
こんにちは.富士通研究所人工知能研究所の安富優と酒井彬です。
富士通研究所では、理化学研究所(理研)革新知能統合研究センターがん探索医療研究チームの小松正明研究員、浜本隆二チームリーダー、昭和大学医学部産婦人科学講座の松岡隆准教授と共同で、人工知能(AI)を用いて胎児の心臓異常をリアルタイムに自動検知するシステムを開発しています。 (プレスリリース)
この度、そのシステムに関わる技術が複数の論文誌で採択されたので、その概要についてご紹介します!
- 対象論文
- Shadow Estimation for Ultrasound Images Using Auto-Encoding Structures and Synthetic Shadows
- Suguru Yasutomi *, Tatsuya Arakaki, Ryu Matsuoka, Akira Sakai, Reina Komatsu, Kanto Shozu, Ai Dozen, Hidenori Machino, Ken Asada, Syuzo Kaneko, Akihiko Sekizawa, Ryuji Hamamoto, Masaaki Komatsu
- MDPI Applied Science
- Detection of Cardiac Structural Abnormalities in Fetal Ultrasound Videos Using Deep Learning
- Masaaki Komatsu*, Akira Sakai*, Reina Komatsu*, Ryu Matsuoka, Suguru Yasutomi, Kanto Shozu, Ai Dozen, Hidenori Machino, Hirokazu Hidaka, Tatsuya Arakaki, Ken Asada, Syuzo Kaneko, Akihiko Sekizawa and Ryuji Hamamoto: The starred authors( * ) are contributed equally
