
こんにちは。人工知能研究所の溝渕です。
富士通では企業における生成AIの活用促進に向けて、多様かつ変化する企業ニーズに柔軟に対応し、企業が持つ膨大なデータや法令への準拠を容易に実現する「エンタープライズ生成AIフレームワーク」を開発し、2024年7月よりAIサービス Fujitsu Kozuchi (R&D) のラインナップとして順次提供を開始いたしました。
本記事では、このフレームワークを構成する「 Fujitsu ナレッジグラフ拡張RAG for SE(Software Engineering)」についてご紹介いたします。(*1)
エンタープライズ生成AIフレームワークは、企業のお客様が特化型生成AIモデルを活用する上で生じる、
- 企業で必要とされる大規模データの取り扱いが困難
- 生成AIがコストや応答速度をはじめとする多様な要件を満たせない
- 企業規則や法令への準拠が求められること
といった課題を解決する以下の技術群で構成されています。
- Fujitsu ナレッジグラフ拡張RAG技術
- 生成AI混合技術
- 生成AI監査技術
本連載では、上記のうち「Fujitsu ナレッジグラフ拡張RAG技術」についての技術紹介を連載形式にてさせていただきます。皆様の課題解決のヒントとなれば幸いです。また記事の最後には本技術を試す方法についてもお知らせいたします。
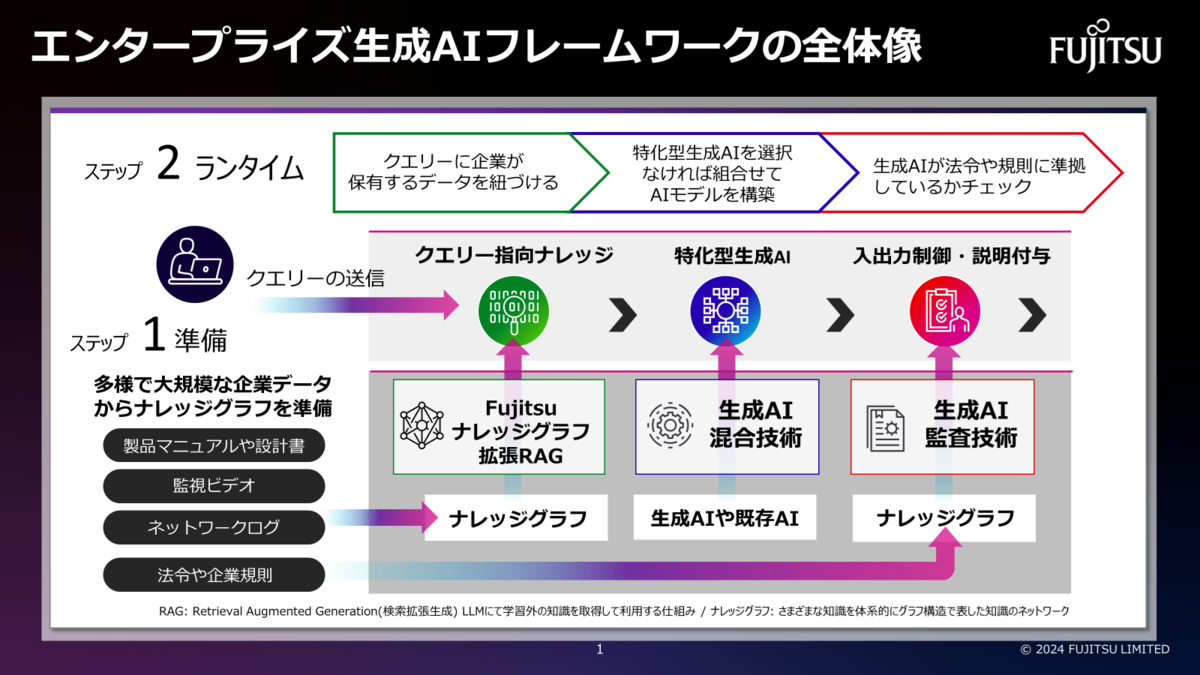
大規模データを正確に参照できない生成AIの弱点を克服する Fujitsu ナレッジグラフ拡張RAG技術
生成AIに社内文書などの関連文書を参照させるための既存のRAG技術では、大規模データを正確に参照できない課題があります。我々はこの課題を解決するため、既存のRAG技術を発展させ、企業規則や法令、企業が持つマニュアル、映像などの膨大なデータを構造化するナレッジグラフを自動作成することで、従来は数十万、数百万トークン規模だったLLMが参照できるデータ量を1,000万トークン以上の規模に拡大できる Fujitsu ナレッジグラフ拡張RAG技術を開発しました。これにより、ナレッジグラフから関係性を踏まえた知識を生成AIに正確に与えることができ、論理推論や出力根拠を示すことが可能です。
