こんにちは。富士通株式会社研究本部ソーシャルデジタルツインPJのmacです。
私たちの部署では、社会課題を解決するデジタルツインシステムの研究開発を行っています。社会課題の解決を目的としたシステムには高い可用性が求められます。というわけで、今回はKubernetesを利用したクラウドサービスの可用性向上のお話です。
クラウドサービスの可用性向上
サービスの可用性を高める技術にはさまざまなものがありますが、オンプレでもクラウドサービスでも、機能を分散して冗長に配備することで実現するのが一般的です。特に、クラウドサービスでにはリージョンやゾーンといったオンプレにはなかった機能配備の領域定義があり、こういった領域定義を考慮に入れることで可用性を向上させることができます。
多くのクラウドベンダーは、サービスノードをサービス提供に適切な地域に配備してサービスを提供しています。この地域をリージョンといいます。それぞれのリージョンは互いに依存せずにサービス提供できるように設計されているのが一般的です。また、リージョンは複数のゾーンで構成されています。これらのゾーンも互いに依存せずにサービス提供できるように設計されています。こういったクラウドベンダーのサービス上に新たなサービスを構築する際に、複数のゾーンにわたって機能を分散・冗長配備することで、一部のゾーンが障害で利用できなくなっても他のゾーンがそれを補うように動くので、サービス提供を継続させることができるようになります。
今回は、Kubernetesでのゾーン障害対策の設定例をAWS EKSを例にあげて紹介します。
Kubernetesにおけるゾーン障害対策
Kubernetesには、Affinity、AntiAffinityと呼ばれる仕組みが導入されています。これは、Podの配備に対して、Nodeに対する条件(Node Affinity)や他のPodに対する条件(Inter-Pod Affinity)を設定する仕組みで、これを使うことで、このPodは必ずこのNodeに配備する、このPodとあのPodは必ず別々のNodeに配備する、といった条件を設定することができます。
Affinityに関してはさまざまなドキュメントがすでにあるのでここで言及はしませんが、Affinityを使うことでも、超絶がんばれば、ゾーン毎に均等に配備するような条件を書くことがきっとできるでしょう。しかし、もっと簡単に書けます。それが、Pod Topology Spread Constraints の仕組みです。
Pod Topology Spread Constraints
Pod Topology Spread Constraintsは、各Nodeに設定されたラベルに基づいたNode群を定義し、このNode群に対してPodを拡散配備させる仕組みです。Node群をゾーン毎と定義することで、各ゾーンに拡散させることができるわけです。
具体的に、Pod Topology Spread Constraintsの設定を見てみましょう。Pod Topology Spread ConstraintsはPodのspecとして記述します。記述する内容は以下の4点になります。
- topologyKey: Node群を定義するためのラベルのKey、このラベルに書かれているValueが同じものを1つのNode群として扱う
