
こんにちは。富士通研究所トラステッドAIプロジェクトAI倫理チーム所属の中尾悠里と申します。 今回は2021年3月3日-10日にオンラインで行われた国際会議、ACM Conference on Fairness, Accountability, and Transparency (ACM FAccT)をご紹介します。我々のチームからも口頭発表を行いました1。参加メンバーを交えて、FAccTの概要と採択論文、チームメンバーが気になった論文をご紹介します2。
目次
- FAccT'21のご紹介(園田)
- 論文紹介1) Group Fairness: Independence Revisited(園田)
- 論文紹介2) Mitigating Bias in Set Selection with Noisy Protected Attributes(園田)
- 論文紹介3) ☆Our team's paper☆ Biases in Generative Art: A Causal Look from the lens of Art History(Ramya)
- 論文紹介4) Re-imagining Algorithmic Fairness in India and Beyond(Ramya)
- 論文紹介5) Designing Accountable Systems (Beatriz)
- 論文紹介6) Value Cards: An Educational Toolkit for Teaching Social Impacts of Machine Learning through Deliberation (中尾)
まずFAccT'21に日本から参加した園田さんから学会全体の報告と2本、機械学習手法に関する論文の紹介します。園田さんは普段は公平性配慮型機械学習の理論系の研究を行っています。
FAccT'21のご紹介(園田)
こんにちは.富士通研究所人工知能研究所の園田亮介です。富士通研究所では、人工知能(AI)の倫理について、標準化活動や技術開発をしています。この度、AIを含めた情報システムの社会-技術的なトピックを扱うFairness, Accountability, and Transparency 2021 (FAccT’21)に参加致しましたので、その概要を報告します。
FAccTとは
FAccTは計算機協会(Association for Computing Machinery, ACM)によって開かれている、コンピュータサイエンスと社会科学、法学、人文学をまたがる研究分野を議論し、社会技術的(Socio-technical)なシステムを考えていくことを目的とする国際会議です。 AIの社会実装に伴い、我々人間の生活は便利になる一方、AIによるステレオタイプが特定の個人あるいはグループに差別を及ぼす可能性を指摘されています。 もはやAIの倫理を考えることなくしてAIの社会実装は不可能だといわれる中で、FaccTは学術界のみならず産業界からも注目されています。
FAccT'21の構成は次のようになっていました。
- Tutorial
Fairness、 Accountability、 Transparency、 and Ethics (FATE) やコンピュータサイエンス、とりわけAIの分野に関する研究を、初学者にもできるだけわかりやすくプレゼンするセッションです。FAccTは学際的なコミュニティであり、参加者間には、たとえばコンピュータサイエンスの学者と社会科学者の間で専門知識の相違があることが想定されます。また、近年AIとFATEを組み合わせる議論が活発化しており多くの新規参入者が予想されます。 よってこのセッションではコンピュータサイエンスの概念を弁護士、政策立案者、社会科学者、哲学者、および実践者に分かりやすく説明すること、あるいは関連する法的概念を政策立案者、社会科学者、哲学者、およびコンピュータサイエンスの研究者に説明することを目的としています。 「因果推論による公平性分析」、「機械学習の説明性と信頼性」、「産業界における責任あるAI」などFATEにおける最新の取り組みを紹介していました。
- CRAFT
Critiquing and Rethinking Accountability、 Fairness、 and Transparency(CRAFT)は Accountability、 Fairness、 Transparencyの分野に対する批評(例:ギャップがある部分、抜けている部分、より全体論的なアプローチで代替できる可能性等の批評)に貢献すること、研究や協力、実践の将来的な方向性を開くことを目的とするセッションです。インタラクティブな開催となっており、与えられたテーマに対し参加者同士で意見を交わしたりオンラインのホワイトボードに意見を書き込んでいったりする内容です。インタラクティブなため応募は抽選形式となっており、参加人数は1つのテーマにつき10数人に限定されていました。
