。Xbyakではループ処理部分のヘッダやテイル部分も含めてサブルーチン全体を完全にアセンブラレベルで書くことができ、開発者が意図しない命令がコンパイラによって挿入されたりすることなく、意図通りに命令列を作ることができる点が優れています。また、2の特徴が非常に強力です。実行時のプラットフォームの情報(CPUコア数、キャッシュメモリ容量、対応する命令セット)や実行時に決定するパラメータを考慮して、最適な実行コードを作り分けることができます。例えば、CPUコア数やキャッシュメモリ容量に応じて、最適なループ分割をした実行コードを生成させたり、ある条件分岐処理が実行時に決定するパラメータによって必ず実行されないことが保証される場合、そもそもその条件分岐処理を除外した実行コードを生成させたりすることができ、高度に最適化した実行コードを実現することができます。Xbyakについては、開発者の光成さんご自身が紹介スライドを公開(https://www.slideshare.net/herumi/xbyak)されていたり、Xbyakに様々なサンプルコードが付属したりしていますので、興味がある方はそちらを参照ください。
ところで、Xbyakはx64命令セットの実行コードを生成するソフトウェアです。したがって、Armv8-A命令セットを実行するA64FX向けには使うことができません。oneDNNをArmv8-Aへ移植するためには、Xbyakと同等の機能をArmv8-A命令セット向けに実現するソフトウェアを新規に作る必要がありました。Armv8-A命令セットはオペランドのバリエーションも考慮すると4,000を超える種類の命令があります。すなわち、4,000を超える機械語を生成する関数の実装と検証が必要になります 。ちなみに、x64の場合は軽く1万種類を超えています。数えるのを躊躇するぐらいの数です。
非常にボリューミーな開発ではありましたが、Xbyakの光成さんから技術的なアドバイスも受けられたという幸運も手伝い(光成さんが書かれたブログ(https://blog.cybozu.io/entry/xbyak_for_fugaku)や、技術評論社さんの紙面上の対談記事(https://gihyo.jp/news/interview/2020/12/1801)も是非、アクセスしてみてください)、なんとか開発したArmv8-A向けXbyakはXbyak_aarch64と命名し、https://github.com/fujitsu/Xbyak_aarch64で公開しています。先に書いたように、皆さんがお持ちのAndroidスマホやiPhoneはArmv8-A命令セットを採用したCPU (ただし、SVE命令は非対応)が載っています。したがって、Xbyak_aarch64を使って生成するArmv8-A命令セットの実行コードを動かすことができるということです。もしかしたら、将来Xbyak_aarch64を使って作られたソフトウェアが知らないうちにあなたのスマホの上で動いているかもしれません。
Xbyak_aarch64の完成により、oneDNNを本格的にArmv8-Aへ移植する準備が整いました。oneDNNにはDL処理で使われるconvolution、batch_normalization、eltwise、pooling、reorderなど、様々な処理がXbyakを使って実装されています。手始めに、一番処理内容がシンプルなreorderをXbyak_aarch64を使ってArmv8-A命令セット向けに移植してみました。JITアセンブラを使った実装とデバッグのやり方をマスターしつつ、実装と機能検証を完了させることができました。「見せてもらおうか、富士通研のXbyak_aarch64の性能とやらを」と心の中でつぶやきながらXbyak_aarch64を使った実装と、そうでない、オリジナルのoneDNNのアルゴリズムを素直にC++で書き下した実装との処理速度差を比較しました。「Armアーキテクチャ向けDL処理ライブラリ開発」に載せたグラフはこのときに測定した結果になります。この結果は自分で作っておきながら驚きました。まさか、最大約400倍、2桁以上も高速化されるとは。
