 こんにちは。人工知能研究所の成田・福井・彭です。
こんにちは。人工知能研究所の成田・福井・彭です。
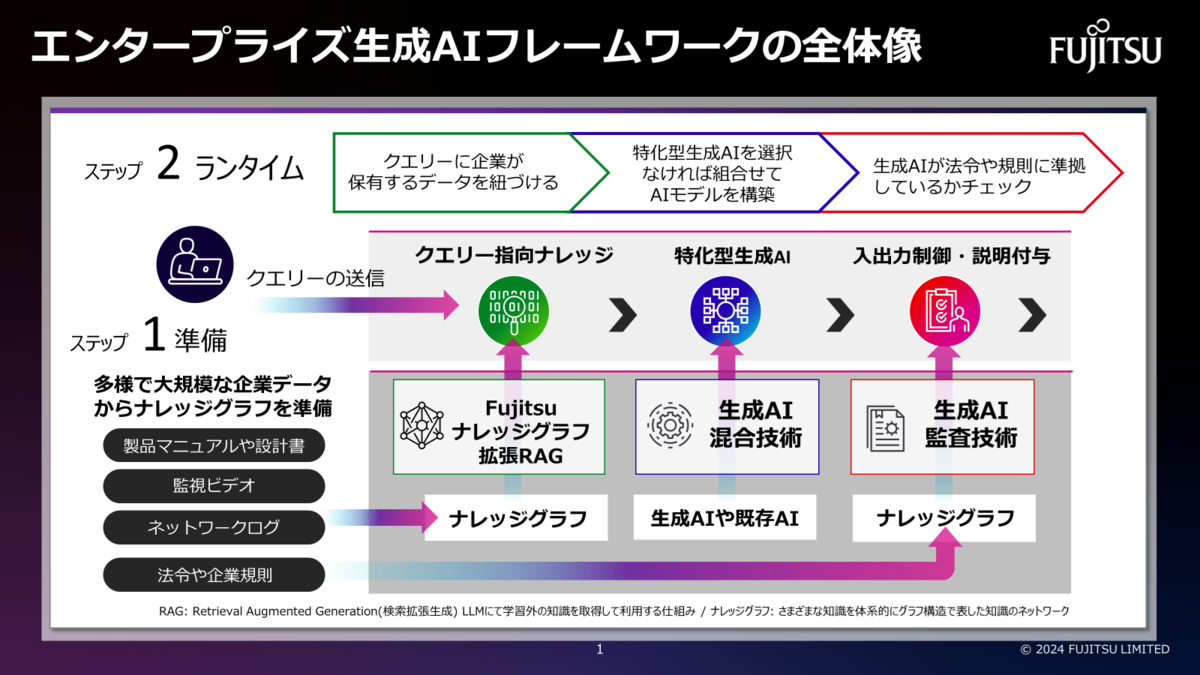
富士通では企業における生成AIの活用促進に向けて、多様かつ変化する企業ニーズに柔軟に対応し、企業が持つ膨大なデータや法令への準拠を容易に実現する「エンタープライズ生成AIフレームワーク」を開発し、2024年7月よりAIサービス「Fujitsu Kozuchi」のラインナップとして順次提供を開始いたしました。
本記事では、このフレームワークを構成する「Fujitsu ナレッジグラフ拡張RAG for Q&A」についてご紹介いたします。
エンタープライズ生成AIフレームワークは、企業のお客様が特化型生成AIモデルを活用する上で生じる、
- 企業で必要とされる大規模データの取り扱いが困難
- 生成AIがコストや応答速度をはじめとする多様な要件を満たせない
- 企業規則や法令への準拠が求められること
といった課題を解決する以下の技術群で構成されています。
- Fujitsu ナレッジグラフ拡張RAG技術*1
- 生成AI混合技術
- 生成AI監査技術
本連載では、上記のうち「Fujitsu ナレッジグラフ拡張RAG技術」についての技術紹介を連載形式にてさせていただきます。皆様の課題解決のヒントとなれば幸いです。また記事の最後には本技術を試す方法についてもお知らせいたします。
大規模データを正確に参照できない生成AIの弱点を克服するナレッジグラフ拡張RAG技術
生成AIに社内文書などの関連文書を参照させるための既存のRAG技術では、大規模データを正確に参照できない課題があります。我々はこの課題を解決するため、既存のRAG技術を発展させ、企業規則や法令、企業が持つマニュアル、映像などの膨大なデータを構造化するナレッジグラフを自動作成することで、従来は数十万、数百万トークン規模だったLLMが参照できるデータ量を1,000万トークン以上の規模に拡大できるナレッジグラフ拡張RAG技術(以下、Fujitsu KG拡張RAG技術)を開発しました。これにより、ナレッジグラフから関係性を踏まえた知識を生成AIに正確に与えることができ、論理推論や出力根拠を示すことが可能です。 本技術は対象となるデータや活用シーンに応じて、4つの技術から構成されます。

- Root Cause Analysis (公開中)
本技術はシステムのログや障害事例のデータをもとに、障害発生時のレポートを作成し、類似する障害事例をヒントに対策案を提示いたします。 - Question & Answer (本日公開)
本技術は製品マニュアルなどの膨大なドキュメントデータを対象に、全体を俯瞰した高度なQ&Aをおこなうことを実現します。 - Software Engineering (10/25頃公開予定)
本技術はソースコードをデータとして、ソースコードを理解するだけでなく上位の機能設計書や要約を生成、モダナイゼーションを可能にします。 - Vision Analytics (11/1頃公開予定)
本技術は映像データから、特定の事象や危険行為などを見つけ出し、対策の提示まで行うことが可能な技術です。
本記事では、Fujitsu KG拡張RAG for Q&Aについて詳しく紹介させていただきます。