個人的には、"Narratives and Counternarratives on Data Practices in the Global South"というCRAFTに参加しました。ここでは心理学の文脈で用いられることが多い "icebarg"を用いて、南半球のデータ活用に対し議論をしました。具体的には、南半球の発展途上国、たとえばアフリカのデータ共有エコシステムにおける、ステークホルダーのデータ共有の実践と政策を導く上で影響力について意見を交わしました。ここでの icebarg の絵は、氷山の頂上に位置するステークホルダーが「有利」、氷山の隠れた部分にいるステークホルダーが「不利」という具合に、参加者はどのステークホルダーが、絵のどこに位置するかを議論するために使われました。(たとえば私は、頂上にNGOが、水中に個人のジャーナリストが位置するとコメントしました)

- Panel
複数の有識者が議論を交わし、視聴者は適時内容に対する質問を投稿していく、というセッションです。"Causality, Fairness and its Limitations"というセッションでは最近流行している因果推論による公平性分析の限界について議論を交わしていました。 公平性を考えるうえで保護属性(性別や人種など)と結果の因果関係を考えることは必須ですが、このセッションでは、因果関係を表現するには領域の専門家が必要なこと・保護属性を単純化する必要がある点がネックになっていることが取り上げられていました。特に後者の問題は複雑であり、そもそも男性とは何なのか(出生時に医者が決めるのか)?アジア人であるとは何なのか(肌の色が違うだけなのか、考え方はどう違うのか)?など多数の限界を抱えていることをパネリストは議論していました。
また、最先端の議論なので飛び交う専門用語も多く、参加者のアクセシビリティを高めるため、Realtime textというかなり正確なキャプションが用意されていました。
- Paper
アクセプトされたフルペーパーのプレゼンが行われるセッションです。今年はプレゼン部分は録画済で質疑応答はリアルタイムで行われるという段取りでした。
本会議に関する統計を以下に示します(FAccT 2021 Townhallより引用)。
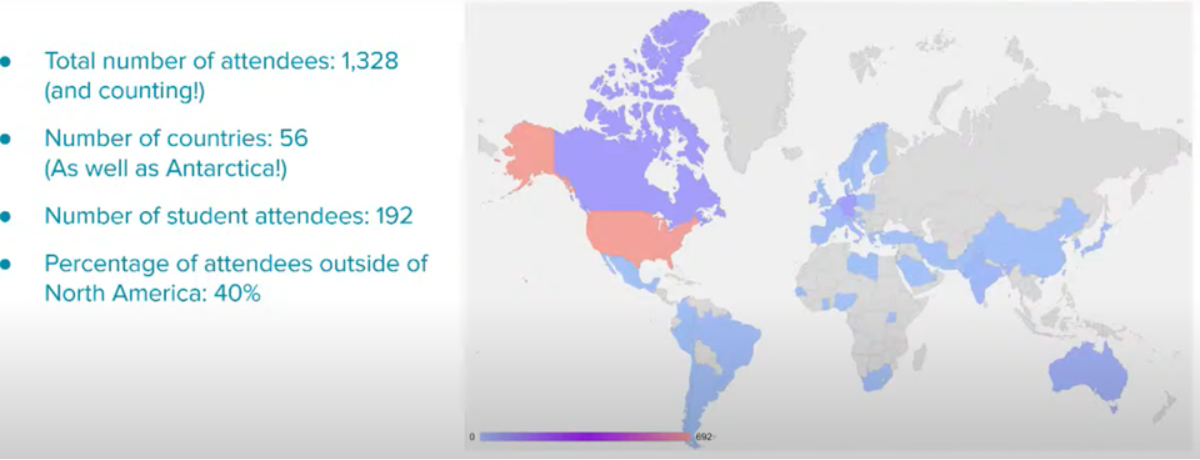
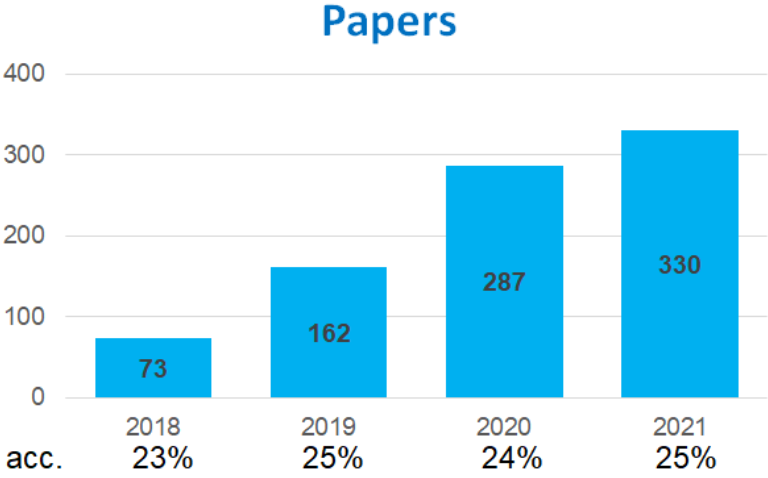
オンライン開催
COVID-19のため、今年のFAccTはオンライン上の開催となりました。そのため参加費用としては会議への参加登録費だけとなり旅費が発生しないというメリットがありました。 さらに、オンライン開催であることを考慮して、参加者はいつでも録画してあるプレゼンをみることが可能であり、その発表に対する質問の事前投稿もチャット上にて可能でした。 (ただし、実際にはCRAFTやPanelへの参加、あるいはリアルタイムの盛り上がりを考慮して私自身は昼夜逆転生活を送っていました。)
なお、FAccTは参加することが困難な環境にいる人への公平分配を考慮して、すべての論文をオープンアクセスにしています。そのため会議に参加できなくとも、気になる研究論文を調査することは可能です。

参加目的
富士通では現在、「Human Centric AI」という理念を基に、人の能力がエンパワーされることを目的にし、「人に信頼され、社会を発展させるAI」の実現に取り組んでいます。 その実現のため、私が所属する富士通研究所のチームではコンピュータサイエンス・社会科学の文脈からAI倫理について考察・社会実装への枠組み提案をしています。 FAccTは人間や社会とAIの接点で生じる問題を広く取り扱っている新興の国際会議なので、Human Centric AIの実現のためには是非とも考慮していきたい領域です。 参加することによって、この領域に関わる外部研究者との交流はもちろん、最先端の研究を知ることでチーム内の知識向上を促進させることが可能だと考えています。
FAccT'21を振り返って
