
こんにちは。人工知能研究所の菊月です。
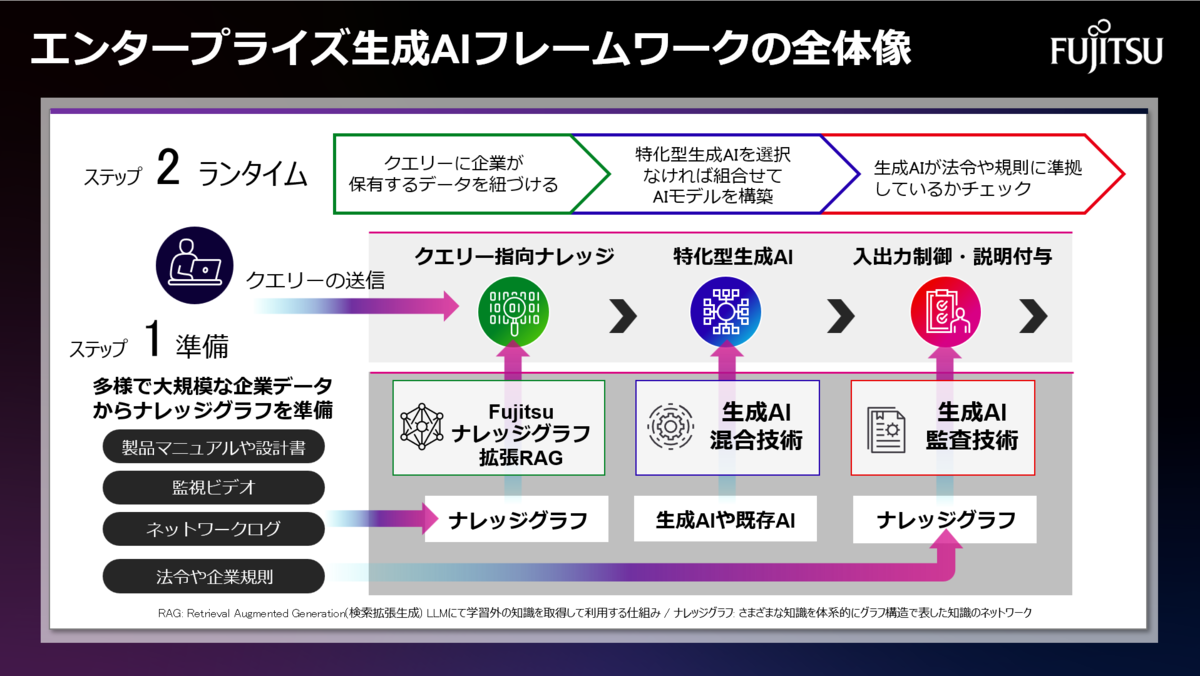
富士通では企業における生成AIの活用促進に向けて、多様かつ変化する企業ニーズに柔軟に対応し、企業が持つ膨大なデータや法令への準拠を容易に実現する「エンタープライズ生成AIフレームワーク」を開発し、2024年7月よりAIサービス Fujitsu Kozuchi (R&D) のラインナップとして順次提供を開始いたしました。
本記事では、このフレームワークを構成する「Fujitsu ナレッジグラフ拡張RAG for RCA (Root Cause Analysis)」についてご紹介いたします。(*1)
エンタープライズ生成AIフレームワークは、企業のお客様が特化型生成AIモデルを活用する上で生じる、
- 企業で必要とされる大規模データの取り扱いが困難
- 生成AIがコストや応答速度をはじめとする多様な要件を満たせない
- 企業規則や法令への準拠が求められること
といった課題を解決する以下の技術群で構成されています
- Fujitsu ナレッジグラフ拡張RAG技術
- 生成AI混合技術
- 生成AI監査技術
本連載では、上記のうち「Fujitsu ナレッジグラフ拡張RAG技術」についての技術紹介を連載形式にてさせていただきます。皆様の課題解決のヒントとなれば幸いです。また記事の最後には本技術を試す方法についてもお知らせいたします。
大規模データを正確に参照できない生成AIの弱点を克服する Fujitsu ナレッジグラフ拡張RAG技術
生成AIに社内文書などの関連文書を参照させるための既存のRAG技術では、大規模データを正確に参照できない課題があります。我々はこの課題を解決するため、既存のRAG技術を発展させ、企業規則や法令、企業が持つマニュアル、映像などの膨大なデータを構造化するナレッジグラフを自動作成することで、従来は数十万、数百万トークン規模だったLLMが参照できるデータ量を1,000万トークン以上の規模に拡大できる Fujitsu ナレッジグラフ拡張RAG(以下、KG拡張RAG)技術を開発しました。これにより、ナレッジグラフから関係性を踏まえた知識を生成AIに正確に与えることができ、論理推論や出力根拠を示すことが可能です。