- MDPI Applied Sciences
- Image Segmentation of the Ventricular Septum in Fetal Cardiac Ultrasound Videos Based on Deep Learning Using Time-Series Information
- Ai Dozen*, Masaaki Komatsu*, Akira Sakai*, Reina Komatsu, Kanto Shozu, Hidenori Machino, Suguru Yasutomi, Tatsuya Arakaki, Ken Asada, Syuzo Kaneko, Ryu Matsuoka, Daisuke Aoki, Akihiko Sekizawa and Ryuji Hamamoto: The starred authors( * ) are contributed equally
- MDPI Biomolecules
- Model-Agnostic Method for Thoracic Wall Segmentation in Fetal Ultrasound Videos
- Kanto Shozu*, Masaaki Komatsu*, Akira Sakai*, Reina Komatsu, Ai Dozen, Hidenori Machino, Suguru Yasutomi, Tatsuya Arakaki, Ken Asada, Syuzo Kaneko, Ryu Matsuoka, Akitoshi Nakashima, Akihiko Sekizawa and Ryuji Hamamoto: The starred authors( * ) are contributed equally
- MDPI Biomolecules
- Shadow Estimation for Ultrasound Images Using Auto-Encoding Structures and Synthetic Shadows
- 超音波画像における音響陰影の検出 (安富)
- 超音波検査動画を活用した胎児心臓の異常検知 (酒井)
- 胎児心臓の心室中隔のイメージ・セグメンテーション (酒井)
- 胎児の胸郭壁のイメージ・セグメンテーション (酒井)
- まとめ
超音波画像における音響陰影の検出 (安富)
超音波検査で臓器を調べるときによく問題になるのが、音響陰影です。 超音波検査は、各臓器の境目で少しずつ超音波が反射してくることにより成立します。 しかし、完全に反射してしまう骨などに超音波がぶつかると、そこから先の様子は見えなくなってしまい、画像上では暗い領域として表示されます。 これを音響陰影 (あるいは単に影) と呼びます。
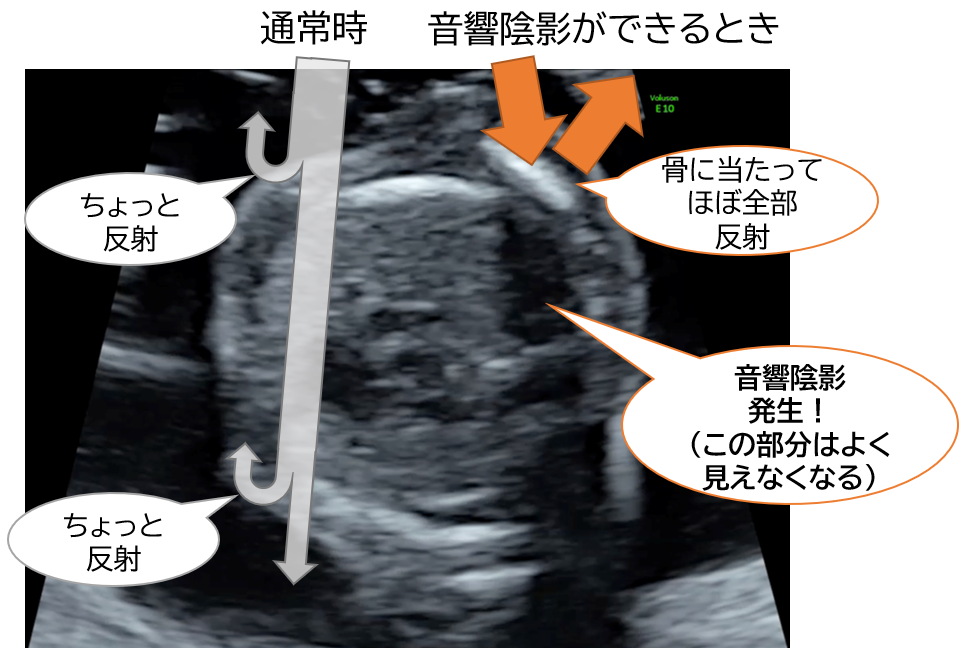
こういった影ができてしまうと、そこに写るべきだった臓器は見えないので、検査に支障があります。 検査のエキスパートであれば、その場で検査機器を操作することで影のない画像を取得することもできますが、検査者すべてがそういった技術を持っているわけではありません。 また、前述のような機械学習技術を用いて画像認識をする場合にも、影は邪魔になります。 そこで、超音波画像に影が含まれてしまっていることを検査者にお知らせするため、影を検出と濃さの推定を行う技術を研究開発しました。 (注: 影を消す、つまり適当な画像を生成して影の部分を埋めてしまう方向性も考えられますが、そのようにして生成した画像は言わば嘘の画像なので臨床現場で使うには向きません。)
