
Introduction
Hello. We are the five MLPerf HPC members from the ICT Systems Laboratory of Fujitsu Limited. In November 2021, at the international Supercomputing Conference (SC'21), the new supercomputer Fugaku, jointly developed by RIKEN and Fujitsu, held the number one spot in four different supercomputing rankings (TOP500, HPCG, HPL-AI, and Graph500), for the fourth consecutive term. At the same conference, we also won the number one spot in the MLPerfTM HPC benchmark, which is dedicated to the actual deep learning (DL) training process. In this blog, we discuss the challenges of training CosmoFlow, one of the applications of MLPerf HPC, using more than half of the entire Fugaku and becoming the best in the world.
- Introduction
- Performance Tunings
- Result (Shirahata)
- Conclusion (Tabaru, Shirahata, Kasagi, Tabuchi, Yamazaki)
What is MLPerf HPC? (Shirahata)
The MLPerf HPC benchmark suite was developed in 2020 to capture the characteristics of new machine learning workloads on HPC systems, such as training large models on scientific simulation datasets[1].
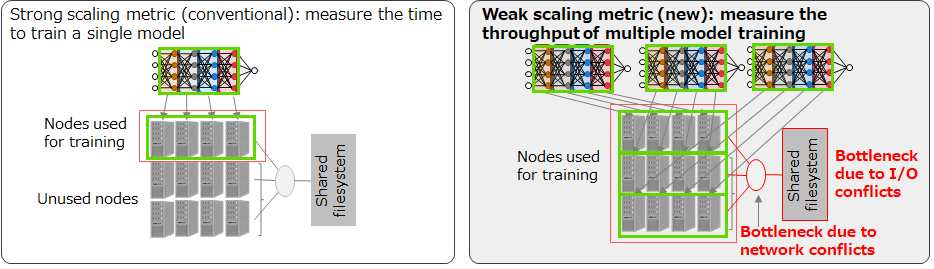
MLPerf HPC measures the time taken to train machine learning models on scientific data. In 2020, MLPerf HPC v0.7 (the first round) established two new benchmarks, CosmoFlow and DeepCAM, related to climate analysis and cosmology, respectively. In this round, strong scaling was used as a measure of the time it takes to train one model.
MLPerf HPC measures the time taken to train machine learning models on scientific data in tasks related to climate analysis and cosmology. In 2020, MLPerf HPC v0.7 (the first round) established two new benchmarks, CosmoFlow and DeepCAM. In v0.7, strong scaling was used as a measure of the time it takes to train one model.
In an actual HPC system, a large number of processes are executed at the same time, but metrics in the round have been measured without the effect of performance bottlenecks that are only apparent in a large number of simultaneous processes. Therefore, in MLPerf HPC v1.0 (2nd round)[2] held in 2021, a new metric (weak scaling) was introduced to compete for throughput when training many models simultaneously using the entire system. By training a large number of models at the same time, we can measure AI processing performance close to that of a supercomputer in actual operation. It can be interpreted as an index for parallel parameter search and other operations on a supercomputer system. Since bottlenecks occur due to data supply (data staging) from the file system to each computation node (equivalent to a server with one A64FX processor; Fugaku has 158,976 nodes) and communication interference in parallel computation, the important points are the base performance of the computer system and the methods to exhausts the capability. By looking at the results of weak scaling, users will be able to select an appropriate supercomputer.
What is CosmoFlow? (Tabuchi)
CosmoFlow is a DL model for understanding cosmological phenomena, which predicts four key parameters in cosmology given the distribution of dark matter in 3D space as input. The model is a typical convolutional neural network (CNN) consisting of convolutional, pooling, and dense layers, but it uses 3D convolutional layers since the input is 3D spatial data. Therefore, the amount of computation required to process an image is higher than that of a general CNN that uses 2D convolutional layers. The training data is a large number of dark matter distributions generated by gravitational N-body simulations, and based on the values of the four parameters and the dark matter distributions generated using them, the model is trained to infer the values of the parameters inversely from the dark matter distributions. The input data for the dark matter distribution is 128x128x128 in size, with a file size of 16MB per sample, and MLPerf HPC v1.0 has 512K samples for training and 64K samples for validation, for a total dataset of about 9 TB. This is a very computationally intensive benchmark that takes about a week to complete on a single NVIDIA V100 GPU.