Fujitsu KG拡張RAG for Q&A (Question Answer) ってどんな技術?
企業で生成AIを活用するためには企業が保有する多様で大量なデータの扱いが重要になってきます。通常、生成AIは企業固有のデータを学習していないため、生成AIの能力を外部データソースと組み合わせて拡張するRAG技術を利用しますが、この手法は回答精度が向上する一方で、情報の抽出が難しく、比較や推論が必要な質問に対して正答しづらいという欠点があります。
そこで複雑な質問でも答えられるよう、多数のテキスト文書中の重要な知識を構造化(ナレッジグラフ化)し、LLMに渡す手法が提案されています。
質問例.
OpenAIが開発した人工知能チャットボットとGoogleが開発した人工知能チャットボット、どちらのリリース日が早いですか?
この質問は、人間であればWikipediaなどの参考ドキュメントを確認することで答えることができます。しかしこのようなドキュメントは、特にビジネスシーンにおいて文章量が膨大かつ複雑な場合が多いです。
例えば上記質問に答えるためにWikipediaを検索すると、関連文章だけでも下記のようになります。
ChatGPT(チャットジーピーティー)は、OpenAIが2022年11月に公開した人工知能チャットボットであり、生成AIの一種。GPTの原語のGenerative Pre-trained Transformerとは、「生成可能な事前学習済み変換器」という意味である。OpenAIのGPT-3ファミリーの大規模な言語モデルに基づいて構築されており、教師あり学習と強化学習の両方の手法を使って転移学習され、機械学習のサブセットである深層学習を使って開発されている。
出典:Wikipedia(ChatGPT)より抜粋
Gemini(ジェミニ)、旧称Bard(バード)は、Googleが開発した生成型人工知能チャットボット。同名の大規模言語モデル(LLM)が使用されており、OpenAIのChatGPTの急速な普及に対抗する形で開発された。2023年3月21日にアメリカ合衆国とイギリスでリリースされ、その後5月に他の国々へ展開された。以前はPaLM、初期にはLaMDAシリーズの大規模言語モデルが使用されていた。
出典:Wikipedia(Gemini (チャットボット))より抜粋
このような大規模なドキュメントから回答に必要な情報だけをナレッジグラフ化できると、
{subject: “Google”, relation: “開発した”, object: “Gemini(ジェミニ)”}
{subject: “OpenAI”, relation: “公開した”, object: “ChatGPT(チャットジーピーティー)”}
{subject: “Gemini(ジェミニ)”, relation: “リリース”, object: “2023年3月21日”}
{subject: “ChatGPT(チャットジーピーティー)”, relation: “公開した”, object: “2022年11月”}
答えが一目瞭然になるでしょう。
Fujitsu KG拡張RAG for Q&Aはこのような、膨大かつ複雑なテキスト文書の中から重要な知識を自動的に構造化(ナレッジグラフ化)し、業務固有の情報を型を揃えて列挙し比較・推論することで、複雑な質問にも回答できるようにする技術です。
もっと詳しく!