本技術は対象となるデータや活用シーンに応じて、5つの技術から構成されます。また、これら技術群で構築したナレッジを公開・共有する取り組み紹介とあわせて、計6回の連載となっています。
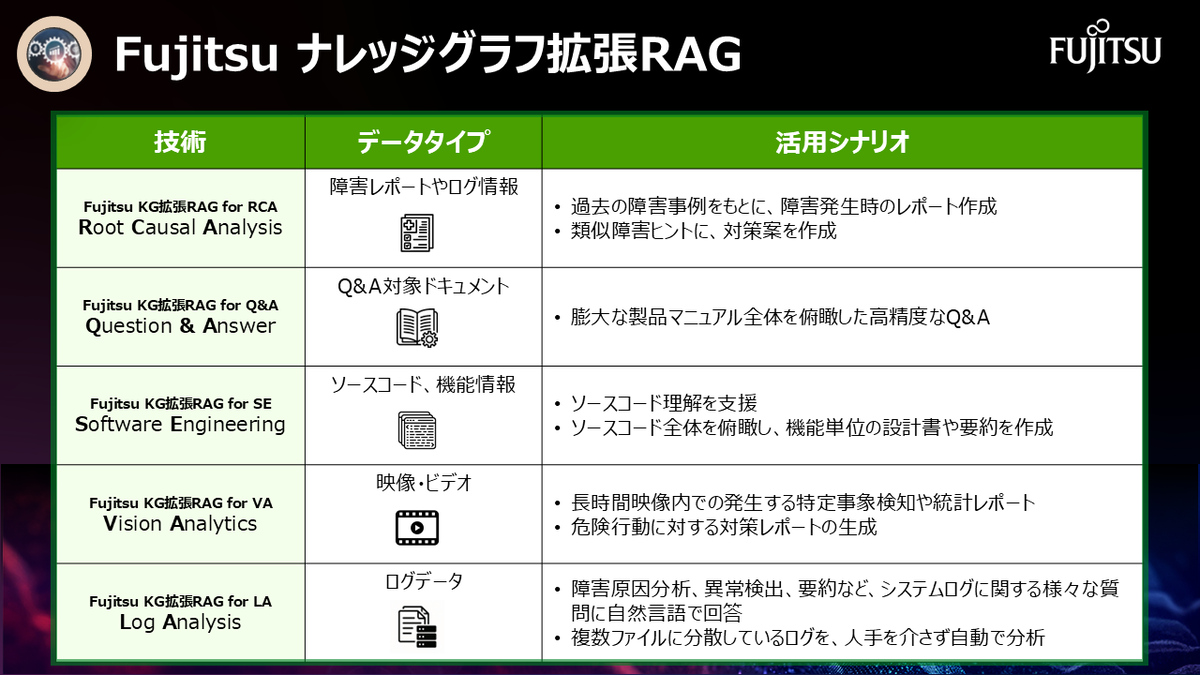
- Root Cause Analysis (公開中)
本技術はシステムのログや障害事例のデータをもとに、障害発生時のレポートを作成し、類似する障害事例をヒントに対策案を提示いたします。 - Question & Answer (公開中)
本技術は製品マニュアルなどの膨大なドキュメントデータを対象に、全体を俯瞰した高度なQ&Aをおこなうことを実現します。 - Software Engineering (本記事)
本技術はソースコードをデータとして、ソースコードを理解するだけでなく上位の機能設計書や要約を生成、モダナイゼーションを可能にします。 - Vision Analytics (公開中)
本技術は映像データから、特定の事象や危険行為などを見つけ出し、対策の提示まで行うことが可能な技術です。 - Log Analysis (公開中)
本技術はシステムログのファイルを自動で分析し、障害の原因特定や異常検知、予防保守に関する専門性の高い質問に回答することが可能な技術です。 - ナレッジ公開 (公開中)
上記のFujitsu KG拡張RAGで構築したナレッジを、実際の業務や研究で活用できる形で公開・共有していく取り組みです。
本記事では、 Fujitsu ナレッジグラフ拡張RAG for SE(Software Engineering)について詳しく紹介させていただきます。
Fujitsu ナレッジグラフ拡張RAG for SEってなに?