What is Fugaku? (Tabuchi)
Fugaku was installed at RIKEN as the successor to the K computer. It became fully operational starting on March 9, 2021. As of November 2021, Fugaku is the fastest supercomputer in the world. It has won the number one spot in four supercomputer rankings for four consecutive terms from June 2020 to November 2021.
Processor
The processor (CPU) of Fugaku is the A64FX with the ARM instruction set which is widely used in smartphones. It has 48 computational cores with vector operations called SVE (Scalable Vector Extension), and 32GB of high-bandwidth memory (HBM2) on-chip, so it can compute a large number of data at high speed. Fugaku has a total of 158,976 compute nodes equipped with one A64FX processor per node.
Interconnect
All the nodes are connected by an interconnect called TofuD, which is the successor to the Tofu communication network used in the K computer, and is connected in a multi-dimensional network shape called a 6-dimensional mesh/torus, which enables very fast communication. Although it is actually a 6D shape, it appears to the user as a 48x69x48 3D shape, and when running a computation with multiple nodes, the node shape to be used is specified as a 3D shape.
Storage
In Fugaku, SSD storage is provided for each of the 16 compute nodes (called BoB = Bunch of Blades), and this is called the first level storage. Normally, this storage is used for data staging, temporary storage area and caching for the second level storage (introduced next) for each computation job. The Fujitsu Exabyte File System (FEFS) is used for shared storage, and this is the second level of storage, where users create and store data and programs.
Performance Tunings
DL frameworks and library (Yamazaki)
Next, let's take a look at how to run CosmoFlow in Fugaku.
TensorFlow + OneDNN for aarch64
The CosmoFlow application that we measured uses TensorFlow which is a widely used software for deep learning. TensorFlow natively runs on both CPU and GPU environments. However, it’s standard form does not support the SVE vector instruction of the A64FX, the processor of Fugaku. In order to fully leverage the power of Fugaku, it is important to take advantage of this instruction. Last year, our department developed the OneDNN for aarch64 library.
As described in the blog linked above, for heavy processing such as Convolution, we developed a DL library for the A64FX processor using a JIT (Just In Time) compiler called "Xbyak". It creates the optimal code at runtime and then executes it. In addition, we developed a tool called “Xbyak translator for aarch64” to utilize other software optimized for the existing Intel CPUs. For our MLPerf HPC v0.7 and v1.0 measurements, we used TensorFlow for aarch64, which incorporates OneDNN for aarch64 and TensorFlow for aarch64 with speed-up customizations. This version TensorFlow is available from Fujitsu on github.
Mesh TensorFlow
In order to take advantage of parallelism, we implemented CosmoFlow using Mesh TensorFlow. Mesh TensorFlow is a library we introduced to speed up the training process of CosmoFlow in the first round of MLPerf HPC. Mesh TensorFLow can perform two types of parallel operations simultaneously: data parallelism and model parallelism. In MLPerf HPC v0.7, we achieved the best performance for a CPU-based supercomputer, using about 1/10 of the entire Fugaku system (16,384 nodes) for a single training process, using both data and model parallelism.
Weak scaling
In this year's challenge with weak scaling, it was also important to pack more training processes (instances) onto Fugaku. In other words, if we halve the number of compute nodes used for a single training process, but the computation time is less than twice the original time, then we get a better performance per compute node. Here, scalability, the rate of performance improvement relative to the number of compute nodes, becomes important. The scalability of model parallelism is not as good as that of data parallelism. Therefore, we decided to use only data parallelism. We also reduced the batch size to 128 nodes per training process (instance) in order to achieve a convergence with less computation. In this way, we have created an environment that can be run on Fugaku. We started with a small scale, and gradually ran it on a larger and larger scale while tuning. Tuning is a process of steadily profiling (subdividing the process to obtain comprehensive information on timing and time taken) and identifying the parts that are taking a long time. In the next section, we introduce the optimization methods specific to large-scale execution on Fugaku.
Synchronization and scheduling (Tabuchi)
Inter-job synchronization
In the weak scaling measurement, multiple models (.instances) are trained simultaneously, and the overall time is measured from the training start time of the earliest model to the training end time of the latest model. Since better results can be obtained if the start times are aligned, we synchronized the models just before the start of training. In a normal supercomputer, the process to be executed is registered as a job. When there are enough computers available to run the job, it is executed. Normally, all nodes in a job use MPI (Message Passing Interface, a standard and software widely used in parallel computers) to synchronize with other nodes. However, in our case, since MPI is executed for each model and multiple models are executed in one job, synchronization between models cannot be done in the usual way. Therefore, we focused on the fact that synchronization is done only once at the start time, and we used a simple method of waiting until the flag file is placed on FEFS. Even with this method, the start time deviation was less than 1 second, and we were able to achieve satisfactory performance.