本技術は対象となるデータや活用シーンに応じて、5つの技術から構成されます。また、これら技術群で構築したナレッジを公開・共有する取り組み紹介とあわせて、計6回の連載となっています。
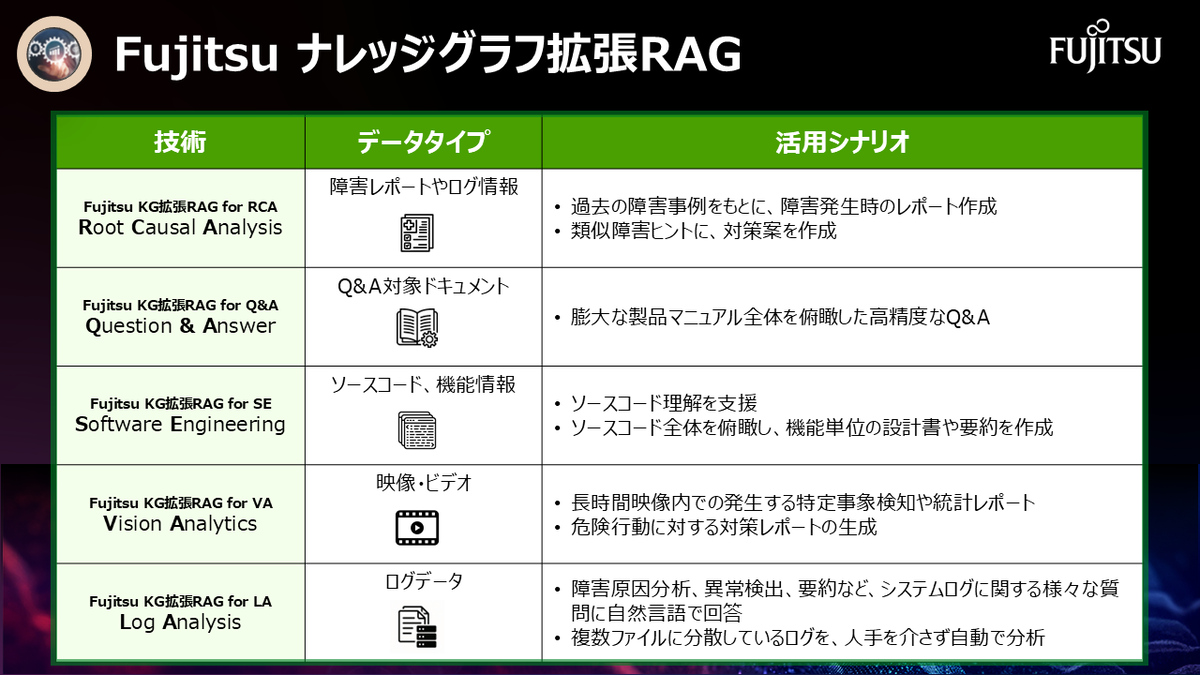
(1) Root Cause Analysis (本記事)
本技術はシステムのログや障害事例のデータをもとに、障害発生時のレポートを作成し、類似する障害事例をヒントに対策案を提示いたします。
(2) Question & Answer (公開中)
本技術は製品マニュアルなどの膨大なドキュメントデータを対象に、全体を俯瞰した高度なQ&Aをおこなうことを実現します。
(3) Software Engineering (公開中)
本技術はソースコードをデータとして、ソースコードを理解するだけでなく上位の機能設計書や要約を生成、モダナイゼーションを可能にします。
(4) Vision Analytics (公開中)
本技術は映像データから、特定の事象や危険行為などを見つけ出し、対策の提示までおこなうことが可能な技術です。
(5) Log Analysis (公開中)
本技術はシステムログのファイルを自動で分析し、障害の原因特定や異常検知、予防保守に関する専門性の高い質問に回答することが可能な技術です。 https://blog.fltech.dev/entry/2026/03/31/kgpub-jp
(6) ナレッジ公開 (公開中)
上記のFujitsu KG拡張RAGで構築したナレッジを、実際の業務や研究で活用できる形で公開・共有していく取り組みです。
本記事では、(1) Root Cause Analysis(以下、RCA)について詳しく紹介させていただきます。
KG拡張RAG for RCAについて
障害原因分析って何が嬉しいの?