みなさん、これまでにソフトウェア開発を経験されたことはありますか?ものをつくることはとても楽しいことですが、ソフトウェア開発には他人が書いたコードを理解することや、コード改変の影響箇所を特定することなど、地味で骨の折れる作業がたくさんあります。実はLLMを使うと、こういった作業を楽にすることができます。LLMはとても賢く、一度に複数のコードを読み込み、コード間の関係性を考慮しながら、不明瞭な変数の意味も類推して高度に理解・解説してくれます。他にも、コード生成、コード変換、テストケース生成などにも活用でき、LLMの可能性は無限です。もちろん、LLMの生成内容をすべて鵜呑みにすることはできないため、人の作業が完全になくなるわけではありませんが、現状のソフトウェア開発にかかる作業を大幅に削減できます。
こういったソフトウェア開発におけるLLMの利点を、大規模なITシステムで活用することを目的に進められているのが、Fujitsuのナレッジグラフ拡張RAG for SEです。言うまでもありませんが、昨今のITシステムは企業経営の要となっており、継続的なモニタリングや全容把握をベースに、アジャイルな保守改修の実現が長年求められています。しかし、レガシーシステムをはじめとする多くのシステムでは、技術者不在、ベンダーサポート終了、設計書なし、といった厳しい状況に直面しており、理想的なシステムマネジメントの姿からはほど遠い状況です。こういった状況を打開すべく、Fujitsuのナレッジグラフ拡張RAG for SEは、現行資産の理解を通じて意思決定を支援することを目的に研究開発が進められています。
Fujitsu ナレッジグラフ拡張RAG for SEはどんな仕組みなの?
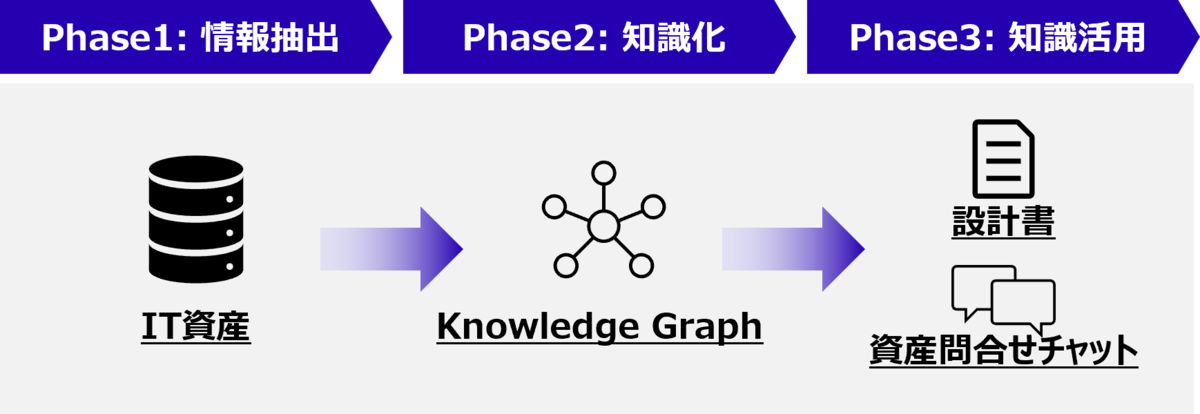