初の FAccT 参加となりましたが、オンライン開催であっても会議の雰囲気を味わえたことが良かったと思います。最先端の研究論文はもちろん、ここではまとめていませんが Tutorial や CRAFT、パネルディスカッションも興味深い内容が多く刺激を受けました。 多くの参加者は、コンピュータサイエンスか人文社会学分野かどちらかのみの専門知識を有していることが多く、今どんな論文を読んでいるのか、専門用語や略語の意味をオンライン上のコミュニティで教えあっていことも多々あり、興味深かったです。オンラインの特性として、それらの交流記録を会話に参加していない他者と共有できるというメリットもあるのかなと感じました。 自分の研究として、AI の差別に関するバイアスを緩和する研究開発をしているため、今回の会議での多くの発表が参考になることを期待します。
発表論文
ここでは、私が気になった論文を2本ほど簡単に要約します。 それぞれの論文は誰でもアクセス可能です。
Group Fairness: Independence Revisited
Tim Räz (University of Zürich) https://doi.org/10.1145/3442188.3445876
サマリー作成者:園田
| 記号 | 意味 | 例:大学入試 |
|---|---|---|
| |
真のラベル(効用) | 合格するに適切か否か |
| |
予測ラベル(効用) | 機械学習による個人の適正予測 |
| |
保護属性 | 個人の性別 |
背景
AIによる再犯予測に関する人種差別が ProPublica によって問題提起されて以来、グループの公平性 Group fairness はコンピュータサイエンスで重要なトピックとなっています。 Group fairness では、入力データ集合をその保護属性(性別、人種、宗教など)に基づいてグループ化するとき、ある公平性評価指標に従って各グループの格差を検証します。 Group fairness における公平性評価指標は次の3つです: independence、 sufficiency、 separation
まず、それぞれの定義と直感的な例を示します。
- independence
independence を満足するとき、が成立します。
これは、予測
は統計的にグループ間で等しい確率を出力することを意味します。大学入試の例でいうと男性と女性それぞれの予測合格者率が等しいことを意味します。
- sufficiency
sufficiency を満足するとき、が成立します。
これは、予測
が与えられたとき、ラベル
が保護属性
に依存していないことを意味します。大学入試の例でいうと、合格であると予測され、実際に合格だった確率が男性と女性の間で等しいことを意味します。
- separation
separation を満足するとき、が成立します。
これは、ラベル
が与えられたとき、予測
が保護属性
に依存していないことを意味します。大学入試の例でいうと、実際の合格者に対し、合格すると予測される確率が男性と女性で等しいことを意味します。
これら公平性評価指標に対し、どれが公平性の概念として適しているのか、についていくつかの研究で議論されています。 その中でも、independence に対して批判をする研究が比較的多いため、ここではそれらの批判が妥当かを検証していきます。
既存研究
多くの既存研究では、3つの group fairness のうち independence が不適切な公平性評価指標であると主張しています。それら既存研究は、主に2つの論文による2つの主張を基に批判を展開しています。そこで、ここではその2つの論文による independece に対する2つの否定的な主張をまとめます。
- independence は individual fairness を侵略する [Dwork et al., 2012]
これは、independence を満足させようとすると、各グループに属する個人が不公平な扱いを受けてしまう、という問題を指摘する内容です。ここで、individual fairness は 「類似する特徴をもつ個人は類似する扱いを受けるべき」 と定義されます。つまり予測が類似する特徴を持つ個人間で類似する必要があります。しかし、下図のように Group A、B 間の independence を満足することにより、類似する個人間で予測
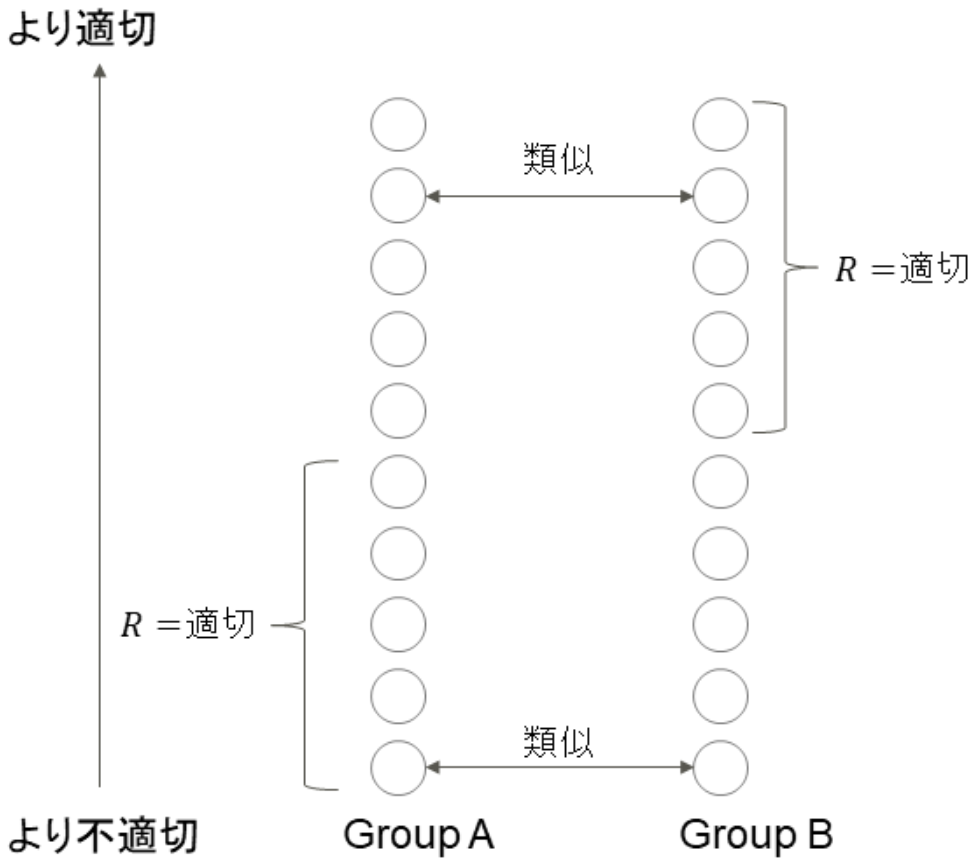
Indipendenceを満足する公平な予測のイメージ - independence はラベル
を考慮していない [Hardt et al., 2016]
independence の定義式をみると、ラベル
本研究の概要