Xbyak_translator_aarch64の開発
Xbyak_aarch64の完成により、基本的にはoneDNNをArmv8-A向けに移植することが可能になりました。ですが、1つ問題がありました。移植開発に必要な工数がまったく足りません。Xbyak_aarch64を使って書き換えると一言で表していますが、実際には以下のような作業に該当します(下図参照)。
- oneDNNのソースコード上に現れるXbyakで実装される関数を確認し、この関数が生成するIntel CPUの命令がどんな処理を行う命令なのかを一つ一つIntel CPUのリファレンスマニュアルを見て確認する。
- oneDNNのソースコードでXbyakを使って実装されている部分を確認し、全体としてどのような処理を行う実行コードを生成するのかを理解する。
- 2で理解した実行コードをArmv8-A向けに生成するため、どのArmv8-A命令を使ったら良いかをArmv8-Aリファレンスマニュアルを見て確認し、Xbyak_aarch64が提供する関数を使ってコーディングしていく。
これはなかなか大変な作業です。ある意味、知らない外国語をもう一つの知らない外国語に翻訳するような作業です。たまたま私の近くに座っていた最適化が得意な本田さんが手伝ってくれることになったのですが、、なにぶんoneDNNには多くのDL向けの様々な処理が用意されており、いかに凄腕研究員といえども一人でやりきるのは困難な量でした。かと言って、今時、アセンブラレベルの実装を理解しながらコーディング作業ができる人材を豊富に集められる状況にもありません。困りました。そこで、Xbyakを使って実装されたソースコードを(ほぼ)書き換えることなく、Armv8-A向けの実行コードを生成することができるようにしてしまう、JITアセンブラの翻訳機能:Xbyak_translator_aarch64(コードネーム:開闢補完計画)を開発することにしました。 下図にXbyak_translator_aarch64(以下、Translator)の動作を示します。Translatorは次の流れでArmv8-A命令の機械語生成を行います。
- Xbyakを使ってx64の機械語を生成する。
- 1で生成した機械語をデコードし、命令の種類(add/sub/mov/vpaddd/vpsubd/vpmovusdwなど)とオペランドの情報(レジスタオペランド:レジスタの種類(汎用32/64ビットレジスタ、xmm/ymm/zmmレジスタ)、レジスタの番号、メモリオペランド:アドレッシングモード、アドレスレジスタ、displacementなど)を取得する。
- 2で取得した情報を元に、対応するArmv8-A命令列(1つのx64命令は1つ以上のArmv8-A命令に変換される)に変換し、この命令列に対応するXbyak_aarch64の関数をcallしてArmv8-Aの機械語列を生成する。
- 1~3を、Xbyakを使って生成されるすべてのx64の機械語に対して行う。
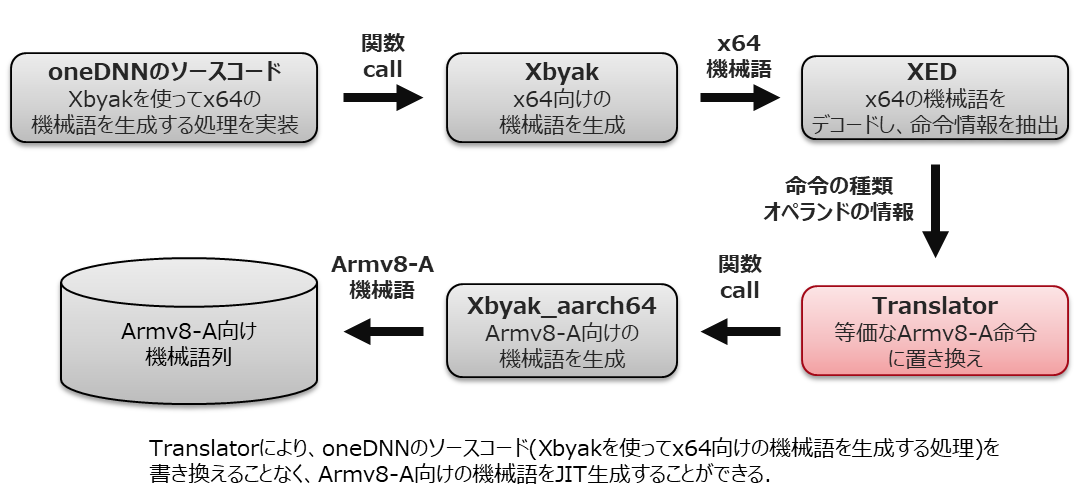
2のx64機械語のデコード処理はIntelがOSS公開しているIntel XEDというライブラリを使うことで開発不要とできました。Translatorの主たる開発部分は、3のx64命令とArmv8-A命令列の対応関係を定義することに集約されます。