- maxSkew: 許容される配備数の差、配備数ではなく、配備数の差になることに注意
- labelSelector: 配備数をカウントする対象となるPodの指定、labelSelectorで指定する
- whenUnsatisfiable: 条件が満たされなかった時の挙動、満たされない時は配備しない(DoNotSchedule)か、適当 ^^; に配備する(ScheduleAnyway)かを設定する
まずはkubernets.ioのドキュメント (https://kubernetes.io/docs/concepts/workloads/pods/pod-topology-spread-constraints/ より) にある例に沿って、どのように動作するかを理解しようと思います。
ドキュメントには下記のような設定例が載っています。この設定をapplyすると、Nodeに設定されている zone ラベルの値ごとに、foo: bar のラベルがついたPod数をカウントした上で、それらのカウントの最大値と最小値の差(maxSkew)が1に収まるような配備が行われます。
kind: Pod apiVersion: v1 metadata: name: mypod labels: foo: bar spec: topologySpreadConstraints: - maxSkew: 1 topologyKey: zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: foo: bar containers: - name: pause image: k8s.gcr.io/pause:3.1
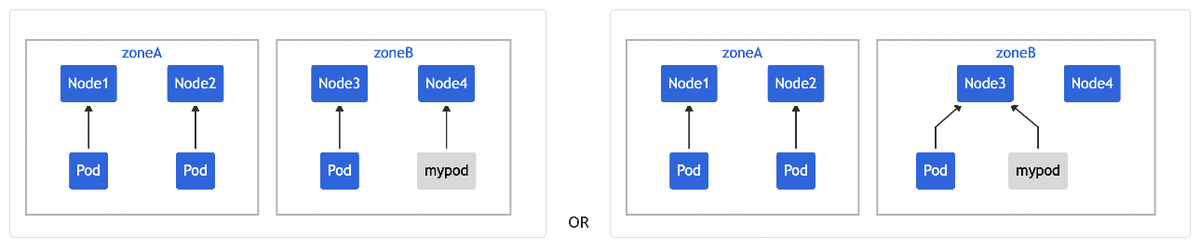
例えば、zone: zoneA と zone: zoneB と言うラベルがついたNodeが2つづあり、mypodと同様の foo: bar のラベルがついたPodが3つ配備されていたとします。
この状態では、上記のlabelSelectorにマッチするPodはzoneAのNode群に2つ、zoneBのNode群に1つ配備されていることになります。ここで上記のファイルでmypodを配備しようとすると、
- zoneAのNodeに配備: zoneAに3つ、zoneBに1つ配備されることになり、
maxSkew: 1を満たせない - zoneBのNodeに配備: zoneAに2つ、zoneBに2つ配備されることになり、
maxSkew: 1を満たす
となるため、zoneBのNodeに配備されることになります。ここで、zoneBのNode3かNode4のどちらに配備することになるかは、この条件では言及していないことに注意してください。zone: zoneB と言うラベルのついたNodeに配備する、という動きになります。
AWS EKSでの動作検証
実際にクラウドサービス上で確認して見ます。今回はAWSのKubernetesマネージドサービスであるEKSを利用して確認します。
まず、eksctl を使ってEKSクラスターを生成します。今回は、東京リージョン(ap-northeast-1)の 3AZ(ap-northeast-1[acd])に2つづつ、合計6つのNodeが配備されるようなクラスターを生成しました。(AWSではゾーンをアベイラビリティゾーン、AZと言っているので、本記事でも以降はAZと記述します。)