Placing multiple jobs
The number of nodes available for a large-scale execution of Fugaku is 82,944. This is about half of the total number of nodes in Fugaku. The shape of these nodes is 48x36x48. 128 nodes are used for training one model from the viewpoint of training time, amount of data per node, and convergence of training. In other words, 128 nodes x 648 models are executed simultaneously. However, Fugaku was not designed to run hundreds of MPI programs from a single job. Therefore, we consulted and coordinated with the team in charge of the Fugaku operation and system engineers (SE), and decided that we could split the job and execute multiple jobs at the same time. We decided to run 648 models by first running 12 jobs of 24x6x48 geometry at the same time and then running 54 models of 8x2x8 geometry in each job.
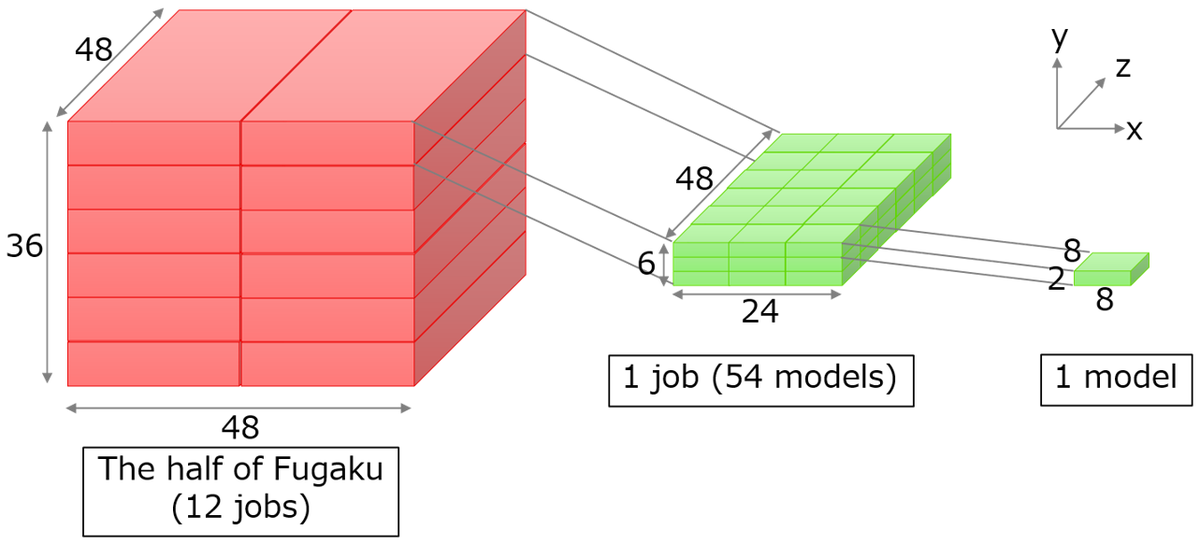
The placement of the nodes in a model is also important for speeding up the process (to minimize the overhead of communication). In the DL training process, allreduce communication is performed to aggregate the gradients in each step (called “batch”, which is a processing unit of inference, gradient calculation, and weight adjustment for tens or hundreds of data units). By mapping the processes of each model to nodes in a cubic and strokeable manner, even a large number of models can be communicated rapidly over the TofuD interconnect.
Data staging (Kasagi)
Deep learning uses a large input data set, and the neural network is trained by reading the data dozens to hundreds of times (one pass is also called an epoch). MLPerf HPC's CosmoFlow uses a dataset of about 9 TBytes, so each neural network needs to input 9 TBytes x number of epochs of data. Weak scaling in MLPerf HPC requires hundreds more neural network models to run simultaneously, which increases the number of accesses to the input data and the amount of communication. Data staging is a widely used method in the field of HPC, where only the necessary amount of input data on the file system is copied to the local disk, thus reducing the number of accesses to the file system and the amount of communication. For example, if CosmoFlow does not perform data staging, the load on the file system is as shown in the following figure.