本技術は、Root Cause Analysis、つまり障害原因分析を可能にする技術です。まず、障害原因分析がどういう場面で活用できるか、なぜ実現できたら嬉しいのか、について説明します。
身近な障害というと、例えば「Wi-FiをONにしたのに繋がらない」といったスマホ・PCでのトラブルや、「洗濯乾燥機を動かしたのに全然乾いてない」といった電化製品のトラブルがありますね。大抵は、インターネットで事象やエラーコードを入力して検索したり、マニュアルの記載を読み込んだりして、見つかった解決策を試す、または故障だから買い替える、といった方策で対処が完了すると思います。
しかし、業務における障害というと、そう簡単に対処できるわけではありません。例えば、大規模ネットワーク運用、クラウドシステム運用、プラント保全などでは、システムや機器の構成が複雑なため、障害が起きたかどうか、起きたとして発生箇所はどこか、といった事を検出する事がまず困難です。そして、その障害原因分析となると更に困難で、例えばネットワークで送受信エラーや遅延などが発生したとしても、ハードウェアの劣化や設定ミス、一時的なトラフィック増加など、関連する事象が多すぎて特定は困難です。一方で、大規模なシステムになると一度の障害で数十億円の損害が発生するといった事例も実際にあり、ビジネスへの影響が甚大になる可能性があります。そのため、いかに障害を予防するか、または障害復旧を迅速にするか、が重大課題となっています。現状は多岐にわたる障害原因の分析・調査に専門家が多大な工数をかけている事も多く、専門家の人手不足解消や、障害レスな運用を目指して、障害原因分析の自動化および支援技術に対する要望が非常に大きくなっています。
KG拡張RAG for RCAで障害原因分析はどう変わるの?
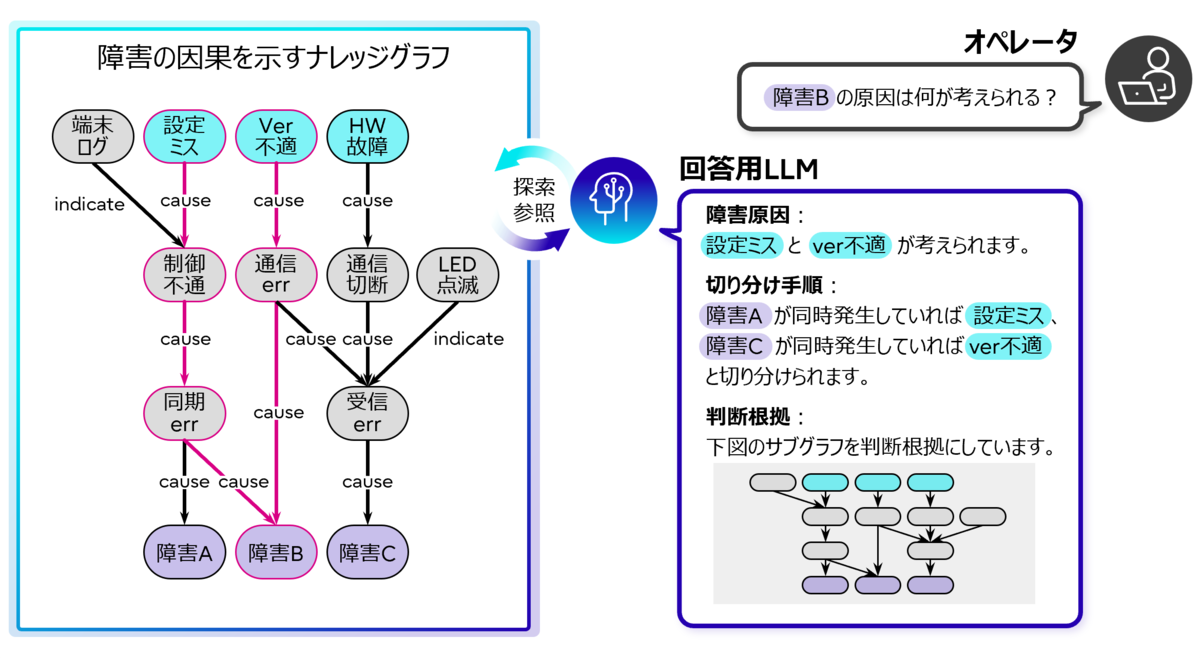
KG拡張RAG for RCAを使うと、障害事例文書やシステム仕様書などの膨大なドキュメントの記載を自動分析し、システム構成や障害が発生する複雑な因果関係を自動抽出する事ができます。その結果、「因果ナレッジグラフ」と呼称するグラフ構造を自動構築でき、この因果ナレッジグラフとLLM(e.g. GPT-4、Takane(*2))を用いる事で迅速な障害原因分析が実現できます。例えば「通信が切断してしまう障害の原因は何?」と自然言語で記載するだけで、高精度な障害原因候補の回答を得られるだけではなく、「ログを確認してXXだったら設定ミス、YYという障害も発生していたらファームウェアのバージョンが不適と考えられます」といったように切り分け手順等を提示する事も可能になります。これによって、専門家が大量のドキュメントを読んで分析・調査をする代わりに即座に調査結果を得られるようになるうえ、より網羅的で手戻りのない復旧手順も得られるため、障害復旧までの時間を大幅に短縮する事ができます。
既存技術の課題は?