$ eksctl create cluster --name mac-exp --nodes 6 --node-type t3.micro --region ap-northeast-1
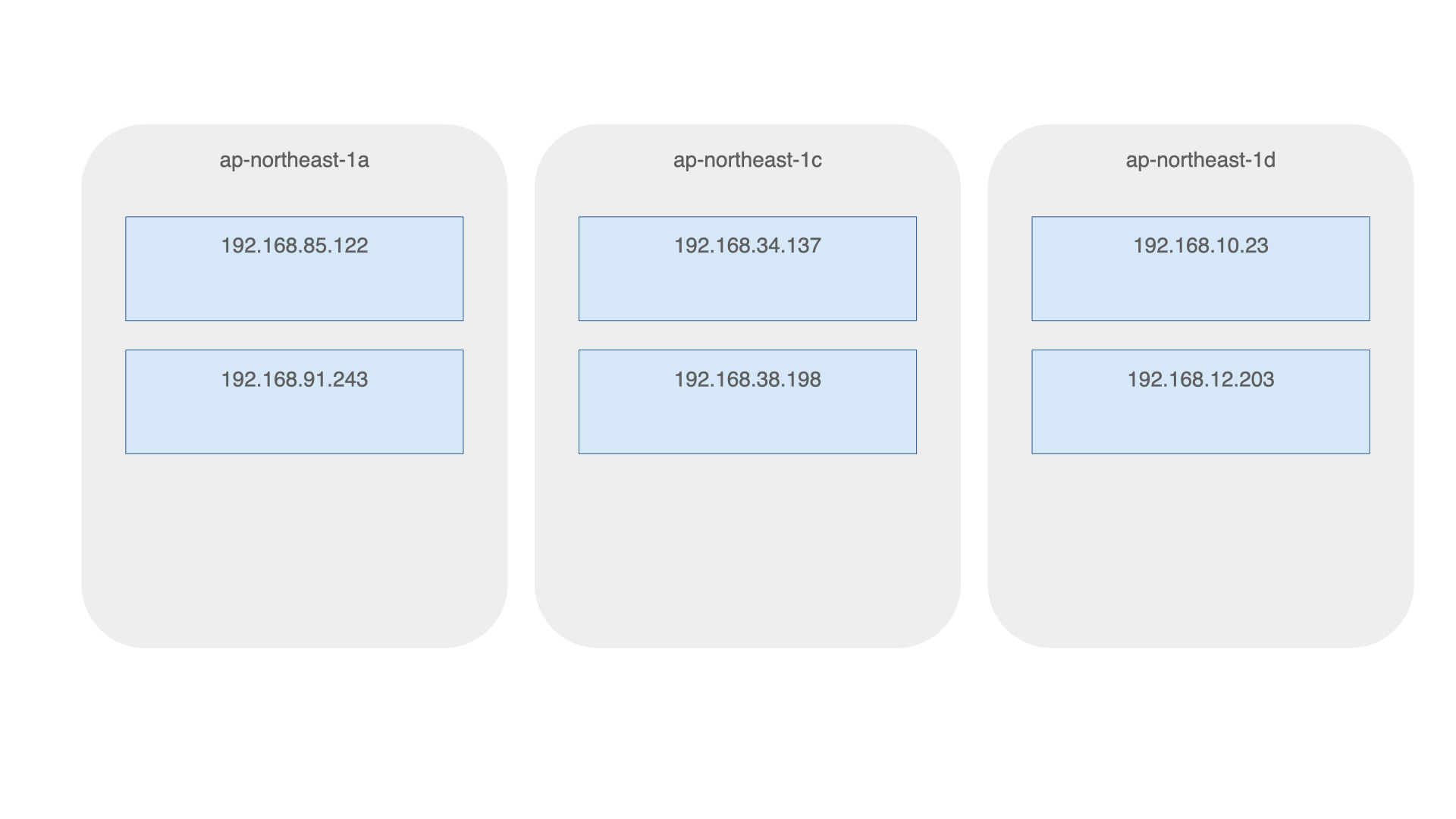
生成されたnodeのlabelを確認すると、topology.kubernetes.io/zone というラベルにAZ名が記載されていることが確認できます。
$ $ kubectl get nodes -o custom-columns=NAME:metadata.name,ZONE:metadata.labels."topology\.kubernetes\.io/zone" NAME ZONE ip-192-168-10-23.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-12-203.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-34-137.ap-northeast-1.compute.internal ap-northeast-1c ip-192-168-38-198.ap-northeast-1.compute.internal ap-northeast-1c ip-192-168-85-122.ap-northeast-1.compute.internal ap-northeast-1a ip-192-168-91-243.ap-northeast-1.compute.internal ap-northeast-1a
ここに、worker1とworker2というReplicaSetを、下記のようなPod配備条件をつけてapplyします。
- worker1とworker2を同じPodに配備しない(PodAntiAffinity)
- worker1、worker2のそれぞれを各AZに拡散配備する(TopologySpreadConstraints)
余談ですが、この配備条件はZooKeeperやFlink JobManagerのような、分散配備に対応したソフトウェアコンポーネントを想定したものになっています。
まずworker2.yamlの記述を以下に記載します。worker1.yamlはほぼ同様なので省略します。
kind: ReplicaSet apiVersion: apps/v1 metadata: name: worker2 labels: app: worker2 spec: replicas: 3 selector: matchLabels: app: worker2 template: metadata: labels: app: worker2 spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - worker1 topologyKey: kubernetes.io/hostname - labelSelector: matchExpressions: - key: app operator: In values: - worker2 topologyKey: kubernetes.io/hostname