今回提案した手法は、ディープラーニングにおける代表的な教師なし学習手法であるオートエンコーダを拡張したものです。 入力された超音波画像をエンコーダ、デコーダを通し「影の予測画像」と「影を除去した画像」に一旦分離して、それらを合成することで入力画像に再構成します。 学習時はオートエンコーダの構造によって教師なしデータを有効活用し、適用時には影の予測画像をもって影の検出結果とします。
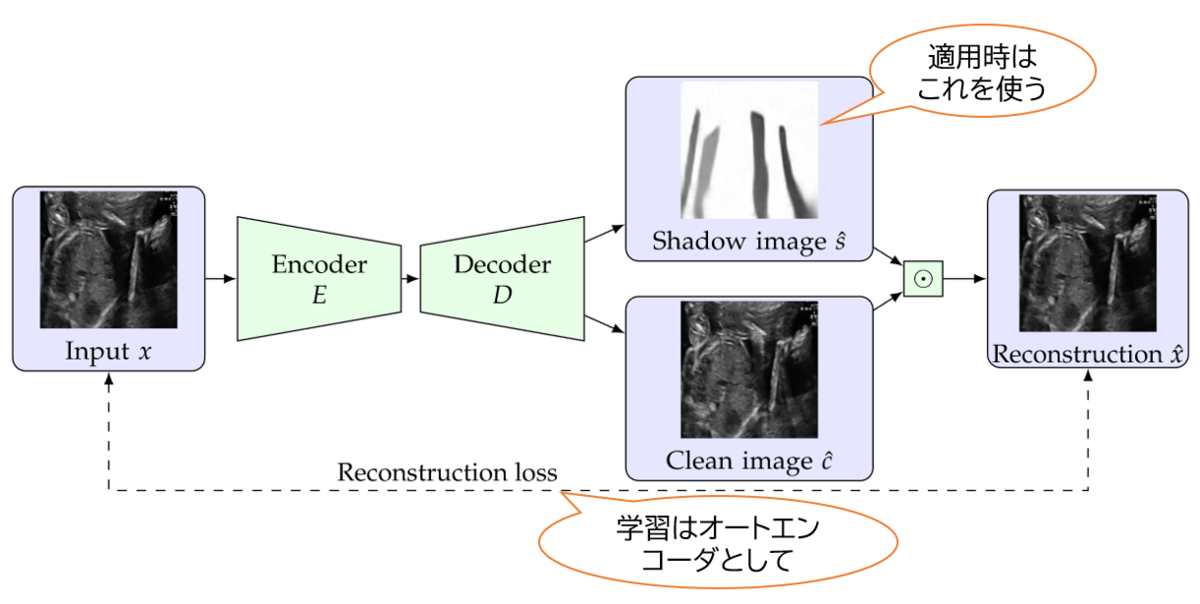
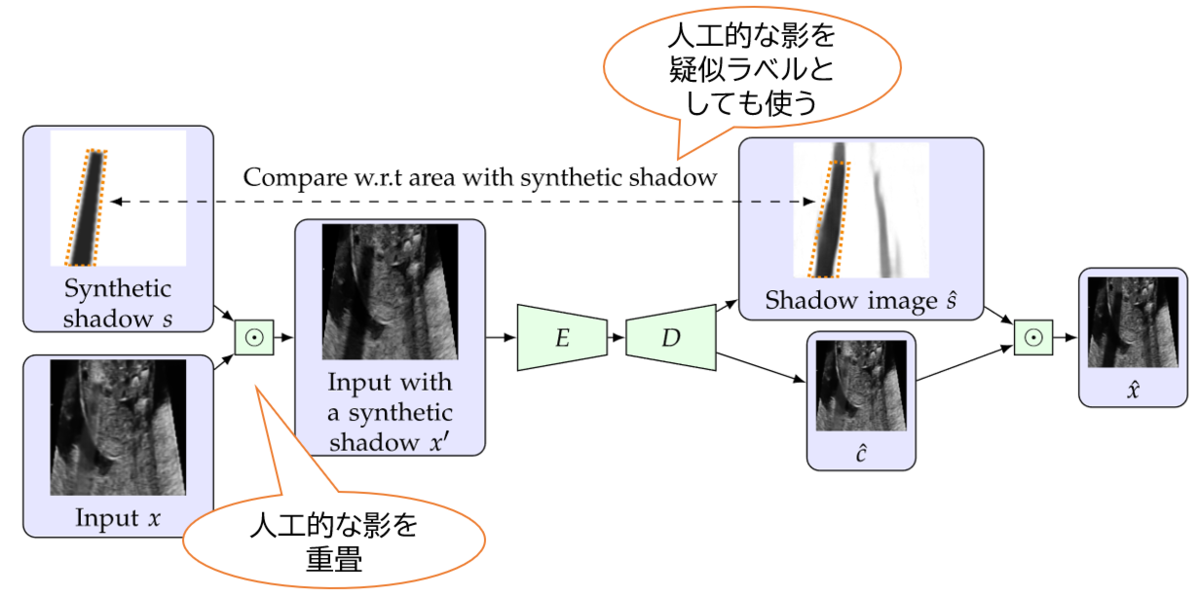
当然のことながら、このようなモデルを構成して再構成画像を生成するオートエンコーダとしての学習をするだけでは、「影の予測画像」と「影を除去した画像」への分離はできません。 そこで、人工的な影をルールベースのアルゴリズムで生成・入力画像に重畳し、これを擬似的な教師データとして使うことを提案しました。 (注: 実は超音波画像上に出現する影の形状はだいたい決まっています。例えば今回使ったデータではバームクーヘンを切った形の影ができやすいので、そういった形状をランダムに生成して人工的な影として用いました。) これによって教師なしデータしかない状態でも効果的に影を検出できるようになりました。 また、教師ありデータがある場合にはそちらも併用して、半教師あり学習のようなやり方で学習します。
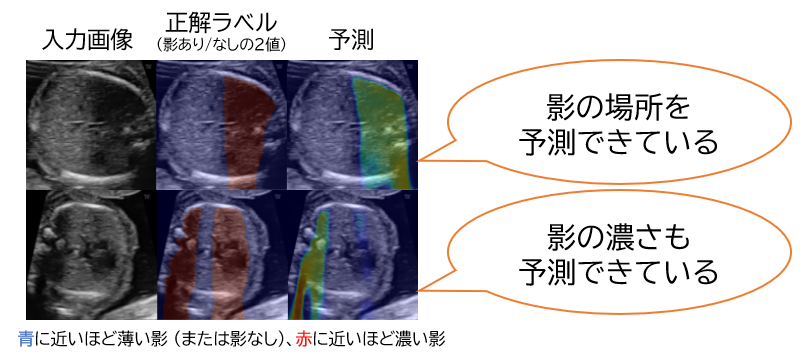
提案手法の適用例は以下の通りです。 音響陰影をよく検出し、検出した部分については影の濃さも概ね推定できている様子が分かります。
手法の詳細や、より多くの実験結果、従来手法との比較については、論文 をご覧ください。
超音波検査動画を活用した胎児心臓の異常検知 (酒井)
先天性心疾患とは新生児の約1%に発症する病気であり、新生児死亡の約20%を占めています。したがって、その早期発見が重要なテーマとなっています。生まれる前に見つけられれば、早期に治療をすることができて、助けられる可能性が高まります。