障害原因分析の自動化および支援技術に対する要望は大きいため、これまでも様々な技術開発が行われてきました。代表的なアプローチはルールベースの手法(*3)と、RAGベースの手法(*4)です。
ルールベースの手法は、事前に専門家が定義したルール・分類に沿って障害を分類するアルゴリズムやAI技術となっており、事前に定義できるルール・分類の種類に限界がありました。特に近年はシステムが複雑化していっており、本手法の延長では対応できないケースが増えていました。
RAGベースの手法は、膨大な障害事例文書とRAGを用いて障害原因分析を自動化するものです。ルールベースの手法と異なり、障害事例が蓄積されていくにつれて自動で回答の質も上がっていくため、複雑化したシステムにおいてもある程度は対応する事ができます。しかし、上図に示した「障害の因果を示すナレッジグラフ」のように、様々な事象間に複雑な因果関係があるにも関わらず、RAGベースの手法では事例毎に断片的に解析する事しかできません。そのため、過去に起きた障害と全く同一の障害原因を提示するくらいしかできませんでした。
以上のように、既存技術のアプローチでは、複雑な因果関係を考慮した網羅的な障害原因分析ができないという点が課題でした。
どうやってKG拡張RAG for RCAを実現してるの?
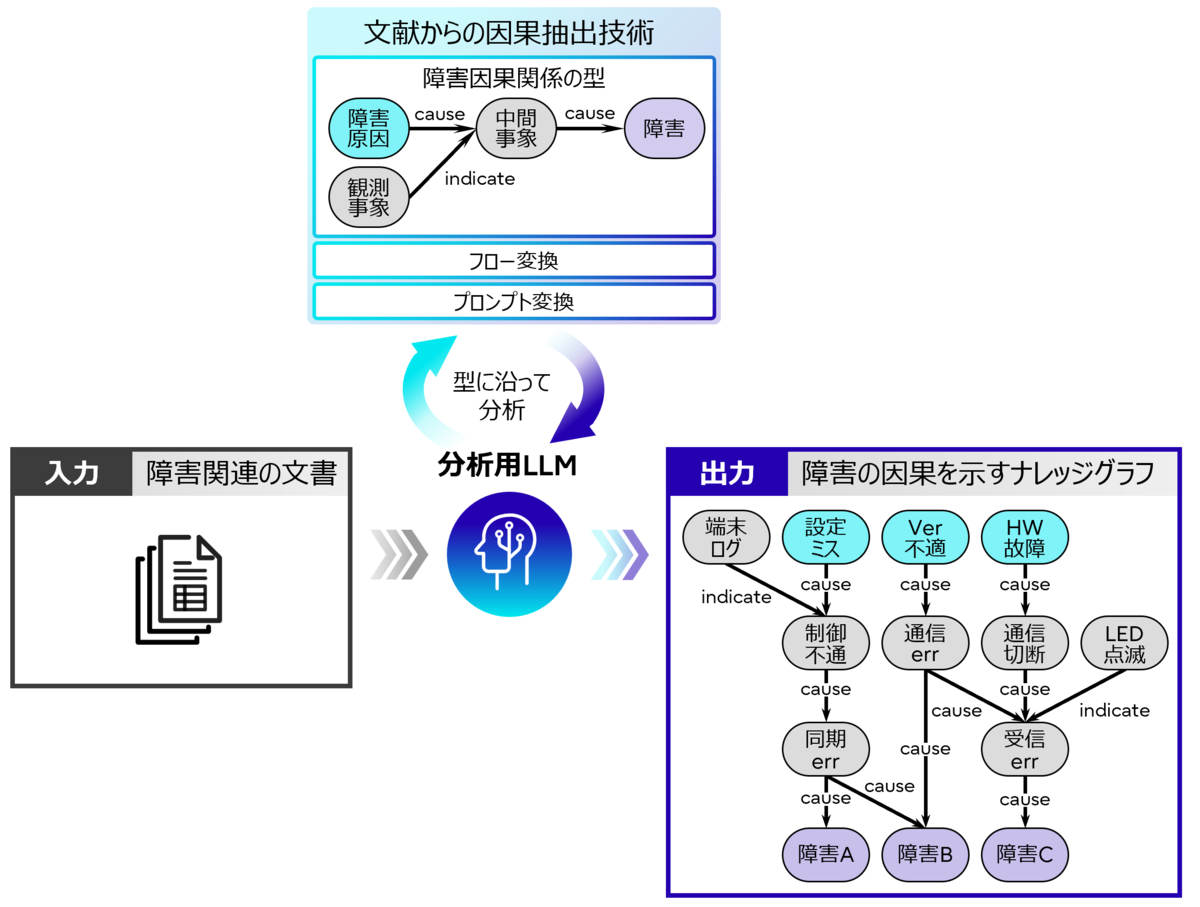
既存技術の課題を解決するために我々が提唱したのが因果ナレッジグラフで、これを用いて複雑な因果関係を分析し、網羅的に質の高い障害原因分析をしたり、更に切り分け手順等も提示したり、といった事を可能にしています。KG拡張RAG for RCAの最も大きな特徴は、この因果ナレッジグラフの自動構築手法にあります。