topologySpreadConstraints: - maxSkew: 1 topologyKey: topology.kubernetes.io/zone whenUnsatisfiable: DoNotSchedule labelSelector: matchLabels: app: worker2 containers: - name: pause image: k8s.gcr.io/pause:3.1 restartPolicy: Always
これをapplyします。
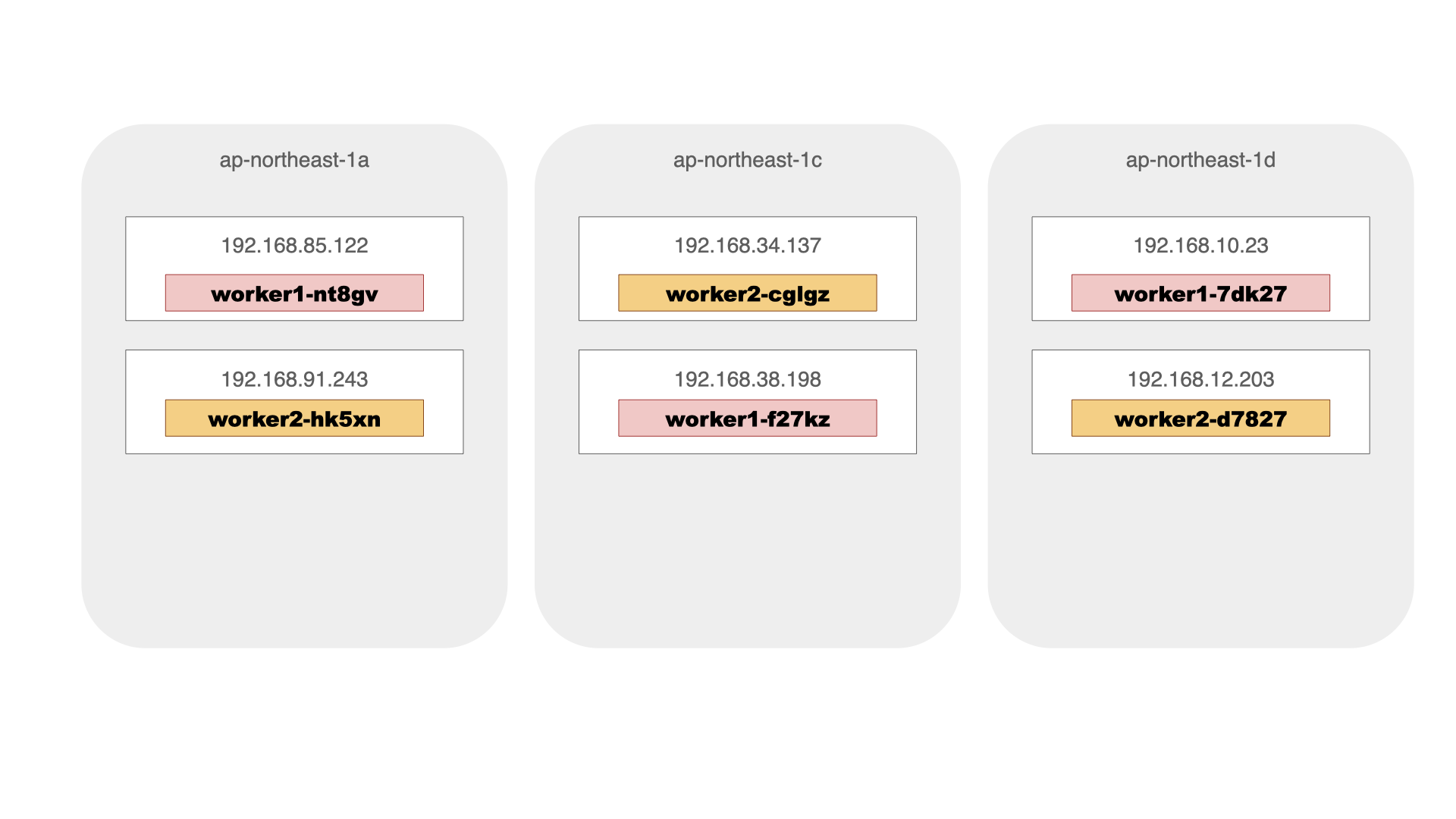
$ kubectl apply -f worker1.yaml -f worker2.yaml replicaset.apps/worker1 created replicaset.apps/worker2 created $ kubectl get pods -o custom-columns=NAME:metadata.name,STATUS:status.phase,NODE:status.hostIP,"LABEL-app":metadata.labels.app NAME STATUS NODE LABEL-app worker1-7dk27 Running 192.168.10.23 worker1 worker1-f27kz Running 192.168.38.198 worker1 worker1-nt8qv Running 192.168.85.122 worker1 worker2-cglgz Running 192.168.34.137 worker2 worker2-d7827 Running 192.168.12.203 worker2 worker2-hk5xn Running 192.168.91.243 worker2
worker1は、192.168.10.23(ap-northeast-1d) 192.168.38.198(同1c) 192.168.85.122(同1a)へ、worker2は、192.168.34.137(同1c) 192.168.12.203(同1d) 192.168.91.243(同1a)へとそれぞれ配備され、期待した配備条件になっていることが確認できます。
AZ障害発生時の挙動
これでAZ障害への対策を考慮したPod配備ができるようになりました。せっかくなので障害発生を試してみたいところですが、AZ障害にはなかなかなかなか会える物ではありません ^^; ので、今回はAZ障害の発生を模擬して、動作を確認したいと思います。
まず、模擬の方法です。そのために、AZ障害が発生するとどうなるか、をまずは考えます。
AZ障害が発生すると、該当AZの全てのNodeやPodが通信不可になります。その結果、kubernetesのコントロールプレーンからNodeやPodが切り離されるような動きになります。その上で、AWS EKSでは、障害等でNodeが切り離された場合に、代替となるNodeを起動して、障害発生前のNode数を維持しようとします。このようなNodeの配備はEC2 Autoscalingグループで実現されています。