ここではFujitsu ナレッジグラフ拡張RAG for SEの仕組みを解説したいと思います。図1は本フレームワークの全体像です。本フレームワークは3つのフェーズから構成されており、それぞれIT資産からの情報抽出、知識化、知識活用という役割を担っています。各フェーズでは、LLMを中核に据え、必要に応じて既存のツールを活用し、目的に応じたデータ処理を行います。以降、各フェーズに関して詳しく説明していきます。
Phase 1. 情報抽出
Phase 1では、IT資産から資産理解に有用な情報を抽出します。情報抽出の流れは図2の通りです。IT資産には業務フローやマニュアルなどの業務情報、ITシステムの実行ログなどの稼働情報、そしてソースコードを想定しています。そこから抽出する情報としては、業務フロー、設計情報、フロー情報(制御フロー、データフローなど)や関数・ファイル間の呼出関係などを想定しています。これら情報を極力決定的で正確な実行結果が必要な場合は、従来の解析ツールを用いることになります。一方、多少の不正確さが許容される場合には、業務観点を考慮した結果を出すためにLLMを用います。両者の強みを活かした情報抽出を行うことが、本フレームワークの一つの特徴と言えます。
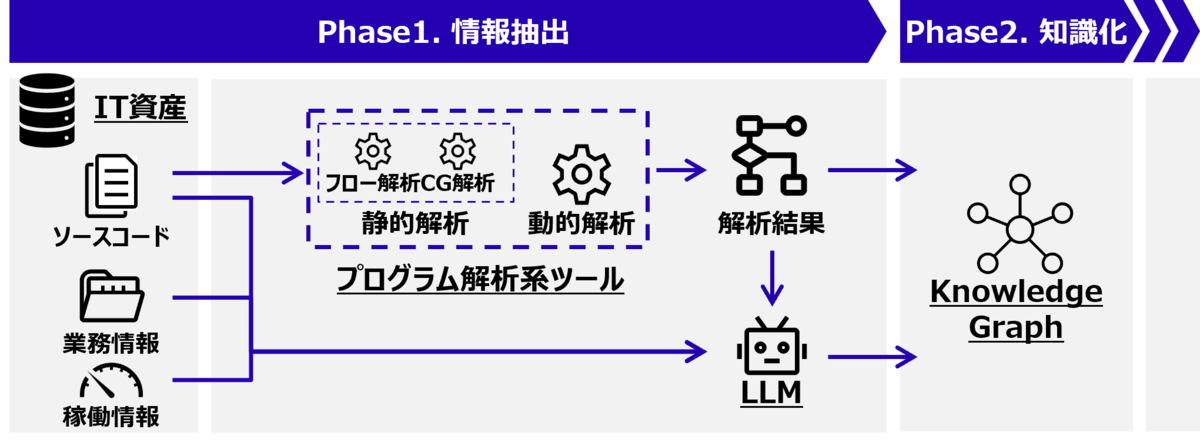
なお、フロー情報や呼出関係は、LLMによる設計情報生成で有効であることが実験的に分かっており、レガシーコードなどでよくみられる可読性の低いソースコードで特に有効です。この点については以降で解説します。
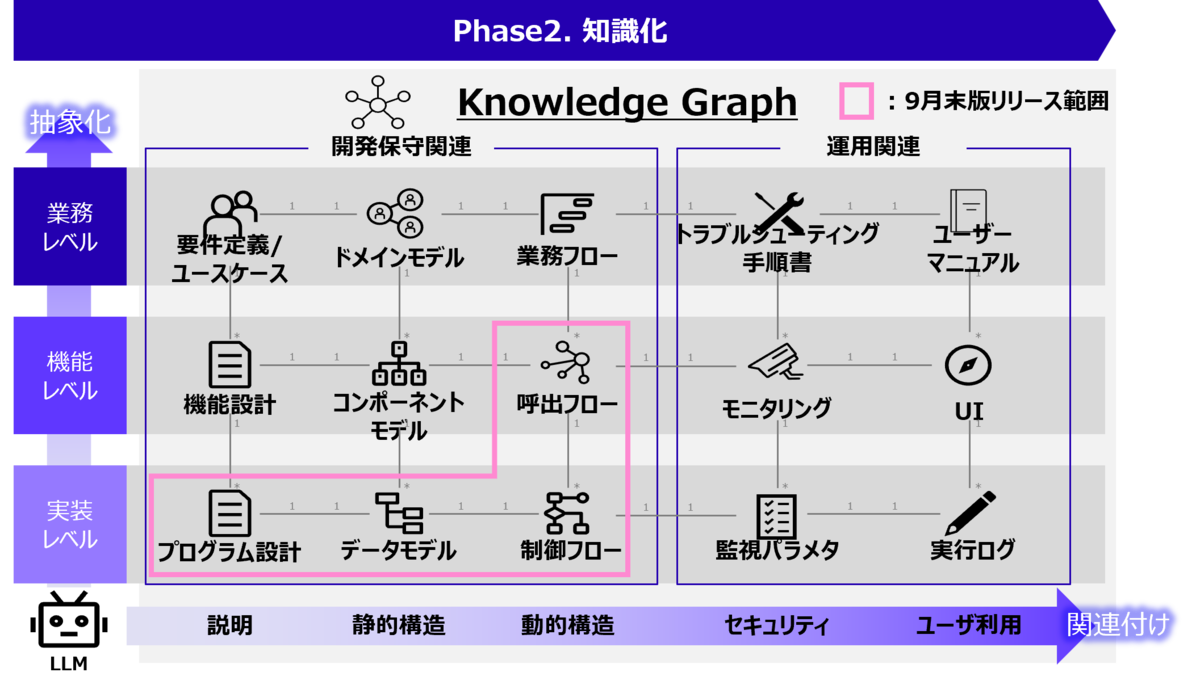
Phase 2. 知識化
Phase 2では、Phase 1でIT資産から集めた情報に基づき、あらかじめ規定したスキーマに従って情報を整理・補完します。図3に示すように、想定される関連情報は多岐にわたり、Phase 3での知識活用を見据えて、網羅的に準備しておきたいところです。ITシステムには様々なステークホルダーが存在し、それぞれの立場や状況に応じて必要とする情報は異なってきます。そのため、Phase 1の情報だけではなく、足りない情報は多角的・多面的な分析に基づいて補完する必要があります。業務レベル、機能レベル、実装レベルといった異なる抽象レベルでの汎化や具体化、および異種の情報の関連付けをLLMによって実現します。