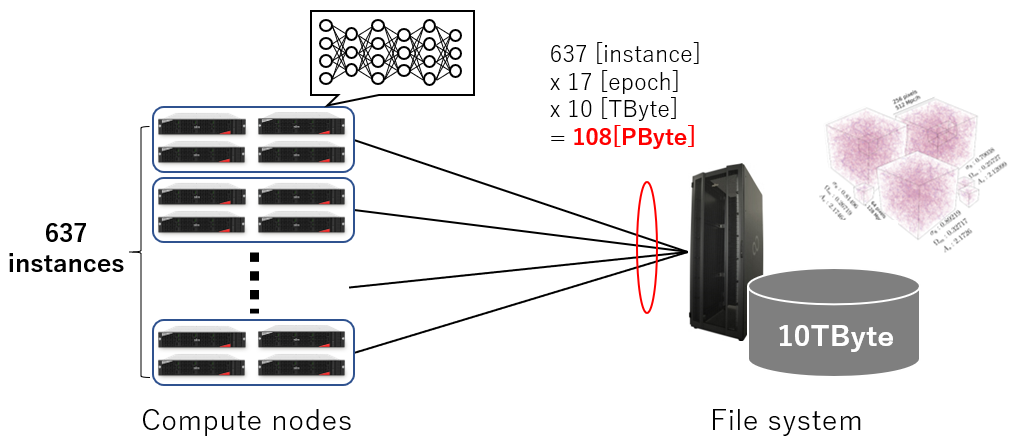
In such a situation, even if the nodes are connected to the file system with a communication bandwidth of 1 [TByte/sec], the communication alone would take 5.1 hours. Data staging is a necessary technology to avoid such a situation and to operate at high speed.
Data staging on Fugaku
Fugaku uses the TofuD interconnect not only for computations, but also for data transfer to and from the FEFS file system. The TofuD interconnect provides excellent communication performance for collective communication, and we take advantage of this characteristic for staging. Fugaku is composed of a large number of blade servers with two A64FX compute nodes. These eight blade servers are called a BoB. In Fugaku, each BoB is equipped with an LLIO (Lightweight Layered IO-Accelerator), which acts as the first level storage cache for a total of 16 compute nodes on the BoB. Two techniques are used to speed up the staging of the CosmoFlow dataset. The first is data compression. Although the dataset is approximately 9 TB, TFRecord, which is a TensorFlow data format, supports gzip compression, which can reduce the size of the dataset to about 1/6 of its original size, thereby reducing the communication bandwidth required. The second is the distribution of data sets via MPI communication. Since all data sets used by each model are the same, a node in charge of one model can read a data set from FEFS and distribute it to nodes in charge of other models via MPI. By eliminating the concentration of access to FEFS, the staging time can be reduced to the same level as training only one model. The MPI program that performs this staging is executed on a per-job basis, separately from the training process.
Result (Shirahata)
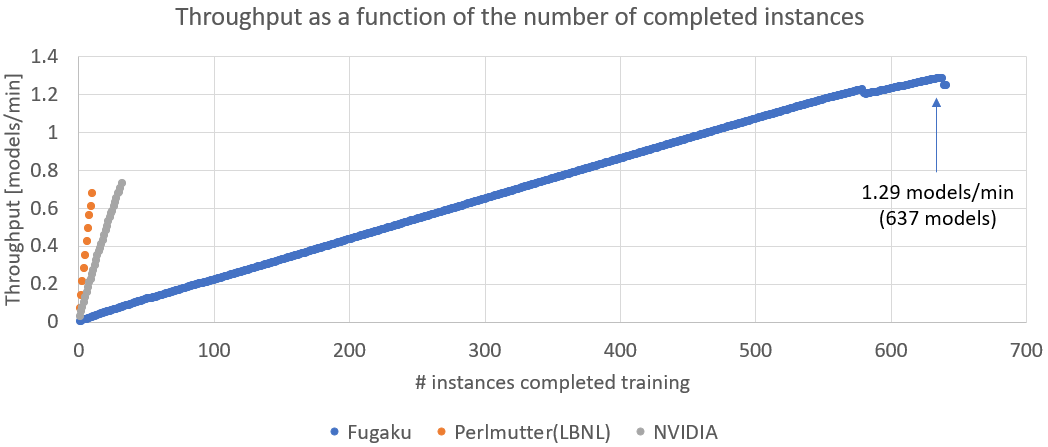
Eight major supercomputing institutions participated, and more than 30 results were presented, including eight submitted under the new weak scaling (throughput metric). The benchmarks included the Argonne National Laboratory (ANL), the Swiss National Supercomputing Center (CSCS), a joint team from Fujitsu and RIKEN, Helmholtz AI (a joint project of the Jülich Supercomputing Center and the Karlsruhe Institute of Technology's Steinbuch Centre for Computing), Lawrence Berkeley National Laboratory (LBNL), the U.S. National Center for Supercomputer Applications (NCSA), NVIDIA, and the Texas Advanced Computation Center (TACC). The joint team from Fujitsu and RIKEN used Fugaku to participate in CosmoFlow. The team used 82,944 nodes, more than half of the total number of Fugaku nodes, and trained 648 instances simultaneously using 128 nodes per instance. As a result, the throughput reached its maximum at 495.66 minutes, when training was completed for 637 instances, and was 1.29 models/min, 1.77 times faster than other systems, achieving the world's highest throughput performance.