そこで、EKSのNode配備を行っているEC2 Autoscalingグループの設定を変更することで、あたかもAZ障害が発生したかのような状況を作り出してみます。具体的には、AutoscalingグループのサブネットIDの設定を直接変更することで、AZを減少させ、AZ障害を模擬します。
まず、Autoscalingグループの設定を変更して、ap-northeast-1a が切り離されてしまった状態を作り出してみます。事前に、AZと対応したsubnetのIDをメモしておき、update-auto-scaling-groupします。
$ aws autoscaling update-auto-scaling-group --auto-scaling-group-name eksctl-mac-exp-nodegroup-ng-c4394488-NodeGroup-10QCM85Q8K41U --availability-zones ap-northeast-1c ap-northeast-1d --vpc-zone-identifier subnet-0495c242582581535,subnet-08f4695e67a8f4bb0
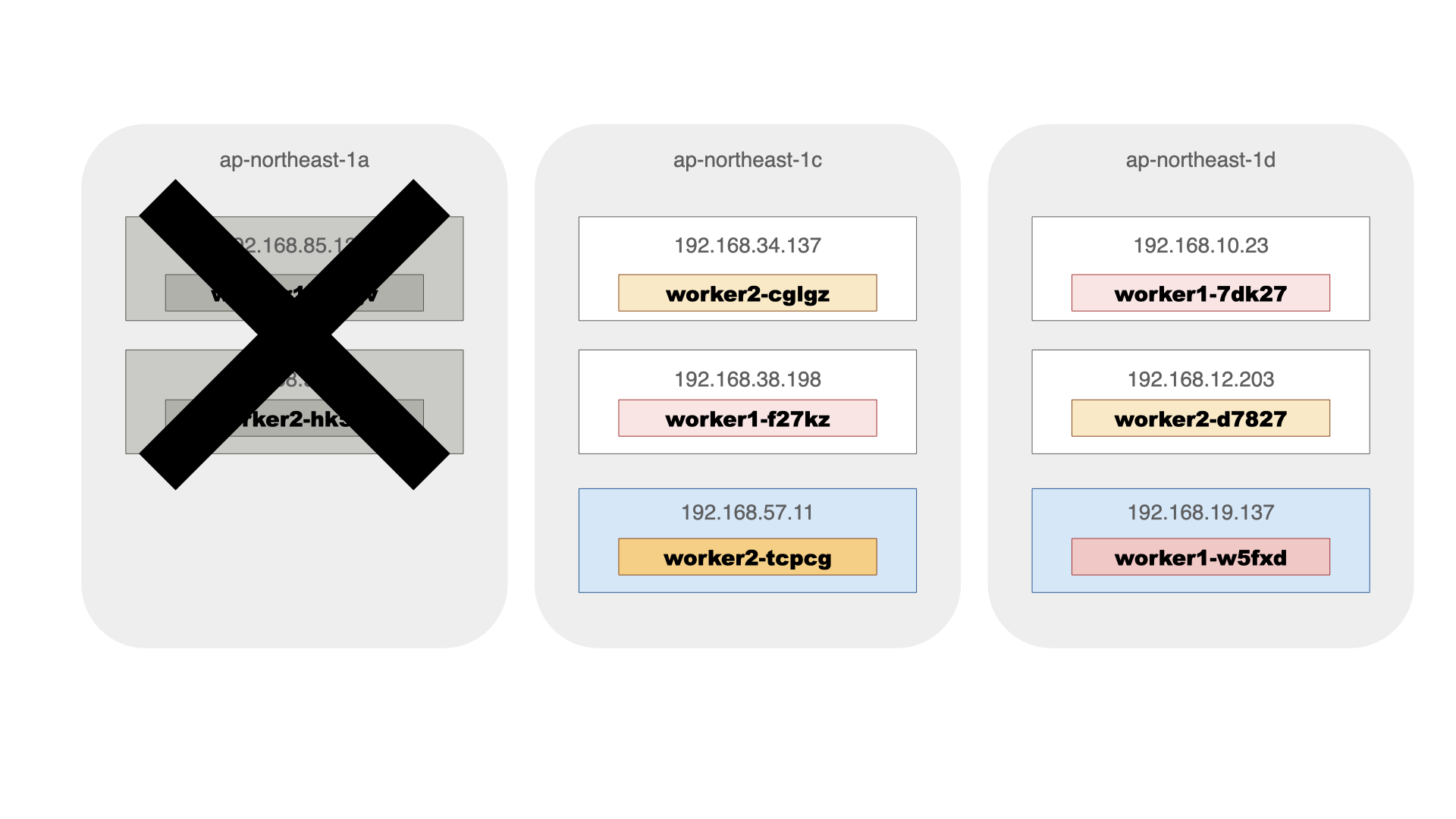
この状態でしばらくしてからNodeの状態を確認するとap-northeast-1aの192.168.85.122と192.168.91.243のNodeが切り離され、代わりに、ap-northeast-1dに192.168.19.137が、ap-northeast-1cに192.168.57.11が追加でdeployされたことがわかります。
$ kubectl get nodes -o custom-columns=NAME:metadata.name,ZONE:metadata.labels."topology\.kubernetes\.io/zone" NAME ZONE ip-192-168-10-23.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-12-203.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-19-137.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-34-137.ap-northeast-1.compute.internal ap-northeast-1c ip-192-168-38-198.ap-northeast-1.compute.internal ap-northeast-1c ip-192-168-57-11.ap-northeast-1.compute.internal ap-northeast-1c
これに合わせて、Podの配備も変更され、worker1は1dに1つ、1cに2つ、worker2は1dに2つ、1cに一つ配備されます。この状態でも、条件は満たされていることがわかります。