この本研究では、すべての胎児に対して行われるスクリーン検査(みなさんも月一回うけるやつです。)で得られる超音波動画を対象にして、疾患の早期発見を支援する技術を提案しています。
先天性心疾患は胎児の心臓の構造変化が主な原因となっています。この知見がブレークスルーで、色が変わるとかではなくて構造だけ変化するというのがポイントです。したがって、「正常な構造」の位置と大きさをコンピュータに学習させ、本来「正常な構造」が検出されるべき位置に検出されなかった場合にこれを異常と見なすことができます(詳細は論文を参照)。
部位の検出状況の図はバーコードライクタイムライン図と呼びます。バーコードみたいに検出状況が表示されていることからこういった名前になりました(ちなみにネイティブチェック済み)。
以下の図は正常の場合(a)と異常(b)の場合のそれぞれについて、心臓の部分構造(血管とか心室とかのこと)の検出状況を縦軸に、横軸に断面の位置を表しています。正常の場合では検出されている大血管が異常の場合では検出されていないことがわかります(➃の断面付近)。
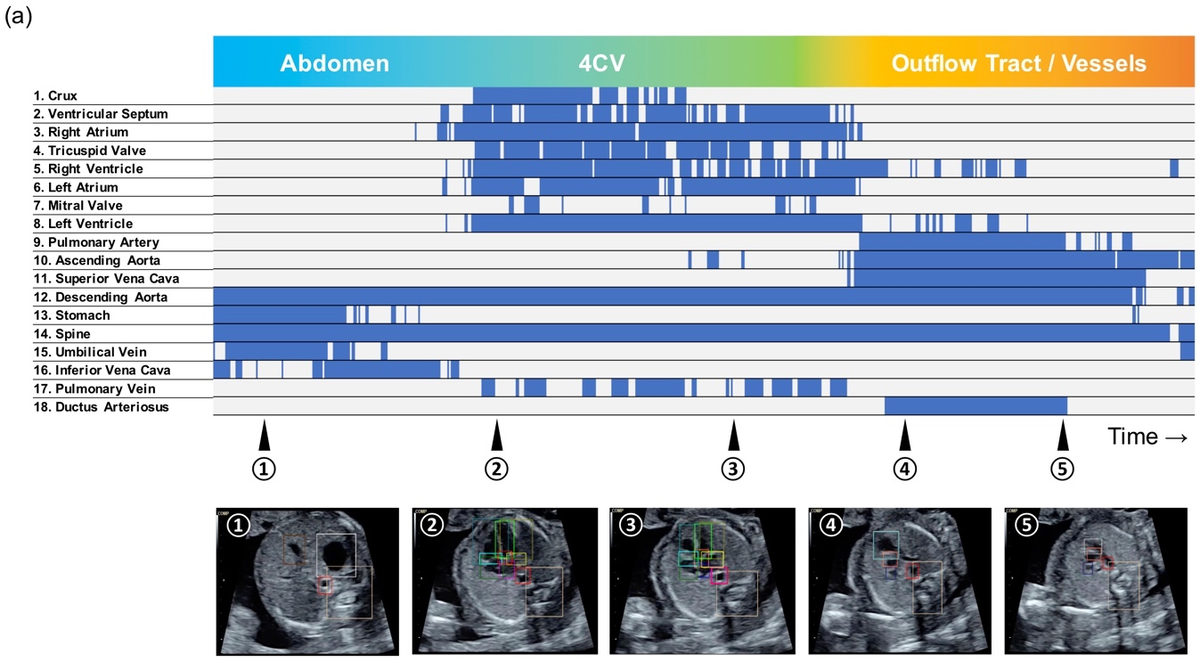
バーコードライクタイムライン図 (正常)
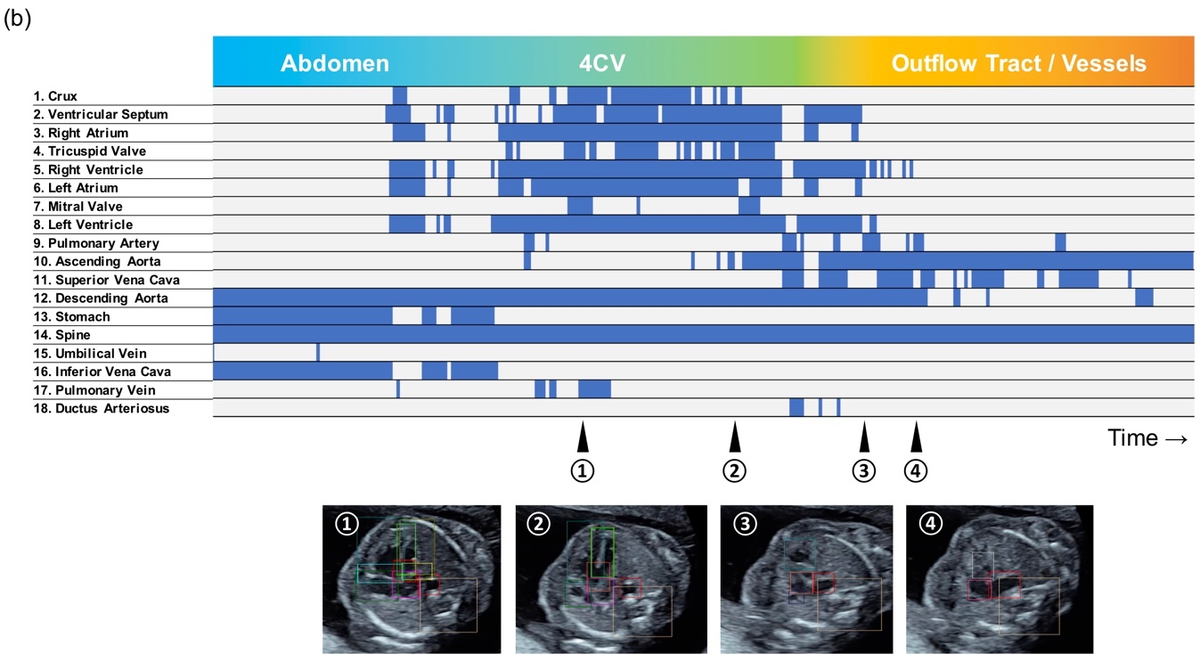
バーコードライクタイムライン図 (異常)
提案手法の性能を検証するために、Barcode like-time line図に対して、単純に部分構造の検出数をカウントすることで正常・異常判定の性能を評価しました。 特に大血管の異常検知については既存手法のRoCカーブのAUCが0.最大値が0.706であったのに対して、提案手法は0.891であり圧倒的でした。これってすごいことです。(自慢w)
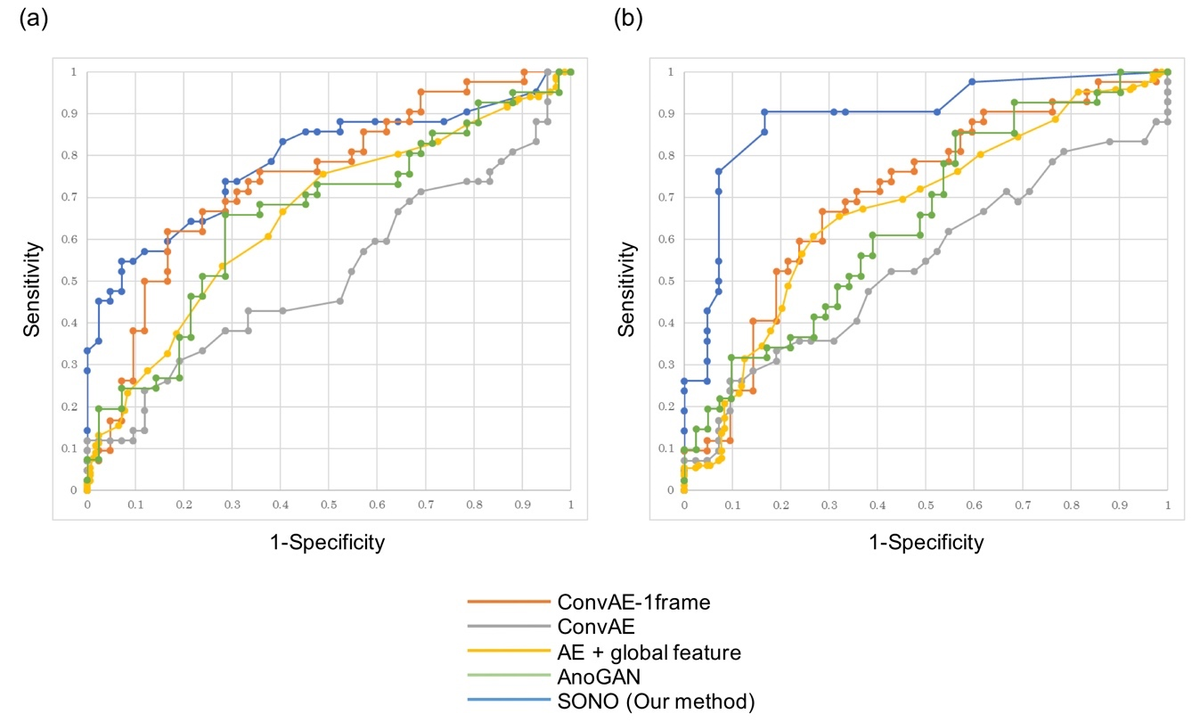
既存手法とのRoCカーブによる性能比較 (左図が心臓付近、右図が大血管付近)
