 こんにちは。人工知能研究所の平井、茂木、桝井です。
こんにちは。人工知能研究所の平井、茂木、桝井です。
富士通ではAIが人と協調して自律的に高度な業務を推進する「Fujitsu Kozuchi AI Agent」を2024年10月より先行提供しています。AIエージェントとは、人から与えられたゴールに対して、自分自身でどういった個別タスクが必要かを判断して全体の処理フローを計画し、利用可能なリソースを駆使して自律的にゴールを達成する生成AIの進化形態です。これまでに、様々なAIエージェントが提案・発表されていますが、我々は、一般的なオフィスワークのみならず、製造、物流、公共・道路管理、建設分野などの現場作業への適用をターゲットとしています。作業現場では、高齢化や人材不足が進むことによって作業者の習熟度・工数を確保することが困難となっており、現場監督・作業者における安全面での対応や教育のための負担が増え、社会問題化への懸念事項となっています。
【12/13 12:00 - 解説動画へのリンクを追加しました】

一般的なマルチモーダルLLM(Large Language Model)で構築されたAIエージェントを利用し、現場に設置された単眼カメラからの映像を入力して現場作業の安全監視などに適用した場合には、次に挙げるような課題が発生し、実用化の阻害要因となることがわかっています。
- 作業者と作業車両などの移動物体の正確な距離を測定することができず、安全作業指針順守の確認ができない
- 現場作業者の状態を把握する際、安全保護具着用状態や、隠れによって体全体が映っていない車両(フォークリフトなど)の運転作業者などを正確に認識できない
こうした課題はマルチモーダルLLMにおける空間理解能力の不足を露呈したものであり、現場監督・作業者の負荷を軽減するための映像解析型現場作業支援エージェント(以降本記事では現場作業支援エージェントと称します)としては本来備えていなればならない機能です。本記事では、我々人工知能研究所 Human Reasoning CPJにて開発中の現場作業支援エージェントの特徴と、その空間理解能力を強化するための追加学習技術に関してご紹介していきます。なお、現場作業支援エージェント技術全体や評価環境、実用化に向けたスケジュールについては、こちらのプレスリリースにご紹介がありますので、是非ご一読ください。
現場作業支援エージェント