$ kubectl get pods -o custom-columns=NAME:metadata.name,STATUS:status.phase,NODE:status.hostIP,"LABEL-app":metadata.labels.app NAME STATUS NODE LABEL-app worker1-7dk27 Running 192.168.10.23 worker1 worker1-f27kz Running 192.168.38.198 worker1 worker1-w5fxd Running 192.168.19.137 worker1 worker2-cglgz Running 192.168.34.137 worker2 worker2-d7827 Running 192.168.12.203 worker2 worker2-tcpcg Running 192.168.57.11 worker2
AZ障害後の復旧
さらに、AZ障害から復旧したらどうなるかを確認してみます。Autoscalingグループの設定を変更して、ap-northeast-1a を復元して見ましょう。
$ aws autoscaling update-auto-scaling-group --auto-scaling-group-name eksctl-mac-exp-nodegroup-ng-c4394488-NodeGroup-10QCM85Q8K41U --availability-zones ap-northeast-1c ap-northeast-1d ap-northeast-1a --vpc-zone-identifier subnet-0495c242582581535,subnet-08f4695e67a8f4bb0,subnet-0704313bfb24522d5
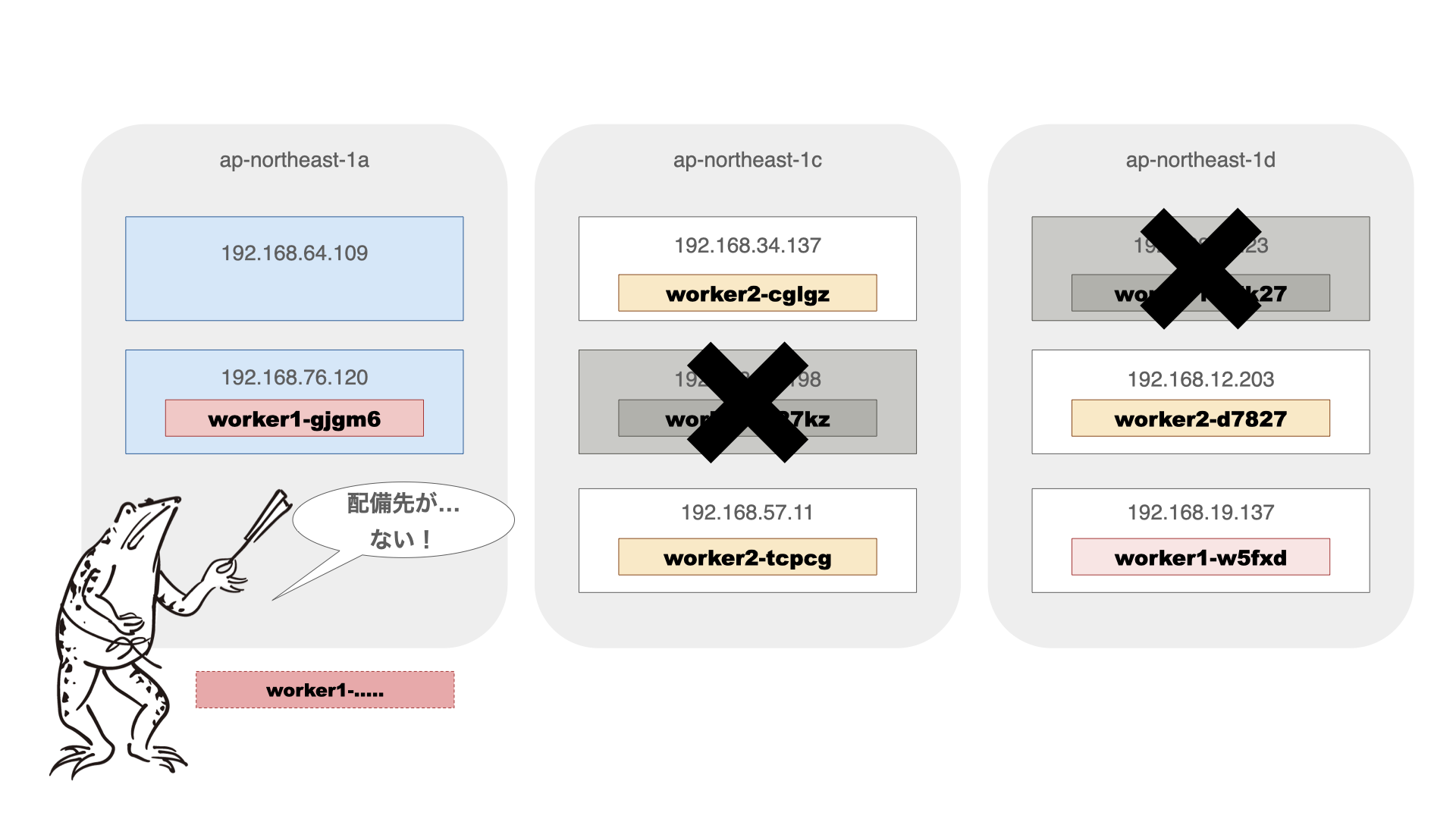
しばらくしてから確認すると、worker1のPodが1つ配備されていません。
$ kubectl get nodes -o custom-columns=NAME:metadata.name,ZONE:metadata.labels."topology\.kubernetes\.io/zone" NAME ZONE ip-192-168-12-203.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-19-137.ap-northeast-1.compute.internal ap-northeast-1d ip-192-168-34-137.ap-northeast-1.compute.internal ap-northeast-1c ip-192-168-57-11.ap-northeast-1.compute.internal ap-northeast-1c ip-192-168-64-109.ap-northeast-1.compute.internal ap-northeast-1a ip-192-168-76-120.ap-northeast-1.compute.internal ap-northeast-1a $ kubectl get pods -o custom-columns=NAME:metadata.name,STATUS:status.phase,NODE:status.hostIP,"LABEL-app":metadata.labels.app NAME STATUS NODE LABEL-app worker1-gjgm6 Running 192.168.76.120 worker1 worker1-vrvll Pending <none> worker1 worker1-w5fxd Running 192.168.19.137 worker1 worker2-cglgz Running 192.168.34.137 worker2 worker2-d7827 Running 192.168.12.203 worker2 worker2-tcpcg Running 192.168.57.11 worker2