Phase 3. 知識活用
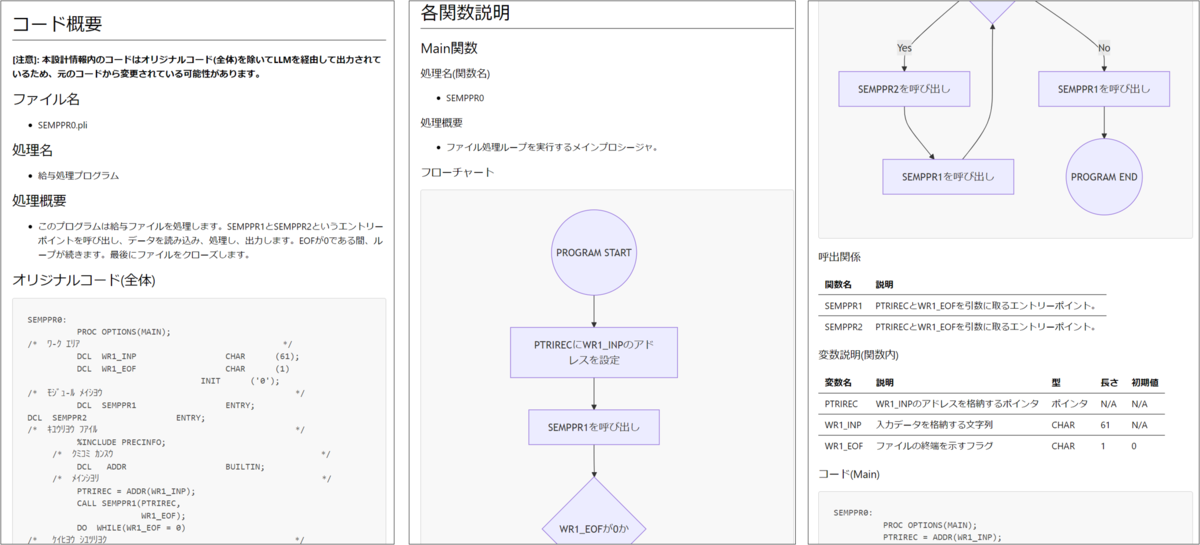
Phase 3ではPhase 2で構築した知識を目的ごとのアプリケーションを使って、各ステークホルダーのニーズに応えます 。現段階では各種情報のドキュメント化や、各種情報をチャット形式で問い合わせるような仕組みの導入を検討しています。図4はFujitsu ナレッジグラフ拡張RAG for SE(9/30公開版)で作成した給与支給集計計表作成コード*2のプログラム設計書です。なお、この給与支給集計表作成コードを改変したものを以降の説明で使用しています。また、本機能の使い方は本ブログの末尾に記載していますので、最後までご覧ください。
設計情報生成の技術ポイントは?
ここからは、Fujitsu ナレッジグラフ拡張RAG for SE(9/30公開版)の設計情報生成について、技術的な工夫点をお伝えします。
LLMを使った設計情報生成の課題
そもそも設計情報生成においては、従来からルールベースのツールが存在しました。これはプログラムの制御構造に応じたテンプレートを用意し、そこに変数などの可変な情報を当てはめるものでした。あくまでコードが行う処理の内容をそのまま自然言語に書き直したものであり、業務レベルの抽象度で記載することはできませんでした。
これに対し、LLMはコードだけでなく変数名やコメント文も参考にすることができるため、これらをヒントに業務レベルの処理内容を記述できるようになっています。逆にコメントや変数名が不明瞭なコードでは、業務を考慮した設計情報生成は難しく、レガシーコードからの設計情報生成が難しい理由の一つになっています。図5は給与支給集計計表作成コードを、コメントや変数名を分かりやすくしたもの(左)と、コメントや変数を略記したもの(右)の例です。右のコードは左に比べ、理解しにくくなっているかと思います。LLMにおいても、活用できる情報が少なくなるとその分コード理解が難しくなり、結果的に生成物の品質が低下します。