結論からいうと、independence に限らず seperation や sufficiency も同じ2つの問題を孕んでいるよという主張です。簡単に主張を紹介します。
1つ目の、individual fairness を侵略する問題は、independence に限らない議論です。下図は separation を満足していますが、individual fairness を犠牲にしていることが分かります。
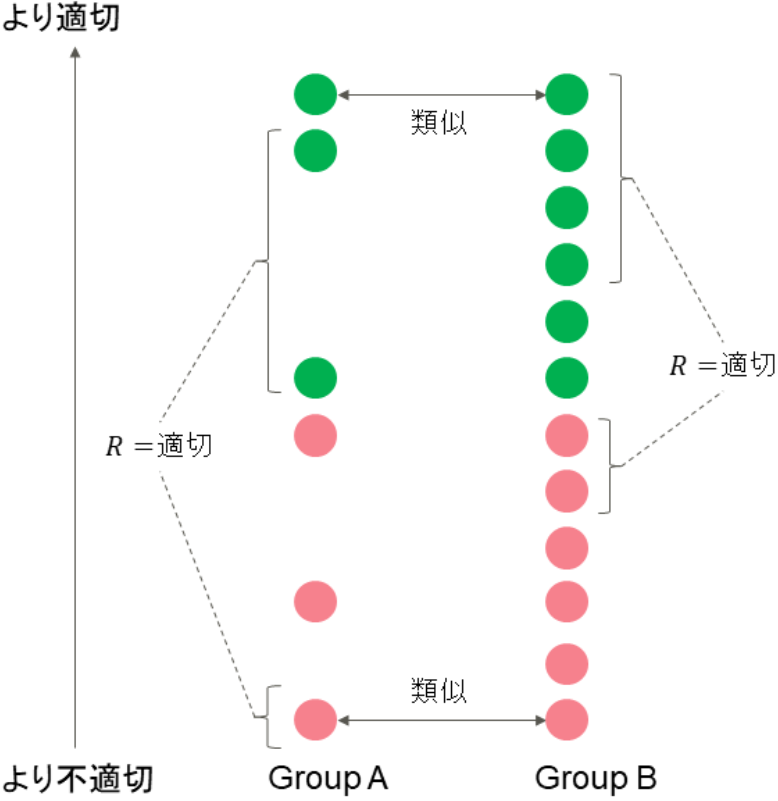
2つ目の、ラベルを考慮していないという問題は、そもそもラベル
が bias を含んでいるという反論ができます。観測されるラベル
と保護属性
の同時分布
は道徳的ではなく、それらは不公平なプロセスか歴史的なバイアスによって発生した可能性が十分にあるという主張です。たとえば、男性の大学合格確率
が女性より歴史的に遥かに大きい場合、公平性評価指標で
を用いることは適切だといえるでしょうか?
以上の内容を踏まえて、どの group fairness も完全に公平性を満足させることはできず、実践的にはデータやモデルの使用用途などに依存して公平性評価指標を選択するべきです。またその際、「道徳的価値」を明確に述べる必要があります。
結論
まとめると、本研究の主張としては
- 公平性評価指標を選択する際、道徳的価値を述べるべき
- individual fairness を犠牲にするのはすべての group fairness に共通する問題。可能性のある解決策としては individual fairness と group fairness を組み合わせる方法である
- 公平性評価指標の選択はコンテキストの規範に依存する
- どの公平性評価指標も「公平性」を満足することはできない
Mitigating Bias in Set Selection with Noisy Protected Attributes
Anay Mehrotra, L. Elisa Celis (Yale University) https://doi.org/10.1145/3442188.3445887
サマリー作成者:園田
| 記号 | 意味 |
|---|---|
| |
選択された部分集合. |
| |
アイテム |
| |
アイテム |
| |
|
| |
|
| |
背景
subset selection 問題は、オンラインの job portals(アルゴリズムが採用担当者に表示する候補者を subset に入れる)、大学入学(教員が入学許可する学生の subset を選考する)、オンライン検索(プラットフォームがユーザークエリへの応答になる subset を選択する)など、さまざまな状況で発生します。
問題定義としては次のようになります:入力として個のアイテムがあり、各アイテム
は
の効用を持ちます。モデルは入力から
個の subset を選択し、出力します。目標は、subset に含まれるアイテムの効用の合計を最大化させることです。画像検索の例でいうと、トップに表示される画像集合の、クエリに対する関連度の合計値を評価します。
subset selection での保護グループの差別を是正する必要性は今までも議論されていました。たとえばある検索エンジンで「社長」と画像検索してみると、高齢男性の画像ばかりが検索結果上位に表示されます。これは入力の画像データ集合に含まれる年齢や性別のバイアスをモデルが学習してしまうことが1つの原因として考えられます。このように、入力データ集合に含まれる social bias を考慮しないモデルは特定グループに対し不公平な振る舞いをします。そのため、既存の公平性に配慮する機械学習では入力データの social bias を、保護属性を用いて考慮するアルゴリズムを提案することで、公平性と効用のトレードオフを達成しようとします。

しかし、もし入力データに保護属性に関する情報がなかったらこれらの手法はどう対応するでしょう?これは現実的な問題設定であり、たとえば一般に画像のアノテーションにはコストがかかるため、保護属性は事前に決定されていません。 またプライバシー保護の観点から保護属性に関する情報がない場合もあります。
このような場合、保護属性を代入処理することが1つの解決策として考えられます。代入処理として、機械学習(ロジスティック回帰やニューラルネットワークなど)を用いて入力データの保護属性を推定し、それで代替するという単純な方法があります。 しかし、元の入力データ集合に bias が存在することを考慮すると、推定された保護属性はノイズを含む可能性があります。 ノイズを含んだ保護属性を基に公平性を計算すると、誤った是正をする確率が高いです。 本研究ではこのように推定された保護属性がノイズを含んでおり、真の保護属性と剥離している場合の fair subset selection を取り扱います。