どうやら、1aのNodeが追加され、1cと1dのNodeが1つづつ削除されたところで、期待している配備ができない状態になってしまったようです。
これは、kubernetesでは、Podの配備(スケジューリング)の条件評価は、そのPodを配備するタイミングでしか行われず配備済みのPodには影響をあたえないため、AZ構成の変化による削除対象にならなかったNode上のPodは配備されたままになることからこのようなことが起こります。
そこで、descheduler (https://github.com/kubernetes-sigs/descheduler) を利用します。deschedulerは、指定した配備条件を満たしていないPodをTerminateすることで再配備する機能を持っていて、配備条件としてPod Topology Spread Constraintにも対応しています。設定方法などはサイトを参考にしてください。
$ kubectl apply -f descheduler/job.yaml job.batch/descheduler-job created
しばらくしてからPodとdeschedluerのログを確認してみます。
$ kubectl get pods -o custom-columns=NAME:metadata.name,STATUS:status.phase,NODE:status.hostIP,"LABEL-app":metadata.labels.app
NAME STATUS NODE LABEL-app
worker1-gjgm6 Running 192.168.76.120 worker1
worker1-vrvll Running 192.168.34.137 worker1
worker1-w5fxd Running 192.168.19.137 worker1
worker2-d7827 Running 192.168.12.203 worker2
worker2-m2sk5 Running 192.168.64.109 worker2
worker2-tcpcg Running 192.168.57.11 worker2
$ kubectl logs job.batch/descheduler-job -n kube-system
(snip)
I0817 10:25:45.474531 1 topologyspreadconstraint.go:109] "Processing namespaces for topology spread constraints"