本章では、Fujitsu KG拡張RAG for Q&Aの中でどのような処理を行っているのかご紹介します。
Step1. グラフスキーマの作成
Step2. 業務ドキュメントからナレッジ抽出
Step3. 質問特化ナレッジグラフの作成
Step4. Q&A
Step1. グラフスキーマの作成
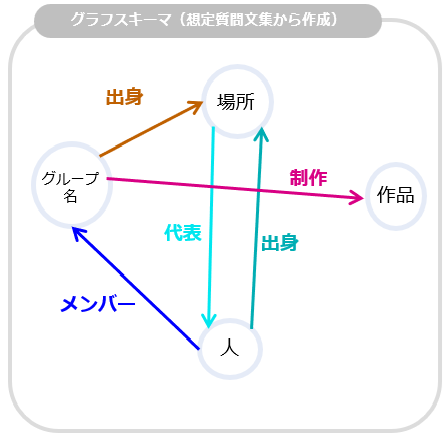
まずQ&Aの想定質問集からグラフスキーマを作成します。グラフスキーマとは、質問文からその特徴を抽出したナレッジグラフです。我々は、ある業務ドキュメントについて質問のパターンはある程度型が決まってくると考えています。例えば音楽のバンドに関する質問であればその構成メンバーやメンバーの国籍などの質問というように、参考にするデータが定まれば質問の傾向はある程度パターン化できます。
このアイデアを実現するために、Q&Aで用いられそうな想定質問文を用い、質問の「型」をグラフスキーマとして抽出します。
例えば、あるレコード会社のQ&Aシステムがあったとして、ユーザーが以下のような質問をよく行うとします。
- 「Aグループのメンバーは誰ですか?」
- 「Aグループの作曲した楽曲は何ですか?」
- 「Bさんの出身はどこですか?」
このような質問から抽象化した情報を取り出すことで、質問の特徴が得られます。
例.