従来、ナレッジグラフは人手で膨大な時間をかけて作成するものでしたが、日々増えていく障害事例に人手をかけ続ける事は現実的ではありません。LLMの出現によりナレッジグラフ作成を自動化するOSS(*5)もありますが、文書内の名詞やその関係性を網羅的に抽出する事しかできません。そのようなナレッジグラフを活用しても「Primergyの最大HDD容量はいくつ?」といったクイズのような質問への回答はできますが、障害の因果関係と関係ない文言が抽出されたり、事象の言い換えなどによって因果関係が分離されたりしているため障害原因分析には適用できず、因果ナレッジグラフの自動構築技術の開発が必要でした。
そこで我々は、事象間の因果関係を抽出するため、LLMの着眼点を適切に誘導する世界初の技術を確立しました。我々が着目したのは、障害の因果関係において「障害原因があって、障害があって、その間にいくつかの中間的な事象があって、・・・」というように事象間の関係性にある程度の型が存在する、という点です。そして、この障害因果関係の構造の型を「ナレッジグラフスキーマ」と呼称するグラフ構造で事前に定義しておき、そのナレッジグラフスキーマに沿って入力文書を分析するフレームワークを開発しました。本フレームワークは、ナレッジグラフスキーマを処理フローに自動変換するフロー変換技術と、具体的なLLM指示プロンプトに自動変換するプロンプト変換技術によって構成されています。これによって、因果ナレッジグラフの自動構築を可能としました。
KG拡張RAG for RCAを試してみませんか