I0817 10:25:45.492291 1 topologyspreadconstraint.go:183] "Skipping topology constraint because it is already balanced" constraint={MaxSkew:1 TopologyKey:topology.kubernetes.io/zone WhenUnsatisfiable:DoNotSchedule LabelSelector:&LabelSelector{MatchLabels:map[string]string{app: worker1,},MatchExpressions:[]LabelSelectorRequirement{},}}
I0817 10:25:45.492469 1 topologyspreadconstraint.go:183] "Skipping topology constraint because it is already balanced" constraint={MaxSkew:1 TopologyKey:topology.kubernetes.io/zone WhenUnsatisfiable:DoNotSchedule LabelSelector:&LabelSelector{MatchLabels:map[string]string{app: worker1,},MatchExpressions:[]LabelSelectorRequirement{},}}
I0817 10:25:45.492708 1 topologyspreadconstraint.go:183] "Skipping topology constraint because it is already balanced" constraint={MaxSkew:1 TopologyKey:topology.kubernetes.io/zone WhenUnsatisfiable:DoNotSchedule LabelSelector:&LabelSelector{MatchLabels:map[string]string{app: worker1,},MatchExpressions:[]LabelSelectorRequirement{},}}
I0817 10:25:45.542880 1 evictions.go:117] "Evicted pod" pod="default/worker2-cglgz" reason=" (PodTopologySpread)"
I0817 10:25:45.544087 1 event.go:291] "Event occurred" object="default/worker2-cglgz" kind="Pod" apiVersion="v1" type="Normal" reason="Descheduled" message="pod evicted by sigs.k8s.io/descheduler (PodTopologySpread)"
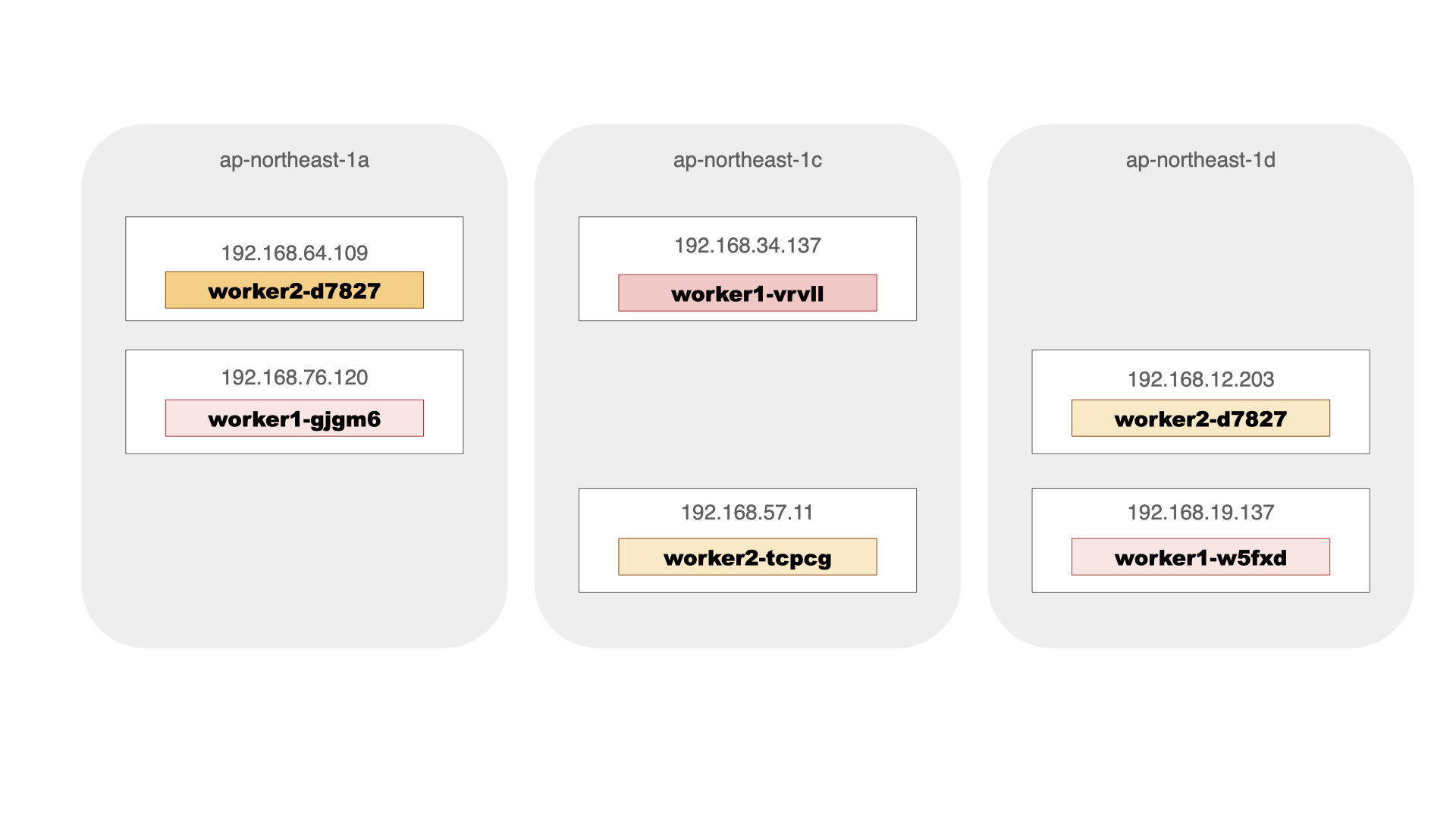
配備条件が再評価されて、いくつかのPodが再配備となり、期待した条件の配備に戻ったようです。
まとめ
今回は、kubernetesのゾーン障害対策としてのPod拡散配備機能に関して、AWS EKSでの動作確認や、ゾーン障害からの復旧時の操作なども含めて、簡単ではありますが紹介させていただきました。本記事が何かしらの役に立ちましたら光栄です。