
この記事は FUJITSU Advent Calendar 2021 の14日目の記事です。
こんにちは。データ&セキュリティ研究所の江田智尊, 小久保博崇, 大堀龍一です。
AIサイバーセキュリティプロジェクトでは機械学習システムのセキュリティや機械学習によるサイバー攻撃対策の研究開発を行っています。 先日、ネットワーク侵入検知システム (IDS) のアラートから隠れた脅威を発見するための技術を psykoda というOSSとして公開しました。
IDS とは
私たちのネットワークは常にサイバー攻撃の脅威に晒されています。 ネットワーク型の侵入検知システム (Intrusion Detection System, IDS) とはネットワークを流れる通信パケットを解析し、ルール (シグネチャ) にマッチする通信をアラートするシステムです。 有償・無償を含め様々な製品がありますが、無償から始められる OSS のなかでは Snort がデファクトスタンダード、最近は Suricata というのもあります。
Snort を例にとると、ルールは通信プロトコル、送信元/先のホスト (IPアドレス) とポート番号、送信データなどを組み合わせたもの です。 ルールはソフトウェア本体と同じ場所で無償配布されているものや開発元・サードパーティーのベンダーが有償で販売しているものなどがありますが、いずれも日々アップデートされています。 裏を返せば必ずしも完璧なものではないということです。 特に、セキュリティを重視してアラート基準を下げると、過検知も含めて対処しきれない量のアラートが発生してしまいます。
psykoda
一つの解決策として私たちは、半教師あり異常検知やモデル解釈のような最近の機械学習技術を組み合わせ、psykoda というOSSを開発しました。 psykoda は大量のアラートから特異な挙動を見つけて (時間帯, 送信元, 特異な特徴) を提示することで、隠れた脅威を発見するために役立ちます。
Python 3.8 で実装しており、機械学習には TensorFlow を使用しました。
詳細な依存性については リポジトリ にメタデータがありますので、poetry install するか、またはそちらを閲覧してください。
使用例
それでは、psykodaの使用例を紹介します。
psykodaの基本的なコマンドは次の通りです。
$ poetry run psykoda --config CONFIG --date_from DATE_FROM --date_to DATE_TO
ここで、CONFIG は設定ファイルのファイルパスを表します。
設定ファイルには、検知対象となるIDSアラートログの格納場所や検知対象とするサービスなど様々な項目を記載できます。
設定ファイルの書き方はドキュメントを参照してください。
DATE_FROM、DATE_TO はそれぞれ検知の開始日と終了日を表します。
例えば、設定ファイル config.json を使って、2021年10月23日 から 2021年10月24日 までのIDSアラートログを対象に検知を実行する場合は次のようになります。
$ poetry run psykoda --config config.json --date_from 2021-10-23 --date_to 2021-10-24
コマンドを実行すると学習と検知がはじまり、最終的に下記のような簡易レポートが出力されます。
(*snip*) [RESULT] Detection summary file: ./demo_NW/result/2021-10-23__2021-10-24/report.csv Number of unique anomaly IP addresses: 3 - 192.168.13.2 (max anomaly score: 28.721521) - 192.168.11.3 (max anomaly score: 15.651522) - 192.168.13.3 (max anomaly score: 15.23638)
この例では3つのIPアドレスが異常な挙動をしていると検知されました。
3つの中でもanomaly scoreが突出して高い192.168.13.2は特に怪しいと言えます。