本技術は、富士通が研究開発した先端AI技術を迅速に試すことができるプラットフォームFujitsu Kozuchiにおいて、コア技術単位のソフトウェア部品「AIコアエンジン」の一つという位置付けで、"Fujitsu ナレッジグラフ拡張RAG for Root Cause Analysis"という名称のWebアプリとしてリリースされています。
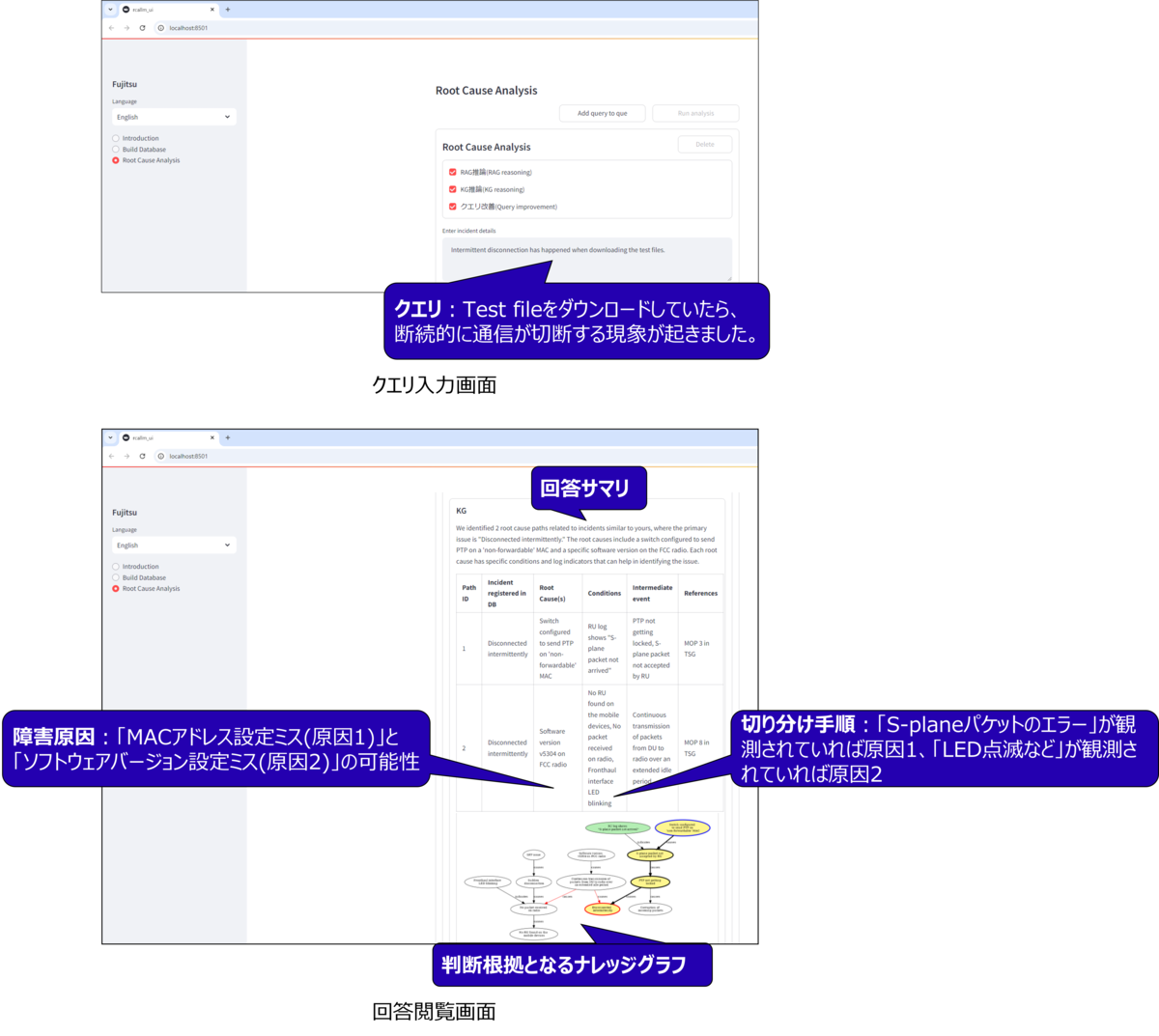
下図は本Webアプリの画面例を示しています。障害事例文書やシステム仕様書などのドキュメント類を登録後、「クエリ入力画面」にあるように障害事象の内容を自然言語で記載するだけで、「回答閲覧画面」のように障害原因分析結果を即座に得る事ができます。 障害原因分析にお困りの方は是非ご利用ください!
関連記事
- 本記事で紹介したKG拡張RAG for RCAを活用した技術に関する記事
*1:RAG技術:Retrieval Augmented Generation。生成AIの能力を外部データソースと組み合わせて拡張する技術。
*2:Takane: 富士通とCohereで共同開発した、世界一の日本語性能を持つ企業向け大規模言語モデル。プレスリリースはこちら。
*3:ルールベースの手法:例えば、特開2011-171981など。
*4:RAGベースの手法:例えば、Y. Chen et.al., “Automatic Root Cause Analysis via Large Language Models for Cloud Incidents,” arXiv:2305.15778, 2023など。
*5:ナレッジグラフ作成の自動化:例えば、LangChainのLLMGraphTransformerライブラリなど。