実はXbyak_translator_aarch64を最初に実装しようとしたときはこのような手法ではありませんでした。上記1、2の手順を経ず、Xbyakのインターフェース(関数callの引数や返値)はそのままで、中の実装を修正してXbyak_aarch64の関数を直接callする方式での実装を試しました。しかし、挫折しました。x64命令セットは長い拡張の歴史があり、非常に複雑な命令エンコーディング体系になっています。どこにどんな情報がエンコードされているかを理解するのは一朝一夕ではできません。Xbyak_aarch64の開発でも同じですが、この手のソフトウェアで怖いのは命令レベルで誤った挙動をするバグが入ることです。x64の命令をArmv8-Aの命令に変換する際に1つでも誤変換があっては、正しくプログラムが動きません。そして、この誤変換はあとからデバッグすることが非常に困難であることが容易に推測できます。oneDNNがXbyakを使って生成する1つのサブルーチンは、一番多いもので1万ステップを超える命令から成ります。プログラムは完走する、でも計算結果が違う。どうやら1万ステップの中のどこかで命令変換ミスがあるようだ。どうやって見つけましょう?
ということで、考え方を改めました。もう、x64の機械語は一旦生成しちゃってください。それを逆アセンブルして、各x64命令の情報は分かりやすい形で取り出して、そのあと料理しちゃいますから、という上図の方式にたどり着きました。そして、そういう処理方式をとるのであれば、逆アセンブル処理についてはIntel XEDというIntel製のライブラリが使えるよという光成さんからのアドバイスを早々にいただけるという幸運にも恵まれ、無事、Xbyak_translator_aarch64を開発することができたのでした。
さて、読者の中にはTranslate処理のオーバーヘッドは大丈夫なのかという疑問を持たれた方もいらっしゃるかもしれません。鋭いです。実際、Xbyakでx64の機械語を生成->デコード->対応するArmv8-Aの機械語を生成という手順をたどるため、Armv8-Aの機械語列を生成する処理にそこそこ時間がかかります。と言っても、1秒に満たない時間です。DLの処理というのは、例えば画像識別のためのニューラルネットワークを学習する処理といった場合、何百万枚もの教師画像データに対して繰り返し処理を行うといったことが行われます。スパコンを使って数時間とか数日といったオーダーの計算時間です。それと比べると、実行コード生成に1秒かかるというのは全く無視してかまわないことになります。今回の開発方式を選択では、DL処理のこのような計算特性も考慮して行いました。
Translatorにより、x64向けに実装されたoneDNNのソースコードを書き換えることなく、そのままArmv8-A命令セット向けに流用できることになります。x64とArmv8-Aの命令セットの差はTranslatorがすべて吸収してくれます。oneDNNは現在も盛んに開発が進められており、日々、DL向けの新しい処理の追加や、さらなる最適化がXbyakを使ってx64命令セット向けに行われています。これら機能追加・最適化をタイムリーにArmv8-A向けに提供することができるようになりました。実際にoneDNN v1.6のXbyakを使って実装されている一部を、Translatorを使ってArmv8-A向けへの移植を行ってみました。約2週間でArmv8-Aで充分速い1処理速度で動かすことができました。oneDNNはIntelが4年以上の歳月をかけてx64向けに最適化を重ねてきたソフトウェアです。それを、あまりにもサクッと移植できてしまったことに驚きました。 TranslatorのソースコードもOSSとしてhttps://github.com/fujitsu/Xbyak_translator_aarch64で公開しています。興味がわきましたら参照してみてください。
CPUを用いたDL処理速度業界最高レベルを達成
Xbyak_aarch64、Xbyak_translator_aarch64という2つの武器を手にした我々はoneDNNを一通りArmv8-A向けへの移植を完成させています。下図はフレームワーク側ソフトウェアとしてTensorFlowと組み合わせた場合のResnet-50の処理速度の測定結果です。オリジナルのoneDNNのソースコードをArmv8-A向けにコンパイルしただけのoneDNNを用いると、冒頭のグラフのように数百倍の処理速度差があるので、oneDNNの替わりに汎用的な数値演算用のライブラリを用いた場合と、今回開発したArmv8-A向けに最適化したoneDNNを用いた場合とで比較しています。Armv8-A向けに最適化したoneDNNにより、学習処理では9.2倍、推論処理では7.8倍と大幅に高速化することができています。