詳細な結果レポート (Detection summary file) には異常スコアや後述する Shapley値など結果を精査する際に役に立つ情報が書かれているため、オペレータはその情報をもとにヒアリング調査などを行うことができます。
技術的詳細
入力となるIDSアラートログは (日時, 送信元, ..) の形式をしたレコードの集まりです。 最初に (日時(時単位), 送信元) ごとに集計を行い、通信内容をもとに特徴量を算出します。 これに過去の過検知データをあわせて、半教師あり異常検知エンジン Deep Semi-Supervised Anomaly Detection (Deep SAD) に入力すると、各 (日時(時単位), 送信元) に対して異常度を表すスコアが出力されます。 スコアの高いもの (上位から件数、または閾値を指定) を異常として取り出します。 さらにこれらを Shapley Additive Explanations (SHAP) に入力すると、それぞれの異常について「異常スコアに寄与した特徴量はどれか、また、それはどの程度か」を出力します。 psykoda はこれらをまとめたレポートを出力します。 このレポートを見ると、ユーザは「どの時間帯の、どのホストの通信を、どのような観点で精査すればよいか」がわかります。
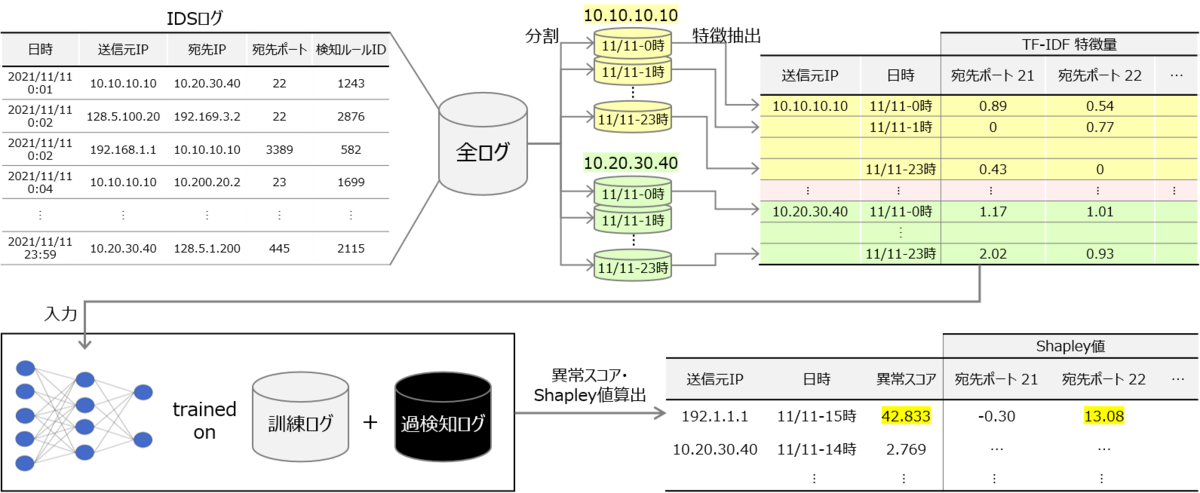
特徴量抽出
各 (日時(時単位), 送信元) の挙動を表す特徴量として、たとえばポート番号やルールIDのTF-IDFを計算しています。 アラート内に珍しいポート番号が多く含まれるような場合にTF-IDF値が大きくなることで、特異な挙動が強調され、検知しやすくなります。
Deep SAD
異常検知 (Anomaly Detection, AD) は、少なくとも大部分は正常であると信じられるデータから異常なものを取り出す機械学習タスクで、一般的には正解データの与えられない教師なし学習に分類されます。 「正常/異常」もしくは「業務通信/攻撃通信」のように正解のわかる学習データが与えられてクラス分類を行うタスクと対比され、それぞれ研究がなされてきました。 Ruff et al. による Deep Semi-Supervised Anomaly Detection (Deep SAD) は「半教師あり異常検知」で、これらの「いいとこどり」をしようというアプローチです。 論文から図を引用すると、(b) 普通の異常検知では既知の異常があっても活かすことができない、(c) 普通のクラス分類では未知の異常を発見することが難しい、のに対し、(f) 半教師あり異常検知では既知の異常を確信をもって異常と分類したうえで未知の異常も (確信度は低いものの) 正しく異常として検知できるというわけです。

これは「アプライアンスや機械学習システムが異常 (攻撃の可能性あり) とした通信について、オペレータが精査して判断や対処をおこなう」ことを継続するセキュリティオペレーションと相性がよく、判断結果を蓄積していくことで精度の向上が期待されます。 本アプリケーションでは過検知 (psykoda に異常とされたがオペレータが精査すると攻撃にみられるパターンではないと結論付けられたもの) のリストを作成することによって以降の過検知を抑制することができます。
半教師あり異常検知の1つの実装が深層学習を利用した Deep SAD で、著者らによる PyTorch 実装も公開されています。 私たちはこちらを参考に TensorFlow で必要な機能を実装し、オリジナルのライセンス (MIT) も表示したうえで利用しました。
SHAP
機械学習アルゴリズムによってアラート/ホスト/通信が異常/攻撃疑いとされたとき、それをオペレータが精査するには判定の根拠が必要です。 そこで、各特徴量が異常度を表すスコアに寄与した度合いを示す量として Shapley値というものが提案されています。 もともとはゲーム理論で使われる概念で、特徴量はプレイヤー、異常度を表すスコアは全体に対して与えられる報酬、Shapley値は報酬の (ある意味で公平な) 配分方法にあたります。 Lundberg, Lee による論文 とともに やはり GitHub に機械学習アルゴリズムの種類に応じた実装が公開されています。 リポジトリ名の SHAP は SHAPley の略ではなく SHapley Additive exPlanations のようです。