評価指標
モデルの評価指標は、モデルが出力する subset の効用と公平性の2つになります。
subset に含まれるアイテムの効用の合計を
とすると
- 効用
ここで、は理想的な
であり、精度を
から
までに正規化するための変数です。
のとき、subset の効用は理想的であるとします。
- 公平性
ここで、 は subset
内において、最も多いグループの数と最も少ないグループの数の差を表しています。これが
のとき、すなわち
のとき、その subset の公平性は理想的であるとします。
問題設定
上記2つの評価指標を同時に最適化することを考慮すると、次のような最適化式を設定できます。
subset に含まれるアイテムの効用の合計
を最大化させつつ、
に含まれるグループ
の数
、
の大きさ
に関する制約を満たすような最適化式:
ここで、に含まれるべき
の最小数
、含むことができる最大数
、
の大きさ
の値はそれぞれ入力として与えられます。
上記式は、モデルが3つの制約条件
の中で subset に含まれる効用の合計
を最大化することを目標とすることを意味します。
提案手法
本研究では、何らかの機械学習手法により推定された保護属性にノイズが含まれ、観測できない真の保護属性
が存在すると仮定します。すると、次のようなノイズモデル
を設定できます
アイテムに関して
と特徴
が与えられると真の保護属性
を考慮できるということです。
これを用いて、提案手法では観測される
に基づくグループ
の代わりにノイズモデル
を最適化式の制約項に代入します。
ここで、は公平性制約に対する微少の許容量です。この微小量は、現実あるいは理論上でも不公平性を
にすることは困難であることから発生します。
上記式を単純に解くとNP-hard(現実的に解くことが困難なほど複雑)なので、近似して線形計画法という単純な数学的手法により解きます。
実験
- データ
Google の"occupation"クエリの画像検索結果上位100のデータを用います。それぞれの画像は真の性別ラベルを所有しています。実験では Convolutional Neural Network という機械学習手法により推定される画像の性別を保護属性として訓練データに含みます。一方、テストデータでは画像の真の性別ラベルが含まれます。subset selection を解く手法を、訓練データによって訓練した後、テストデータを用いて精度と公平性を評価します。 - 手法
ノイズを考慮しない既存手法とノイズを考慮する提案手法FairExpec(*) - 結果
垂直軸が精度に関する指標(大きいほど良い)、水平軸が公平性に関する指標(大きいほど良い)です。図の見方としては、右上に位置するほど精度と公平性のトレードオフが良いといえそうです。
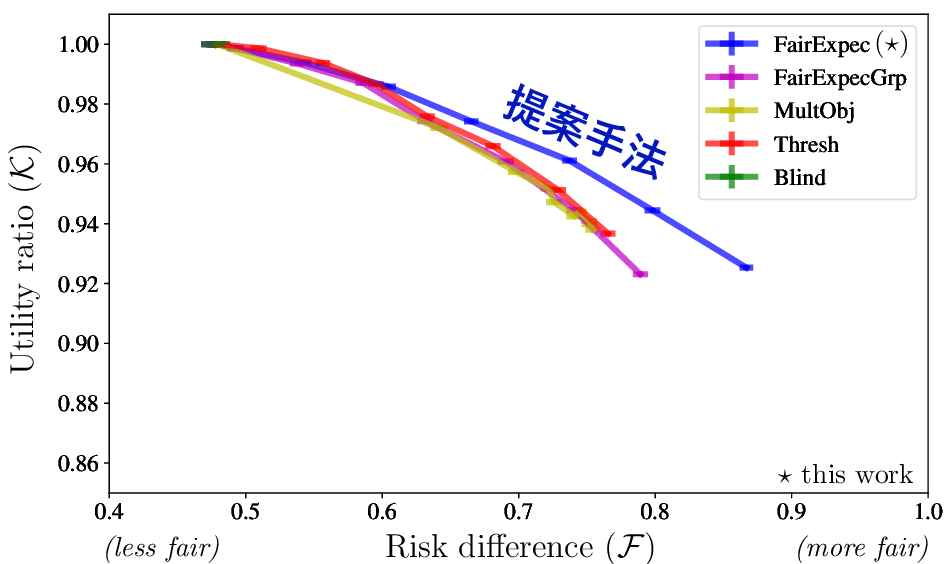
図を見ると、提案手法(青)は比較手法に対し、精度と公平性のトレードオフを達成することができ、良い公平性を維持することができています。
結論
欠損した保護属性を推定し、それを訓練データに用いる場合、現実世界のノイズをアルゴリズムで考慮することは重要で、 そうしないと意図しない悪影響が発生する可能性がある、という主張です。
続いて、Fujitsu Laboratories of Americaで研究を行っているRamyaさんに、今回FAccTに採択されて口頭発表を行った論文、Ramyaさんのルーツであるインドにおけるアルゴリズムの公平性に関する発表をシェア頂きます。
Biases in Generative Art: A Causal Look from the lens of Art History
Ramya Srinivasan, Kanji Uchino (Fujitsu Laboratories of America) https://dl.acm.org/doi/abs/10.1145/3442188.3445869
サマリー作成者:Ramya
研究の動機
近年、ジェネレーティブ・アート3のツールに関連した人種的バイアスの記事が出されたのですが、私はジェネレーティブ・アートには他のタイプのバイアスも生じるのではないかという疑問を抱いていました。この思いがジェネレーティブ・アートツールと学術論文の調査につながり、プロジェクト開始のきっかけとなりました!