Xbyak_aarch64が命令レベルでカリカリに最適化した実行コードの生成を可能にし、Xbyak_translator_aarch64がx64向けのソースコード流用による大幅な開発工数短縮を実現したことにより、高い処理性能を実現するoneDNNを短い開発期間でArmv8-A向けに移植・最適化することができました。
oneDNNのArmv8-A向け移植開発の現在 Xbyak_aarch64、Xbyak_translator_aarch64を組み込み、Armv8-A向けの移植を完成させたoneDNNのソースコードはhttps://github.com/fujitsu/oneDNNで公開しています。また、このブログの冒頭に記載したように、Xbyak_aarch64とreorder処理のJITコード生成処理は本家oneDNNにプルリクエストを出し、正式に取り込まれました。今後、その他の処理についても順次プルリクエストを出していく予定です。
我々が開発したXbyak_aarch64/Xbyak_translator_aarch64/ Armv8-A向けoneDNNは、いずれもhttps://github.com/fujitsuにてソースコードを公開し、透明性の高いスタイルで開発を進めています。ご意見、コメント、ソースコードのプルリクエスト大歓迎です。メールの場合はこちらarm_dl_oss[at mark]ml.labs.fujitsu.comへお願いします。もちろん、github上でのISSUEへの書き込みもwelcomeです。
まとめ
OSSとして開発が進められているDL処理のライブラリソフトウェアoneDNNを、スーパーコンピュータ富岳で高速に動作させるため、Armv8-A命令セット向けに最適化し移植しました。また、oneDNN移植に際し、必要不可欠なキー技術であるArmv8-A向けJITアセンブラXbyak_aarch64と、移植開発を加速するXbyak_translator_aarch64の開発についてご紹介しました。我々が開発したXbyak_aarch64と、それを使ったArmv8-A命令セット向けに最適化したソースコードは、本家oneDNNに正式に取り込まれています。今後も、我々が開発したArmv8-A向けに最適化した実装は継続的にプルリクエストを出していく予定です。いつか、皆さんのお手元のスマホの上で、我々が開発したソフトウェアが動作する日が来ることを夢見て、研究開発を継続していきます。
著者紹介

川上 健太郎(写真:右)
2007年富士通研究所入社。これまで、画像コーデックLSIやセンサノードの研究開発などに携わる。2019年よりArm HPC環境向けのディープラーニング処理ソフトウェア開発に従事。github.comのアカウントはkawakami-k。
栗原 康志(写真:左)
2009年富士通研究所入社。組み込み向けマルチコアプロセッサのソフトウェア技術、HEVC画像コーデック回路、ワイヤレスセンサーネットワーク制御システム、無線干渉可視化技術の開発に携わってきた。2019年よりArm HPC環境向けのディープラーニング処理ソフトウェア開発に従事。右膝靭帯を負傷するほどのフットサル愛を持つ。github.comのアカウントはkurihara-kk。
福本 尚人(写真:中央)
2012年より富士通研究所でプログラムの高速化に関する研究開発に従事。最新ハードウェア向けに、HPCアプリ、Linapck、行列積などの高速化を行ってきた。2019年より、マネージャーとしてArm向けDeep learningのソフトウェアスタック開発を行っている。
-
最新Intel製CPUで実現される性能の約70%とか。最終的にA64FXの最高性能を引き出し切るには、処理のボトルネック部分についてはXbyak_aarch64を使ってTranslatorを介さず直接最適なJITコードを組み立てるのがよい。↩