アプローチ
こういった課題に対してFujitsu ナレッジグラフ拡張RAG for SEではプログラム解析技術を用いた設計情報生成を行っています。コードに対しフロー解析や呼出関係解析を予め実行し、解析結果をLLMの設計情報生成プロンプトに組み込むことでコードの内容理解に役立てる、というものです。具体的な流れは図6の通りです。プログラマもコード理解をするとき、変数や制御の流れを追って具体的な処理内容を理解しつつ、コードの全体像を把握していると思います。これはデータフロー解析や制御フロー解析といったフロー解析とほぼ同等の分析をプログラマ自身で行っていると言えます。また、あるコードを読んでいて理解が進まないとき、そのコードが呼出しているコードを読んで理解が深まる、ということもあります。これは呼出関係解析とほぼ同等の分析を行っていると言えます。このような経験をLLMでの生成にも利用することで高品質化を図っています。

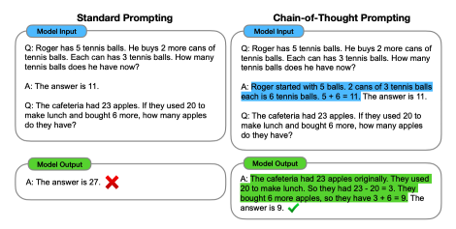
ちなみに一般的にLLMにタスクを解かせるときはタスクを細分化し段階的に解かせることで精度改善することが報告されており*3、このようなプロンプティング手法をChain of Thought(CoT)といいます。CoTを提案した論文では、ロジャーが持っているテニスボールの数を求める方法を、細分化・段階的に計算する方法へ置きなおす例が挙げられています(図7)。同様に本フレームワークでは、一足飛びに設計情報生成するのではなくプログラム解析を事前に行うことで段階的な理解を行えるようにしました。