今後は、バーコードライクタイムライン図のより高度な解析手法を開発していき、先天性心疾患の検出率向上を目指していきます。また、本手法では発見困難な疾患(構造の変化が少ない疾患)についても個別にアルゴリズムの研究開発を進めていきます。
胎児心臓の心室中隔のイメージ・セグメンテーション (酒井)
心室中隔は心臓の左心室と右心室を隔てる壁であり、心室中隔欠損はそこに穴が開く病気です。頻度は最も多いのですが、変化が微小であるため検出が困難です。(この変化は数ピクセルです。もう人の目には何がなんだよく分からないです。)
そこで本件研究では正常の心臓の心室中隔を対象にして、心室中隔の位置をピクセル単位で特定する技術であるイメージ・セグメンテーションの性能を高める手法を提案しました。
提案手法では、医療画像で一般によく(もうレジェンド級で)使われているイメージ・セグメンテーションの手法であるU-netの入出力に補正を加えることで既存手法の性能を底上げすることを目指します。提案手法はそれを構成する三つのモジュール(Cropping, Segmentation, Calibration)の頭文字を取ってCSCと呼んでいます(はい、安易なネーミングです。)。
Segmentation moduleはベースとなる既存手法(U-net)を表します。補正を行う各モジュールは以下の2つのアイデアにそれぞれ基づいています。
- Cropping module:検査者が心室中隔を確認する際は、心室中隔の周辺のみの情報を注視することに対応して、心室中隔があると考えられる領域を物体検出で切り出して拡大して入力とする。
- Calibration module:検査者は対象とする画像だけではなく、前後の時間軸の画像も参考にして心室中隔の領域を識別しているということに対応して、前後の画像の情報を考慮して既存手法の出力結果を補正する
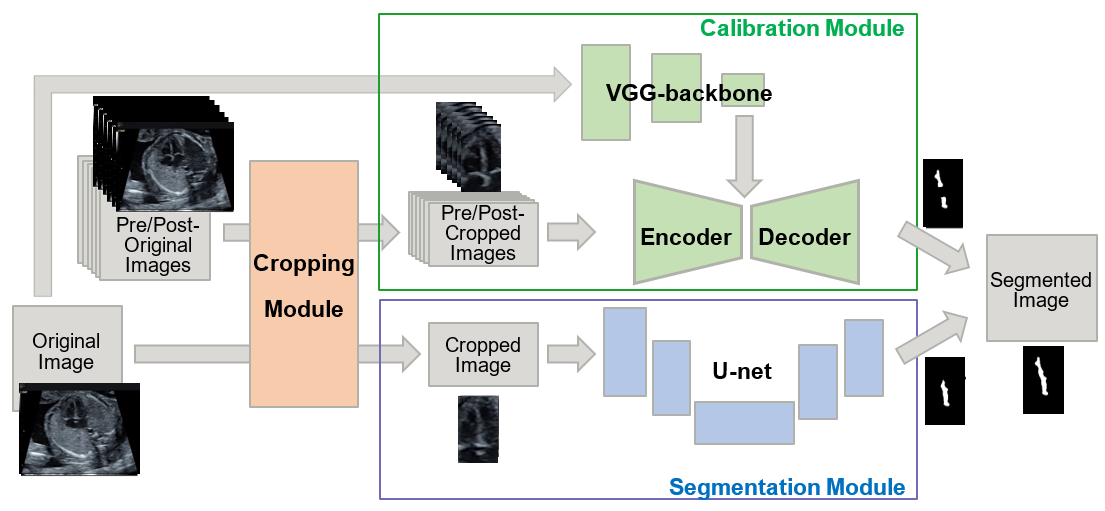
Cropping-Segmentation-Calibration(CSC)法の概念図