現場作業支援エージェントは、現場に設置された単眼のカメラ映像と、製造・物流などの各現場における作業指示書などのドキュメントを入力とし、後述する強化された空間理解能力を発揮して、作業現場で生じたヒヤリハットを検知したり、関連したインシデント報告を行うことにより、現場監督・作業者の実務支援を行います。
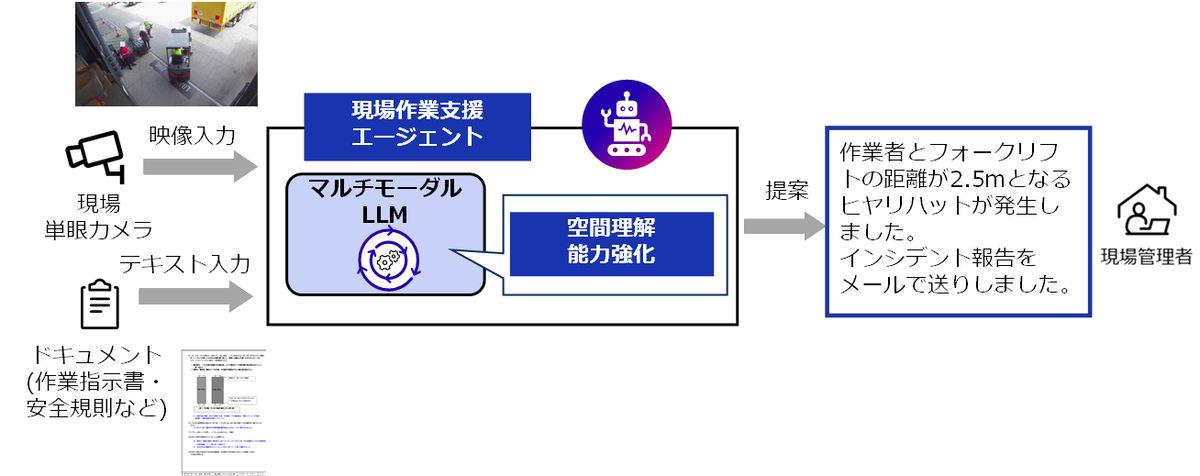
空間理解能力の強化技術
マルチモーダルLLMが単眼の2Dカメラ映像から3D業務空間を把握できるようにするための強化技術として、マルチモーダルLLMへの追加学習フローを下図に示します。まず最初に、安全規則などの現場関連ドキュメントに含まれるフォークリフトや人などの対象物を選択します。次に、現場で取得された単眼の2Dカメラ映像から、物体認識技術によって特定された複数の対象物の位置データと、2Dカメラ画像の各ピクセルに深度情報を生成させた3D深度画像を合わせ、複数の対象物を個々に区別できる3Dデータを生成します。この3Dデータ上では、対象物の位置関係を3D空間で理解することが可能となります。この後、3Dデータと業務空間に関わる「人とフォークリフトの距離は?」という質問と「1.5m」という回答を対象物ごとに数多く用意します。さらに、安全保護具着用状態や、隠れによって体全体が映っていない作業車両(フォークリフトなど)の運転作業者の画像などを追加で用意します。最後に、これらの教師データを利用してマルチモーダルLLMをファインチューニングすることで、現場作業を支援するための空間理解能力が獲得できます。
なお、専用の空間推論AIエンジンを使用せず、マルチモーダルLLMに空間理解能力を持たせる理由は、現場の安全などに関わる事象に関してリアルタイムに現場監督・作業者を支援する必要があり、マルチモーダルLLMに言語処理能力と空間推論能力の両者を持たせることで構成を最小化し、映像とテキスト入力から直接回答出力を導出して全体の処理速度を高めることができるためです。
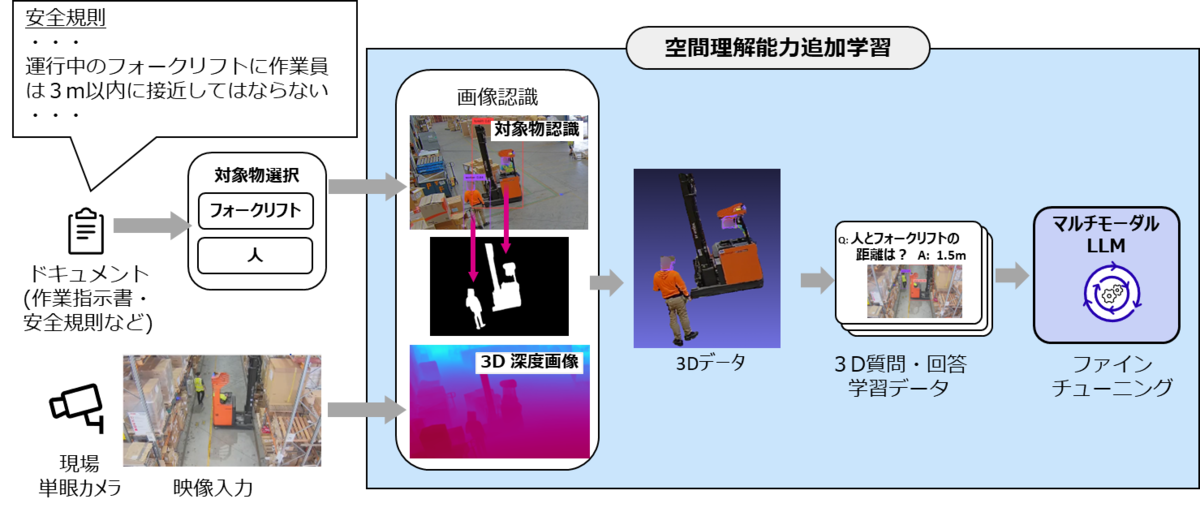
既存のマルチモーダルLLMに空間理解能力を付与するためのファインチューニングでは、イメージと会話をjsonフォーマットに変換したLLaVA形式のデータセットを用意して、画像内の空間的文脈や物体の相対位置関係を学習します。この時、一部のパラメータのみをチューニングするLoRA手法*1などを活用することで、計算コストを削減しながら学習効率を高め、並行して、空間特徴量の抽出を最適化して空間理解能力を高めることができます。