なお、図5の低可読コードを用いて、データフロー解析、制御フロー解析、呼出関係解析の例を図8で示します。データフロー解析では各変数の定義箇所と利用箇所の列挙、制御フロー解析では実行パスの列挙、呼出関係解析ではコードから呼び出される関数の列挙が行われています。

改善例
最後にプログラム解析の有無で生成される設計情報がどう変わるかを示したいと思います。図9は賞与支給ファイル作成コード*4を低可読化し設計情報生成を行った結果です。設計項目としてプログラム名、処理概要、入力レコードのスキーマ(項目名)、入力例、出力レコードのスキーマ(項目名)、出力例としました。いかがでしょうか。プログラム解析"なし"の生成結果に比べ、"あり"の方がコードの意味を理解した設計情報が生成できていると思いませんか?プログラム解析"なし"の場合では、実装レベルの抽象度で記載されており、得られる効果はコードをそのまま読むのとほとんど変わらないと思われます。一方、"あり"の方では業務観点を考慮した設計情報になっており、入力項目や出力項目が賞与計算に関連するもので構成されています。恐らくフロー解析や変数の桁数などから賞与計算によくある処理パタンと判断できたと考えられます。また手元の実験ではプログラム解析を行うことで約40%品質改善できることを確認されています。このようにプログラム解析結果を設計情報生成に活用することが設計情報生成に有効であると考えております。今後もFujitsu ナレッジグラフ拡張RAG for SEは設計情報生成やIT資産理解に有効なLLMの活用方法を追求していきます。

ナレッジグラフ拡張RAG for SEを試してみませんか
ここからはFujitsu ナレッジグラフ拡張RAG for SEを使って設計情報を生成する方法をご紹介します。たった2Stepで設計情報生成ができ、とても簡単です。
- Step1. コードの登録・選択
- Step2. 解析結果の確認
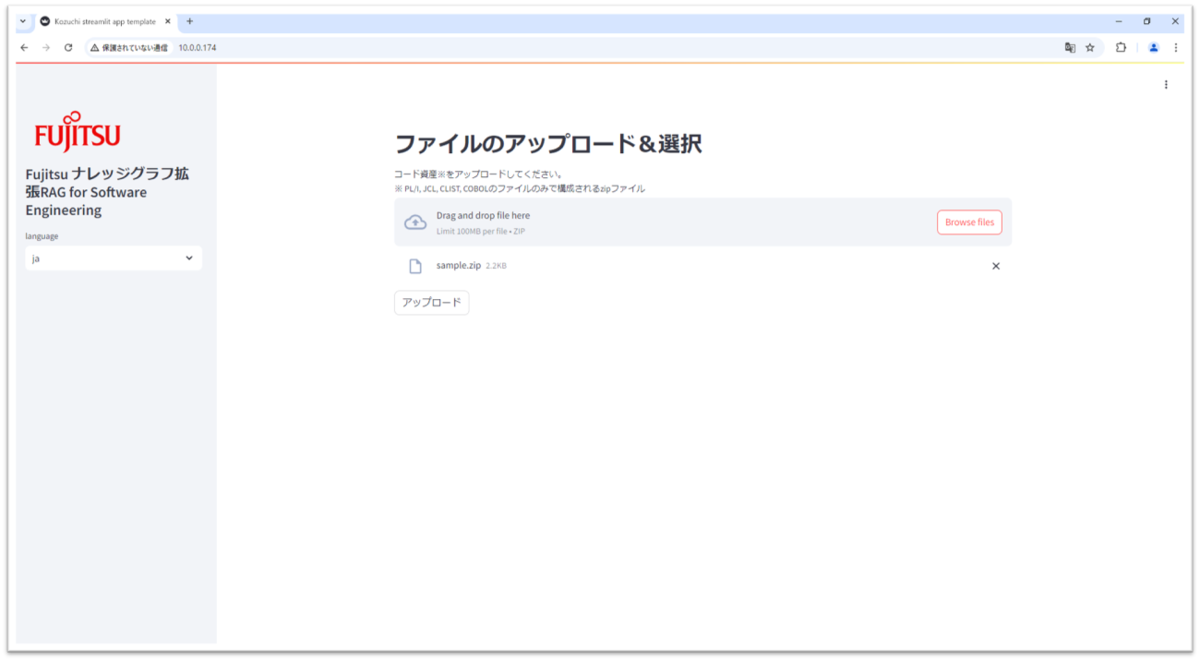
Step1. コードの登録・選択
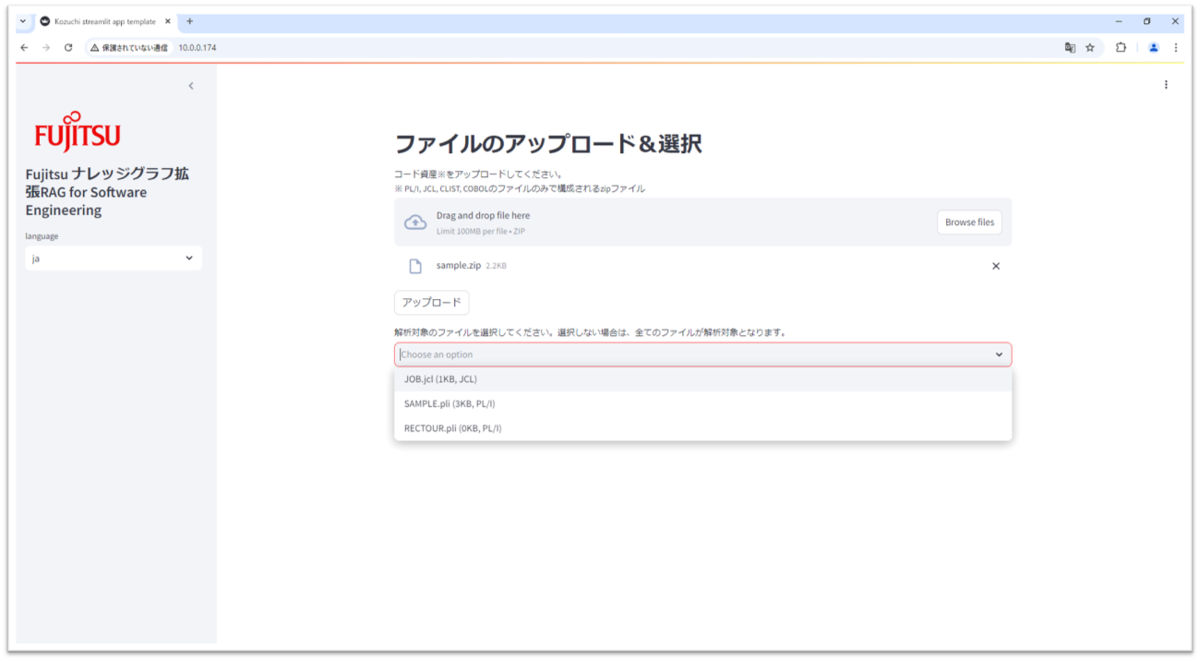