Aグループ → <グループ名>
誰 → <人>
作曲した → <制作>
楽曲 → <作品>
Bさん → <人>
どこ → <場所>
これを図示すると、以下のようなグラフスキーマとなります。
Step2. 業務ドキュメントからナレッジ抽出
次に、業務ドキュメントからHyper-relational Knowledge Graph(以下、HRKG)を作成します。通常、ナレッジグラフはトリプル(ここでは、単純な文章を主語・述語・目的語の三つ組で構成したもの)で表現します。一方HRKGでは、ハイパートリプル(主語・述語・目的語のトリプルと、このトリプルの出典文書へのリンクからなる四つ組)で表現します。
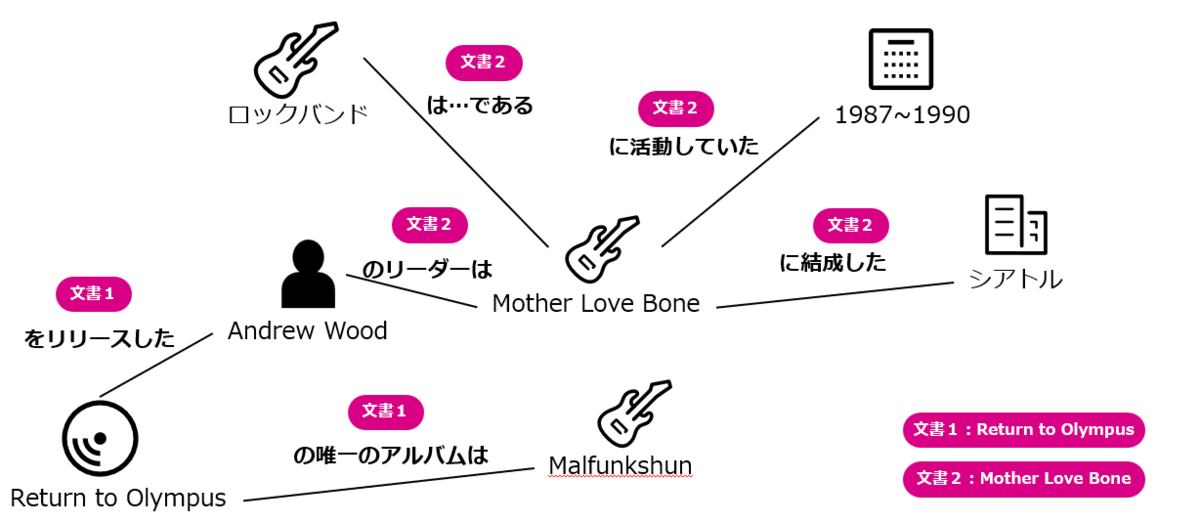
Point.
ハイパートリプルの出典文書へのリンクは、KG拡張RAGでQ&Aに回答できなかった場合の代替処理として利用され、Fujitsu KG拡張RAG for Q&Aの補助機能として活用します。
Step3. 質問特化ナレッジグラフの作成
ここでは、膨大なサイズのナレッジグラフから、回答に有益な部分を抽出します。
以下、次の質問文が入力された想定で説明を続けます。
質問例.
Andrew Woodがリードボーカルを担当するバンドはどこで結成されたか?
- 質問特化グラフスキーマを生成
質問とグラフスキーマを照合することで、質問のパターンを確認します。 そのためには、まず質問文からStep1と同等の手順でグラフスキーマを生成し、想定質問集から抽出したグラフスキーマと照合し、近いものを抽出します。
この作業により、想定質問のパターンから今回の質問に近いパターンを抽出することができ、質問特化のグラフスキーマとして活用します。
質問特化グラフスキーマの生成プロセス - 質問特化HRKGを抽出
生成された質問特化のグラフスキーマをHRKGと照合することで、HRKGの中から質問に関係の深いHRKGを質問特化(Query-aligned) HRKGとして抽出します。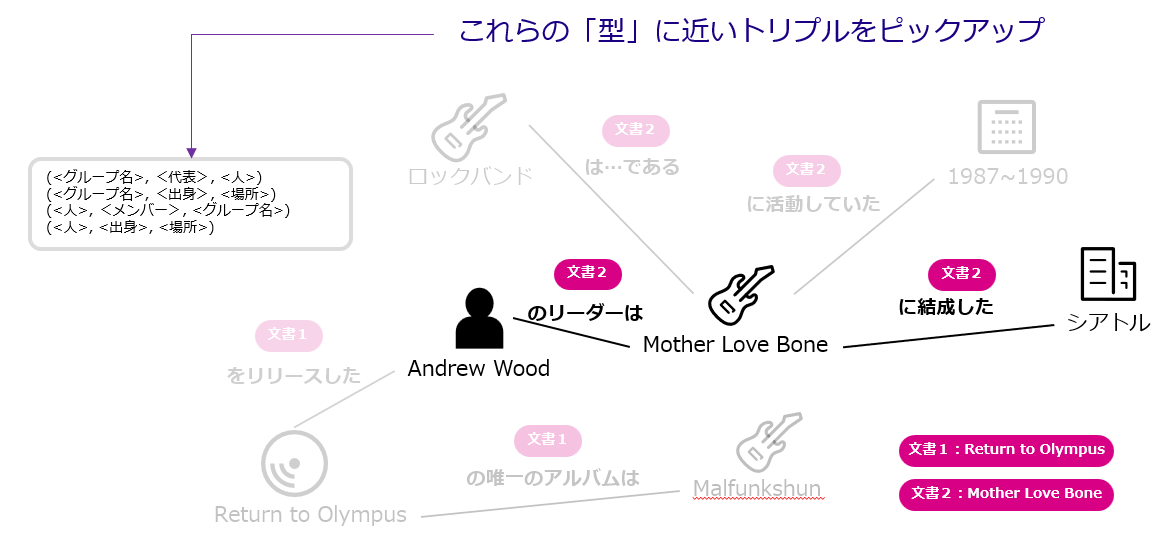
質問特化KGの例
Step4. Q&A