3Dデータ作成の高精度化技術
単眼カメラ画像から対象物間の距離を正確に推定できる3Dデータを生成するためには、
- 単眼カメラキャリブレーション
- Depth Scale推定
が重要になります。これまでは、チェスボードを使ったカメラキャリブレーション(内部・外部パラメータ推定)が一般的に使用されていますが、現場作業者がチェスボードを配置・スキャンする負担が大きく、単眼カメラ映像からの自動キャリブレーションが必須となります。また、単眼カメラで推定した3D深度情報は実スケールと合わない場合が多いため、深度推定結果と実スケールとの相関を推定(Depth Scale推定)する必要があることが判明しました。
単眼カメラキャリブレーション
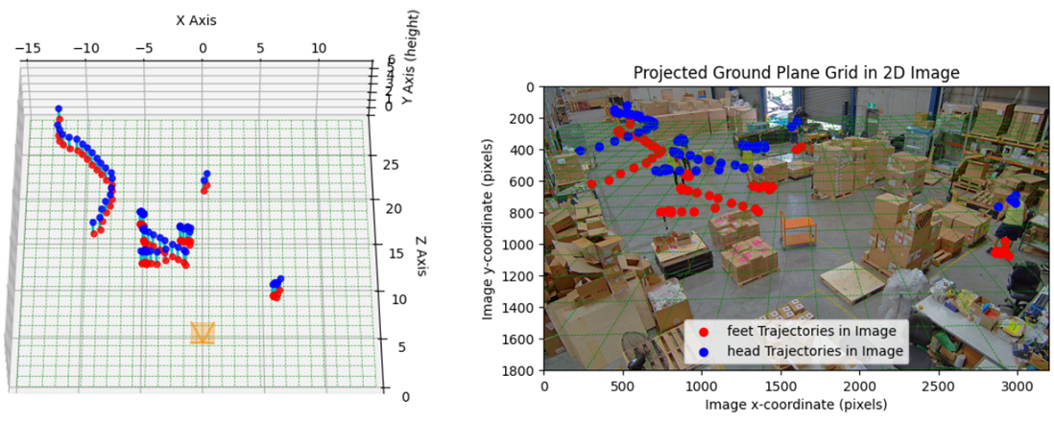
単眼カメラの画像からカメラの内部パラメータ(焦点距離や歪み係数)と外部パラメータ(カメラの角度)を同時に推定するツールとして、深層学習と幾何最適化を組み合わせたGeoCalib*2を活用できます。しかし、このモデルではカメラの位置(カメラ高さなど)を推定できない、という課題がありました。そこで、我々はGeoCalibで推定したパラメータと、骨格推定モデルより得られた人の骨格から決まる人物のスケールを利用し、人物の高さとカメラ高さを同時に最適化する手法を開発しました。 カメラキャリブレーション結果の一例を示します。右側の画像は、検出した複数の人の骨格のうち、足(赤)と頭部(青)の2D座標軌跡をプロットしたものです。左側の画像は、これらの2D座標軌跡から推定した、足(赤)と頭部(青)の3次元座標をプロットしたものです。このような手法で、単眼カメラ画像からカメラパラメータを推定し、人の3次元位置の動線を推定することができます。
Depth Scale推定
単眼カメラ画像から3D深度を推定し、その深度情報から3Dデータに変換するには、焦点距離とDepth Scaleが必要となります。焦点距離は前述の単眼カメラキャリブレーションで求められますが、Depth Scaleは、以下の手順で導出します。
- 基準となる平面(例えば床面)を推定する。
- 基準面上で複数の2次元座標を抽出し、カメラパラメータを用いて、上記の2次元座標から3次元座標Xを算出する。
- Depth Scaleの初期値を1として、深度情報を使って上記の2次元座標から3次元座標X'を算出する。