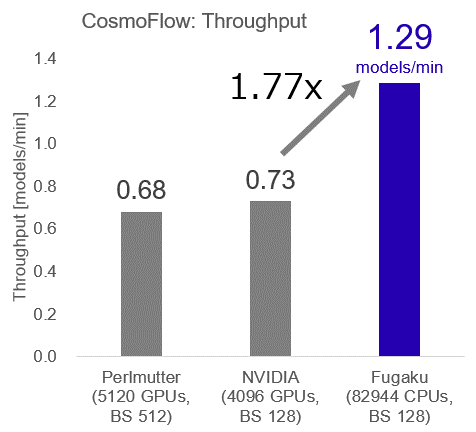
Fugaku was able to train 637 instances at the same time, while the other systems were able to train up to 32 instances at the same time, and a comparison of the throughput trends shows that the throughput increased in accordance with the increase in the number of instances.
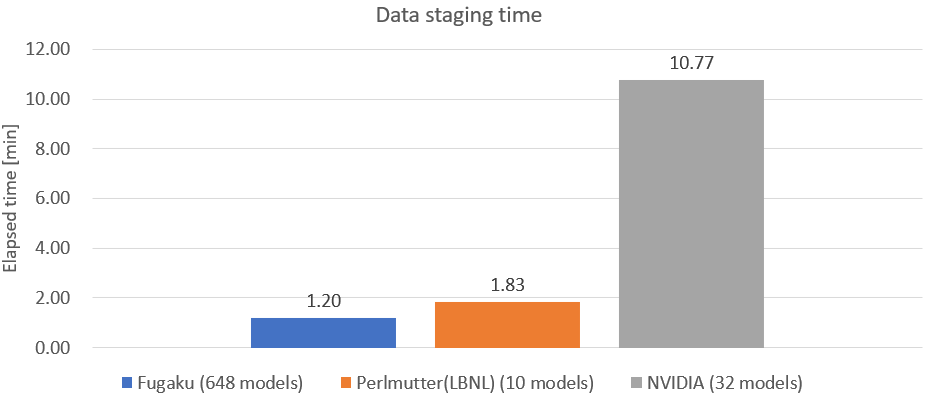
As for the storage performance, when we compare the actual data staging time with the results of other systems, we can see that Fugaku completes in less time than other systems, even though the number of instances is more than 20 times than that of other systems.
Conclusion (Tabaru, Shirahata, Kasagi, Tabuchi, Yamazaki)
Following last year's challenge, this year's challenge was to run the CosmoFlow applications on a large scale on MLPerf HPC. High weak scaling (throughput) performance means that large-scale hyperparameter search to improve the performance of various DL applications can be performed efficiently. The fact that Fugaku has become the world's best in this field shows that it can continue to contribute to the improvement of AI performance using DL. During the challenge, we made preparations for the measurements, but we encountered many problems that only happen for large-scale executions. During the large-scale measurements, we sometimes had to stay up late at night to coordinate with other challenge implementers within a limited schedule. We also encountered hardware failures and other problems during the long run, but thanks to the generous support of the Fugaku operation staff and SE members, we were finally able to complete the run with nearly ideal performance. I would like to take this blog post opportunity to thank them. We would like to continue to contribute to solving social issues through the improvement of AI and simulation performance.
References
[1] MLPerf HPC v0.7 results, LIST
[2] MLPerf HPC v1.0 results, LIST