論文の概要
本論文では、ジェネレーティブ・アートに含まれるバイアスについて、不適切な問題設定に起因するものからアルゴリズム設計に関連するものまで、様々なタイプのものを調査しています。分析のために、AIを使ってアートを生成する事に関する学術論文、オンラインプラットフォーム、アプリなどを調査しました。更に、美術史的な観点から潜在的なバイアスを明らかにするため、調査したリスト、論文、プラットフォームの中から、確立された芸術運動のスタイルまたは芸術家のスタイルであるものシミュレートすることに焦点を置いたものを選びました。ケーススタディで扱っている芸術運動は、これらの最先端のAIモデルやプラットフォームで報告されている実験設定に基づいて決定されています。芸術運動には、ルネッサンス芸術、近代芸術(キュビズム、未来派、印象派、表現主義、ポスト印象派、ロマン派)そして浮世絵が含まれます。
研究対象のモデルは、有向非環状グラフ(directed acyclic graphs, DAGs)を用いて表現されました。DAGは、ドメイン固有の知識を取り入れることで、アート制作のプロセスをアクセス可能かつ理解しやすい形で視覚化します。風景画や戦場を描いた絵画などのジャンルを含むケーススタディでは、選択バイアス、トランスポータビリティバイアス4 、ラベルバイアス、表現バイアス、問題設定バイアスなど、様々なタイプのバイアスが示されています。DAGsを用いて、アーティストのステレオタイプを含むジェネレーティブ・アートに関連するバイアスを明らかにしています。
ジェネレイティブ・アートに関連するすべてのバイアスを排除することは不可能かもしれませんが、このような悪影響を最小限に抑えるための下記の様なガイドラインを提案します:
- システムの開発、展開を形成する社会・政治的文脈を理解する。
- システムの展開の前にツールの社会文化的な影響を調査する。
- アルゴリズムが特定の問題(例えば、ア―ティストのスタイルをモデル化できるか、など)を解決できるかを問う。
- 信頼性の高いラベルがついた十分に代表的なデータセットの作成。
- 悪い結果に対する責任を誰が負うべきかなどの、生成されたアートのアカウンタビリティに関するガイドラインの定義。
- 芸術創造のプロセスについての情報をよりよく伝えるために、領域の専門家(例:美術史家)をジェネレーティブ・アートのパイプラインに参加させる。
- 研究者とモデルの開発者の間のコミュニケーションを円滑にするための、生成モデルの詳細の説明。
口頭発表後のフィードバック/感想
ライブQAセッションでは、興味深い質問がいくつか寄せられました。例えば、「合成データを生成するメソッドの文脈においてこのようなバイアスはどのように扱われるべきか」「バイアスを発見する際の因果モデルの利点は何か」「アーティストのバイアスの問題にはどのように対処されるべきか」などがありました。この研究に感銘を受けたGoogle Ethical AIチームの一人に、2021年に開催されるCVPRワークショップ「Ethical Considerations in Creative Applications of Computer Vision」でこの論文を発表するように招待して頂きました。
Re-imagining Algorithmic Fairness in India and Beyond
Nithya Sambasivan, Erin Arnesen, Ben Hutchinson, Tulsee Doshi, Vinodkumar Prabhakaran (Google Research Mountain View) https://dl.acm.org/doi/10.1145/3442188.3445896
サマリー作成者:Ramya
論文の概要
本論文で著者らは、インドのAIランドスケープに焦点を当てることで、西欧中心のフェアネスの視点を脱中心化することを提案しています。 36人のインタビュイーに対する質的インタビューとアルゴリズムの展開に関するディスコース分析に基づいて、著者らはアルゴリズムの公平性に関する既存の定義の限界を示します。
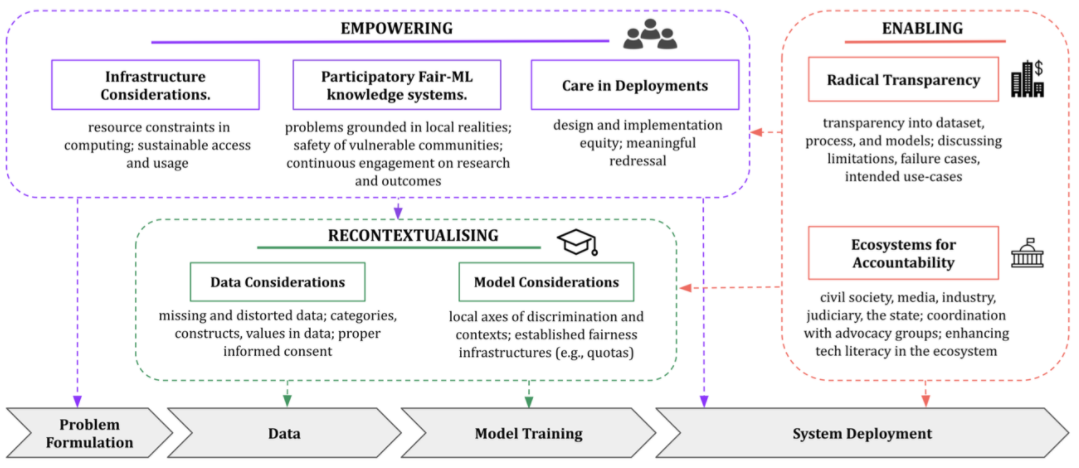
まず、インドでは、社会経済的な要因により、データが必ずしも信頼できるものではないと著者らは主張します。インドのインフラと社会契約の在り方は、データセットが人々や現象を忠実に表現している、という前提自体に疑問を投げかけています。また、カースト、ジェンダー、宗教などのサブグループでは、異なる公平性の実装が必要となりますが、インドのAIシステムでは、このようなバイアスの分析が十分に行われていません。インドのユーザーは、救済の機会がほとんど、あるいは全くないような「底辺の10億人 (bottom billion)」のデータ主体としてしばしば認識されています。そのため、プライバシーを妨げ、個人やコミュニティの価値観を尊重しない押しつけがましいモデルにさらされているのです。著者らは、AIに対して疑問を投げかけるためのツール、ポリシー、ステークホルダーのエコシステムがないことが、インドにおける有意義な公平性を妨げると述べています。