- 複数点でのカメラパラメータを用いて算出した3次元座標Xと、深度情報を使って算出した3次元座標X'を用いて、複数点間での距離をそれぞれ算出し、その比よりDepth Scaleを推定する。
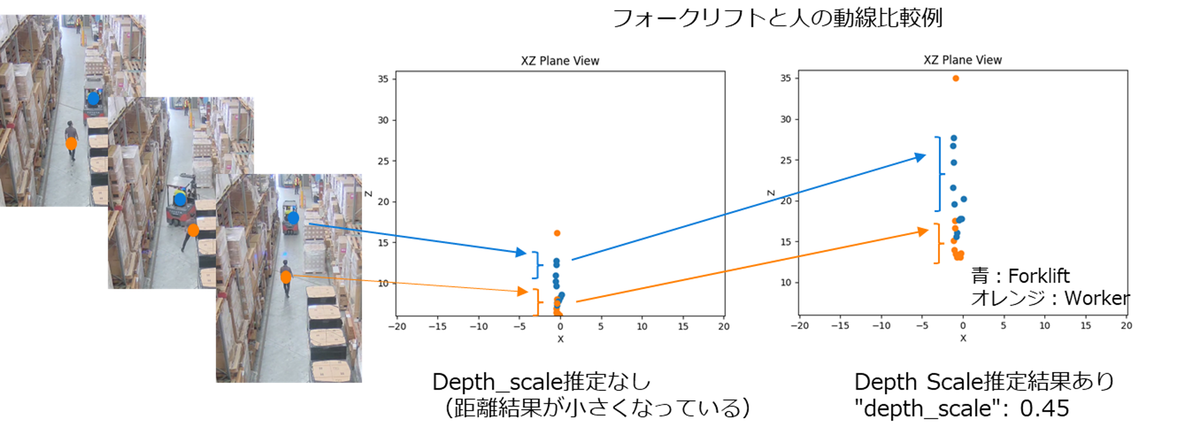
上記の単体カメラキャリブレーションとDepth Scale推定の2つの技術により、単眼カメラの画像情報のみから、物体の3次元位置を正確に推定できます。Depth Scaleを推定した場合と推定しない場合の結果例を比較して示します。この例では、Depth Scaleが0.45となり、Depth Scaleを推定しなかった場合には実際と大きくかけ離れた距離が学習されてしまうことがわかります。
これらの技術を利用した教師データにて追加学習の結果、下図のようにフォークリフトに最も近いオペレータとの距離や、安全保護具(PPE: Personal Protective Equipment)を着用していない作業員の位置が現場作業支援エージェントから出力されます。


おわりに
本稿では、製造・物流現場における作業者への支援が可能な現場作業支援エージェントの概要と、要求される空間理解能力の獲得・強化に必要なファインチューニング技術、および、学習データの高精度化のための単眼カメラキャリブレーションとDepth Scale推定の各技術をまとめました。この結果、作業者と移動物体の正確な距離を測定したり、安全保護具の着用状態を確認することが可能となりました。本稿でご紹介した技術については、こちらのビデオでも解説しております。
今後は、当技術をより広い分野に適用できるよう、Human Reasoning CPJで開発している"KG拡張RAG for VA"技術との連携を含めて開発を進めていきます。KG拡張RAG for VAについては、ぜひこちらのブログもご覧ください。
この記事に関わる技術は、以下のメンバーで開発を行いました。この場を借りて紹介させていただきます。
- 富士通研究所 人工知能研究所 Human Reasoning CPJ:姜山、桝井昇一、茂木厚憲、Fan Yang、平井由樹雄、草島育生、マリニョ ソアレス マウロ、小林由枝
- 富士通研究所 人工知能研究所 AIイノベーションCPJ:渡辺康人
- ジャパン・グローバルゲートウェイ アプリケーションギルドDivision:石田浩之、柴原侑平、津島健