- 設計情報生成したいコードをzip形式にまとめ、ドラッグ&ドロップするか、Browse filesより選択し「アップロード」ボタンを押します。なお、現在PL/I, COBOL, CLIST, JCLに対応しております。
- zipファイルに登録されているファイルから解析対象としたいファイルを選択します。選択しない場合は、すべてのファイルが解析対象となります。
Step2. 解析結果の確認
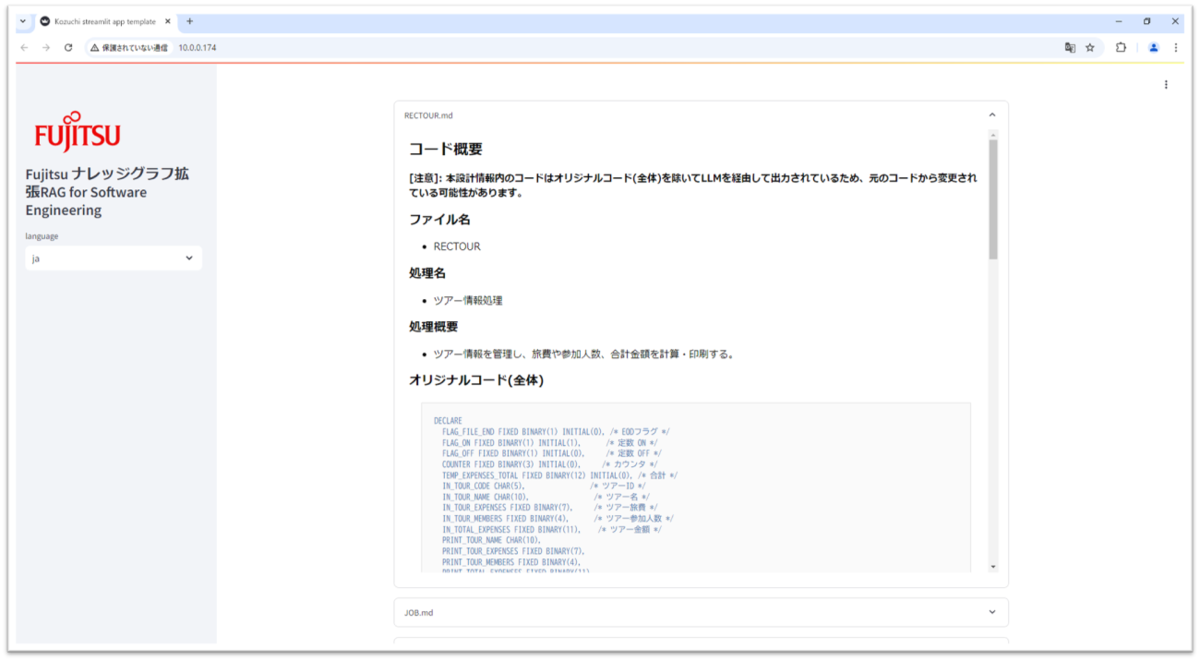
- 解析結果はプレビュー画面より確認することが可能です。見たい解析結果をクリックすると、該当の設計説明をアプリ上で見ることができます。
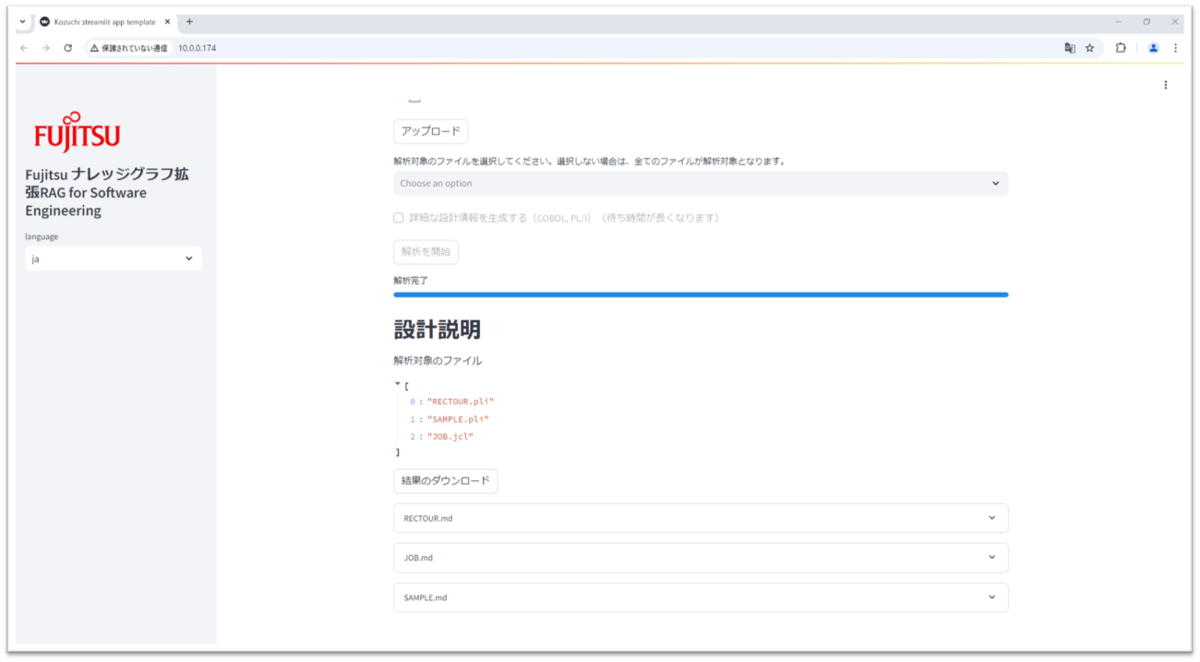
- またmarkdown形式で作成された解析結果は、「結果のダウンロード」ボタンより一括でダウンロードすることも可能です。
*1:RAG技術:Retrieval Augmented Generation。生成AIの能力を外部データソースと組み合わせて拡張する技術。
*2:https://web.archive.org/web/20201023191843/https://sites.google.com/a/offshorejp.com/www/pl1/02/02-02
*3:Wei, Jason, et al. "Chain-of-thought prompting elicits reasoning in large language models." Advances in neural information processing systems 35 (2022): 24824-24837.
*4:https://web.archive.org/web/20201023191839/https://sites.google.com/a/offshorejp.com/www/pl1/02/02-01