実装上のポイント
「(日時(時単位), 送信元) ごとに集計を行」うと書きましたが、実用上の要請から、いくつか前処理の機能を加えています。 たとえば:
- 実験で使用した形式のログファイル、および、Snort 2 でから出力できる CSV ファイルからのデータの読み込み
- 必須属性値が抜けたレコードを除外するなど、基本的なデータクレンジング
- サブネット定義ファイルにしたがい、IPアドレスからネットワーク名を求める
- 分析を実行する単位の定義: 送信元IPアドレスの位置 (グローバル/プライベート、特定のネットワーク) や送信先ポート番号 (≒サービス: 80 は HTTP, 443 は HTTPS など) によるフィルタ
- 除外リスト: 既知のIPアドレス (範囲) や他の列の値を指定して分析対象から除外
- アラート数の少なすぎる/多すぎるIPアドレスを除外
- 送信先ポート番号が動的・私用ポート番号である場合は特徴量を計算するにあたりすべて同じ値で置き換え
これらは地味ですが、分析を回しながら研究開発を進めていると、頻繁に変更になったり当初ハードコードしていたのをやめて設定できるようにしたくなったりと手のかかる部分でもあります。 また、読んでいる論文に適用結果の例が示されていても詳しい方法が不明だったりして再現が難しい原因であったりもします。 公開したバージョンでも、すでに Snort を利用している環境にあわせて適用するには設定ファイルだけでなくコードにも変更が必要になる場合が想定されます。 この点は以降のバージョンで改善していきたいと考えています。 まだ至らない点も含め、psykoda における例が参考や議論のきっかけになればと思います。
適用例
CIC-IDS2017 というIDSの公開 (登録は必要) データセットを用いて検証を行いました。 これはIDSの評価を主な目的として既存のものの欠点を克服するべく作られたデータセットで、最近の研究ではデファクトスタンダードになっています。 データ形式はパケットキャプチャだったので、これを私たちで Snort へ入力してアラートログを生成しました。 この際、Snort のルールは多くのアラートを出すように調整しました。
ログを (日時(時単位), 送信元) で分割すると訓練データ (1日目の、攻撃を含まないログ) が2541レコード、テストデータ (2–5日目の、攻撃も含むログ) が9087レコードとなりました。 後者のうち実際の攻撃に関連するのは42レコードです。
乱数シードを変えて実行した5回の実行結果で異常スコアの上位10件を調べると、各回とも8件が実際に攻撃に関連しており、top-10 precision は 80% という評価になりました。 ランダム抽出なら top-10 precision は5%程度になるので、それに比べて十分に良い結果といえます。
また、FPR (偽陽性率: 攻撃でない通信を異常として検知してしまう割合) を 1%, 5% とするときの TPR (真陽性率: 攻撃を正しく異常として検知する割合) は 60%, 71% 程度でした。 この評価値だとランダム (FPR = TPR) よりは良いとはいえ多少の見逃しも存在することになりますが、たとえば「攻撃被害を受けたアドレスが送信元となるログは検知できていないものの、攻撃元は別の通信で異常として検知できているため、攻撃元を監視追跡すればよい」といったケースでした。
OSS化について
クローズドなワークショップで psykoda を紹介したところ「企業研究所からのOSS公開に関する物語が気になる」といった反応もいただきました。 知財にまつわる手続などについても、機会や「気になる」という反応があれば紹介してみたいと思います。 「自社ではこうなっている」という情報を出せるところにお勤めの方などいらっしゃいましたら、そちらもぜひシェアしてください!
まとめ
ネットワーク侵入検知システム (IDS) のアラートから隠れた脅威を発見するための OSS psykoda の公開にあたり、使用法と技術的側面・実装や評価などについて紹介しました。 Star, Discussion/Issue/PR, SNS上での議論, お問い合わせ (ブログ全体で共通) などを歓迎いたします。