数値実験の結果、U-Net単体の場合のセグメンテーションの性能がIoUスコア(正解と予測の重なりぐらいを表す指標です。)で0.1519程度であったのに対して、CSCを適用することで0.5543まで引き上げることに成功しました(論文のTable.1参照)。下記の図が結果を表しています。既存手法(DeepLab v3+やU-net)では塗りすぎたり、まったく映らなくなたりしちゃっていますが、CSCは正解(Ground Truth)とほぼ同じ形状を答えています。
圧倒的じゃないか、わが社の技術は。
また、各モジュールごとの性能の向上の寄与を調べたところ、Cropping Moduleがもっとも大きな効果を発揮していることが分かりました(論文のTable.3参照)。
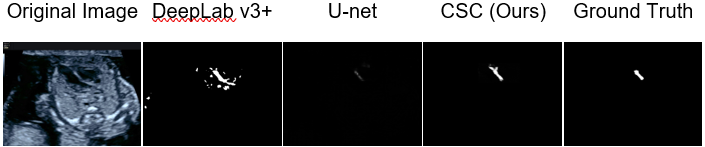
心室中隔の検出結果
今後は心室中隔に欠損を有する症例を集め、心室中隔欠損検知の研究を進めていきます。
胎児の胸郭壁のイメージ・セグメンテーション (酒井)
胎児の胸郭壁は2000人に1人程度の頻度で発症する横隔膜ヘルニアといった疾患で変形を起こします。本研究ではそういった胸郭に変形を起こす疾患の検知を目指して、超音波検査動画を用いて胎児の胸郭壁の領域を正確にピクセル単位でイメージ・セグメンテーションを行う手法を提案しました。
本研究ではイメージ・セグメンテーション技術に一切の工夫を加えることなく、その入出力を変えるだけで性能向上を目指します。なぜならば、画像における深層学習の研究速度が速く、最新の技術を常に適用可能にしておきたいためです。こういった研究は開発技術が時代遅れにならないので重要です。
こういった手法は普通、モデルアグノスティックな手法と呼ばれます。本研究では汎用的に開発されたイメージ・セグメンテーション技術に対して、超音波検査動画の性質や胸郭の構造の特徴を活用して以下の二つのモデルアグノスティックな手法を提案しました。