そして著者らは、インドにおけるアルゴリズムの公平性を「re-imagining(再構想)」するためのいくつかのポイントを提案しています。著者らは、意味のあるインフラを構築するために、データセットとモデル、知識体系や司法の体系、そしてーこれが最も重要なものですがー抑圧されたコミュニティなど、アルゴリズムに影響を与えるエンド・ツー・エンドの要因に関わっていくことを、公平性を対象とする研究者に強く促しています。具体的には、データとモデルの公平性を再文脈化すること、抑圧されたコミュニティに参加型の行動でエンパワーすること、意味のある公平性のためのエコシステムを実現することを呼びかけています。
続いてスペインのFujitsu Laboratories of Europeにて研究を行っているBeatrizさんにアカウンタブルなシステムの設計に関する論文を共有いただきます。Beatrizさんはアカウンタブルなシステムについて研究を続けています。今回は、アカウンタブルなシステムの設計に関する論文を共有してもらいます。
Designing Accountable Systems
Severin Kacianka, Alexander Pretschner (Technical University of Munich) https://dl.acm.org/doi/10.1145/3442188.3445905
サマリー作成者:Beatriz
論文の概要
機械学習の汎化性能の向上や公平性の分析のためなどの目的で、人工知能(AI)の領域で因果(Causality)の人気が高まっています。Designing Accountable Systemsと題されたこの論文では、ミュンヘン工科大学(Technical University of Munich, TUM)の著者らが、アカウンタビリティの分野における構造的因果モデル(Structural Causal Models, SCM)の新たな応用を模索しています。
著者らが述べているように、現在、アカウンタビリティには複数の意味があり、その定義は曖昧です。既存研究では、アカウンタビリティの意味をなんらか定義し、特定の文脈における解決策を提案することに重点が置かれてきました。本論文では、互いに影響を及ぼし合う因果関係の一連の変数としてアカウンタビリティを表現するために、アカウンタビリティの主な定義をレビューし、再考しました。
アカウンタブルなシステムを設計するために、この論文の著者らは社会技術システムの正確なSCMが提供され、因果に関する問いに答えることができる、という状況を想定しています。しかし、システムをアカウンタブルにするためには、このSCMが、特定のアカウンタビリティの定義に基づく因果モデルに従う必要があります。本稿では、2018年に起きたウーバーの自動車の死亡事故を例に、この、特定のアカウンタビリティの定義に基づいた因果モデルを利用する方法をどのように適用するかの分析を行っています。
分析の結果として、著者らは因果はアカウンタビリティに必要であるが、それだけでは十分ではないと結論づけています。SCMは、システムを分析し、改善するための強力なツールであり、アカウンタビリティの概念を理解するために不可欠なものです。このような利点があるにもかかわらず、システムのSCMをどのように定義し、開発するか、あるいは特定の効果に対して誰が責任を負うのかをどのように特定するかなど、関連する重要な課題が依然として残されています。
最後に、中尾から多様なステークホルダーについて意識しながら機械学習の概念を学習していくツールについてご紹介します。中尾は人々とのワークショップや、システムのUX調査を通じて人々が公平だと感じるシステムについて探求しています。
Value Cards: An Educational Toolkit for Teaching Social Impacts of Machine Learning through Deliberation
Hong Shen1, Wesley H Deng2, Aditi Chattopadhyay1, Zhiwei Steven Wu1, Xu Wang3, Haiyi Zhu1 (1 Carnegie Mellon University, 2 University of California, Berkeley, 3 University of Michigan Ann Arbor) https://dl.acm.org/doi/abs/10.1145/3442188.3445971
サマリー作成者:中尾
概要
カーネギーメロン大学のコンピュータサイエンスの授業で、62名の学生を対象に行われた授業中のワークショップの研究です。Model Cards, Persona Cards, Checklist Cardsという三種類計13枚のカードを用意し、学生に議論してもらいます。このカードのセットを著者らはValue Cards Toolkitと呼んでいます。学生たちは、AIを用いた再犯予測のトピックについて議論し、最もよいと思われるアルゴリズムとその理由、あるいは合意に達することができなければその理由を政策決定者にサジェストする、というタスクを課されています。 この研究では、下の三つの目的についてValue Cardsの効果があったかを見ています。