このステップでは、質問文と質問特化HRKGをLLMに渡し回答を取得します。
質問特化グラフスキーマとの照合によって回答に不要なトリプルを切り落とし、関係の深いトリプルのみをLLMに与えることで、回答精度を向上させることができます。
本質問例では「シアトル」が回答されます。
KG拡張RAG for Q&Aを試してみませんか
ここからはFujitsu KG拡張RAG for Q&Aを使ってみます。
主な手順は以下になります。
Step1. 質問に用いる業務ドキュメントからナレッジグラフを登録
Step2. 想定質問集からグラフスキーマを登録
Step3. チャット形式で質問
Step 1. 質問に用いる業務ドキュメントからナレッジグラフを登録
- 業務ドキュメントをアップロードします
業務ドキュメントはテキストの他、URLも指定できます。
この例では、Fujitsuのプレスリリース記事をデータとして登録しています。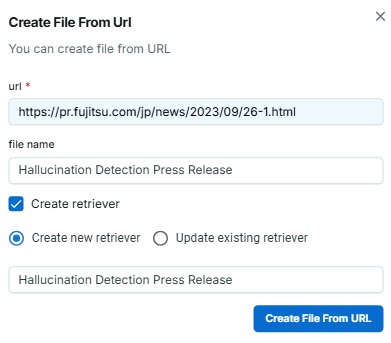
業務ドキュメントアップロード画面 - アップロードした業務ドキュメントからナレッジグラフを登録します
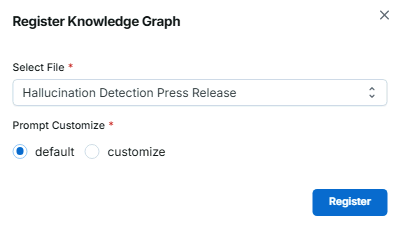
ナレッジグラフ登録画面
Point. プロンプトのカスタマイズ
ナレッジグラフを抽出するためのプロンプトはお客様の要望に合わせてカスタマイズすることができます。
Step 2. 想定質問集からグラフスキーマを登録
- 想定質問集をアップロード
※. この例では、デフォルトで用意している想定質問集をアップロードしました
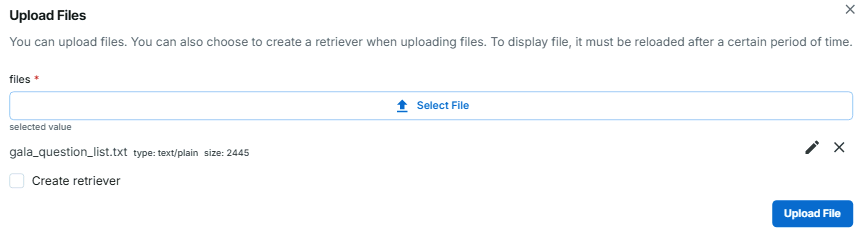
想定質問集アップロード画面 - アップロードした想定質問集を元にグラフスキーマを登録
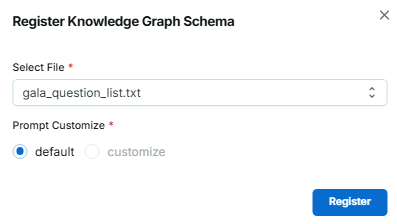
グラフスキーマ登録画面
Step 3. チャットを開始する
ここまでで事前準備を完了しました。
ここからはいよいよチャットを開始します。
- チャットスレッドを開く
登録したナレッジグラフとグラフスキーマを指定し、チャット用のスレッドを開きます。