- Multi-frame Method:この手法では、対象とする画像の前後のフレームの画像を超音波検査動画から取り出します。そうして取り出した複数画像に対してイメージ・セグメンテーションを行い、得られた結果の画像をピクセルごとに平均を取ることで性能を向上させます。
- Cylinder Method:胸郭は常に大きめのペットボトルのような形をしています。つまり、中空で壁に覆われています。本手法ではその性質を活用します。まず、胸郭壁の教師ラベルから胸郭内部および胸郭全体の教師ラベルを生成します(下の図の一行目が胸郭壁、二行目が胸郭内部、三行目が胸郭全体です。)。次にその教師ラベルを用いて、それぞれ学習させます。最後にその結果をピクセルごとに平均を取ることで胸郭壁のセグメンテーションの性能向上を図ります。
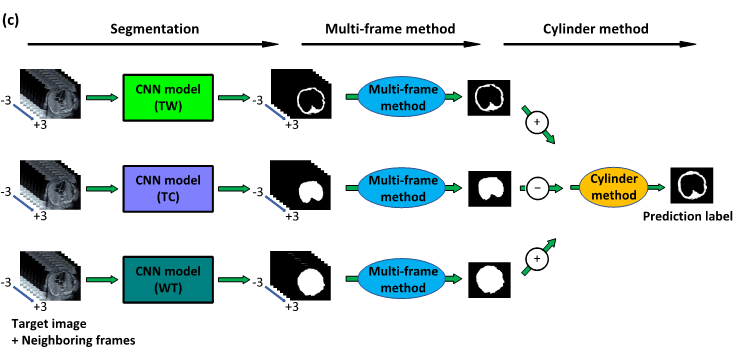
二つの提案手法を適用した場合の図
以下の図はセグメンテーションの結果を既存手法(U-net)と、提案手法を適用した場合とで比較しています。提案手法によってイメージセグメンテーションの性能が向上したことが分かります。数値的にはIoUスコアで0.448であったものが二つの提案手法の適用により、0.493まで向上していることが確認できます(詳細は論文を参照)。 ちなみに二つの手法を組み合わせ方法には頭文字を取ってMFCYという名前をつけています(安易なのばっかりですみません)。 大したことがないように見えるかもしれませんが、どんな既存手法に対しても適用できることがポイントです。

提案手法の結果
今後は胸郭壁に関連する臨床的な指標の自動算出および疾患例に対する検証を行う予定です。
まとめ
今回のブログでは超音波AIの論文を4件ご紹介いたしました。少しでも興味を持ちましたら、ぜひ論文の方も見てみてください。全部オープンアクセスです。
また、もし富士通研究所に興味を持たれた方がいらっしゃいましたら、上司がカジュアル面談を随時募集していますので是非コンタクトしてください!