- 目的1. 機械学習の技術的な定義とパフォーマンスメトリクスのトレードオフを理解し、実社会の文脈に適用できるか
- 目的2. 機械学習システムを開発・実装する際に多様なステークホルダーの観点を考える重要性を理解するか
- 目的3. アルゴリズムの決定が最終的な影響を持つ際の多様なステークホルダーの観点をコミュニケートし、交渉し、統合することができるか
一つ目は授業前後に問題を出し正解しているかを調査、二つ目と三つ目に関しては最終的な提案と授業後の質問などから明らかにしています。参加者はグループに分けられ、Persona Cardsの有無、Checklist Cardsの有無の4タイプのグルーピングがされ、対照実験が行われます。

Value Cards Toolkitの紹介
Value Cards Toolkit は次の3種類のカードセットからなるツールキットです。
Model Cards 機械学習メソッドの説明を書いたカードです。1枚ごとに一つの機械学習モデルの説明が全体と、特定の属性のグループに対するパフォーマンスのメトリクスが書かれています。このカードは異なるメトリクスのトレードオフがつかめるように作られており、具体的にはaccuracy, false postive rate, false negative rateについて、全体、及びアフリカ系アメリカ人と白人の被疑者に対する評価の差が書かれています。
Persona Cards 再犯予測のデータ分析に関する潜在的なステークホルダーの情報を書いたカードです。判事、被疑者、コミュニティのメンバー、公平性の唱道者(NPO団体のようなイメージです)が、それぞれどのようなメトリクスの向上を望んでいるか(例えば地域コミュニティのメンバーはコミュニティの安全を高めるため、偽陽性を下げることを望む、など)、彼らの課題、どのように他のステークホルダーとの生産的な議論を行うかのガイドラインが書かれています。
The Checklist Cards 議論の中で考えるべき事柄のチェックリストを提供します。チェックリストは次の三つです。
- AIの社会的価値の理解:AIシステムの社会的影響を考える上でのハイレベルなポイントを提示。
- ステークホルダーの特定:誰が影響を受けるリスクがあるのかを考える出発点を提示。
- 影響の分析:社会的な影響の種類、程度、規模、方向性を特定することを求めます。
結果
- 目的1 [機械学習に対する理解]: 授業の前後で理解度テストを実施したところ、クイズの点数が有意に上昇。社会的な意義を示すことでメトリクスなどをより身近に学習できました。
- 目的2 [多様なステークホルダーの考慮]: 授業の前後でパフォーマンスを測るメトリクスに関する質問。授業後に提示されたメトリクスの数が有意に増加。質的な調査からも、学生たちは機械学習のシステムを開発する際に多様な社会的価値を考えることの重要性に気づき始めました。
- 目的3 [多様な観点に関するコミュニケーション]: 学生たちはステークホルダーの関心を主張しつつ、思考し、交渉し合っていた。14チーム中4チームが合意に至らなかった。合意に至らないグループでも熟考した結果が反映された提案がなされました。
その他の効果
- Persona Cards: 目標を達成できたが、情報がそぎ落とされているため本当にそのステークホルダーの立場に立ちにくい、また、ペルソナに書かれた立場に固執し他のペルソナのことを考えないという姿勢を誘発するケースもみられました。
- Checklist Cards: 議論の足掛かりとはなったが、内容が詳細すぎて書かれた内容について議論している時間がない、などの問題があった。早期の段階でこのカードを示したほうがいい可能性があります。
おわりに
今回はFAccT'21の参加報告と、我々のチームから発表された論文を含めた計6本の論文を紹介しました。FAccTでは、人工知能やITシステムの公平性、アカウンタビリティ、透明性に関する工学的な理論、法律、社会調査、教育の実践など、多岐にわたる論文が発表されています。もし興味を持たれた方は、是非一度学会のプロシーディングスを覗いてみてください!
この記事に興味を持たれた方は、AI倫理チームコンタクトライン:labs-ai-ethics-info@dl.jp.fujitsu.com までご連絡ください。
- ヘッダー画像は学会ウェブサイトから引用。↩
- 海外メンバーの紹介記事の翻訳は全て中尾が担当しています。翻訳の際に生じた問題の一切は中尾に責任があります。↩
- 人工知能技術などの自律的なシステムを用いて全体または部分的に制作されたアートのこと。参考:Generative art (Wikipedia 英語版) https://en.wikipedia.org/wiki/Generative_art↩
- ある特定の領域のデータについて作られた因果モデルが、その因果が適用できない新しい領域のデータに対して適用されてしまい、元のデータに含まれていたバイアスが新しい領域のデータに基づく結果に反映されてしまう事。↩