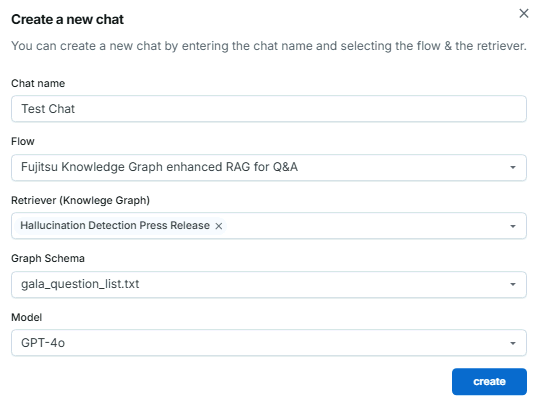
チャット作成画面 - チャット
業務ドキュメントに関する質問として、「幻覚検出技術と同時にリリースされた技術の共同研究先はどこですか?」 と聞いてみます。
この質問は意図的に以下の点で複雑な質問としています。- 幻覚検出チェック技術と同時にリリースされた技術がわかる必要がある
- その技術の共同研究先がわかる必要がある
正解は『ベングリオン大学』となります。
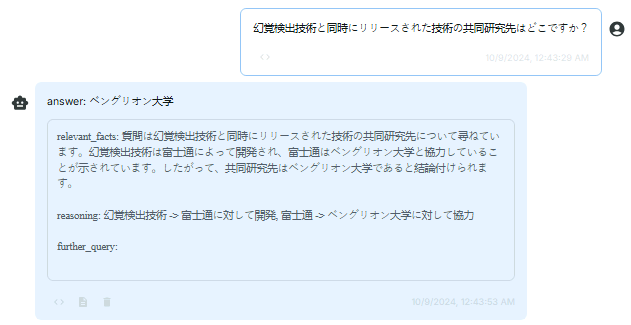
Point.
プレスリリースの記事に以下が記載されており、回答が根拠のある内容であることが分かります。
そこで当社は、対話型生成AIの回答文に含まれるURL情報がフィッシングURLかどうかを判定して利用者へ画面上で提示する技術を開発しました。本技術は、フィッシングURLを特定するだけでなく、近年問題視されているAIの判断を故意に誤らせる既存の敵対的攻撃にも対応させることで、信頼性の高い判定を実現しています。この攻撃対策技術には、当社がBen-Gurion University of the Negev(注5)(以下、ベングリオン大学)に設置した「富士通スモールリサーチラボ」(注6)で共同開発した技術を活用しており、…
さらにKG拡張RAG for Q&Aでは、回答根拠の1つとして回答に利用したトリプルを参照する機能があります。
ここからも、実際に業務ドキュメントをしっかり認識している事がわかりますね。

Fujitsu ナレッジグラフ拡張RAG for Q&Aの技術を試すには
Fujitsu ナレッジグラフ拡張RAG for Q&Aでは、ナレッジグラフを上手く活用し、高精度に質問に回答する事が出来ます。
業務での活用にご興味を持たれた方はこちらのサイト の「問い合わせはこちら」からご連絡いただければと思います。
その効果をぜひみなさんに活用していただきたいです。
*1:RAG技術:Retrieval Augmented Generation。生成AIの能力を外部データソースと組み合わせて拡張する技術