
はじめに
こんにちは。人工知能研究所の陽奥、豊田、ジャパン・グローバルゲートウェイの松永です。富士通では、AIアバターが質問に対して、例えば経営者やベテラン技術者の知識をデータ化したナレッジに基づいて回答を行うことや、プレゼンテーション資料を理解して発表原稿を作成し、発表することができる「Fujitsu ナレッジAIアバター」技術を開発しました(下図:Fujitsu ナレッジAIアバターのWeb UI例)。今回は技術の特徴と仕組みについて紹介します。
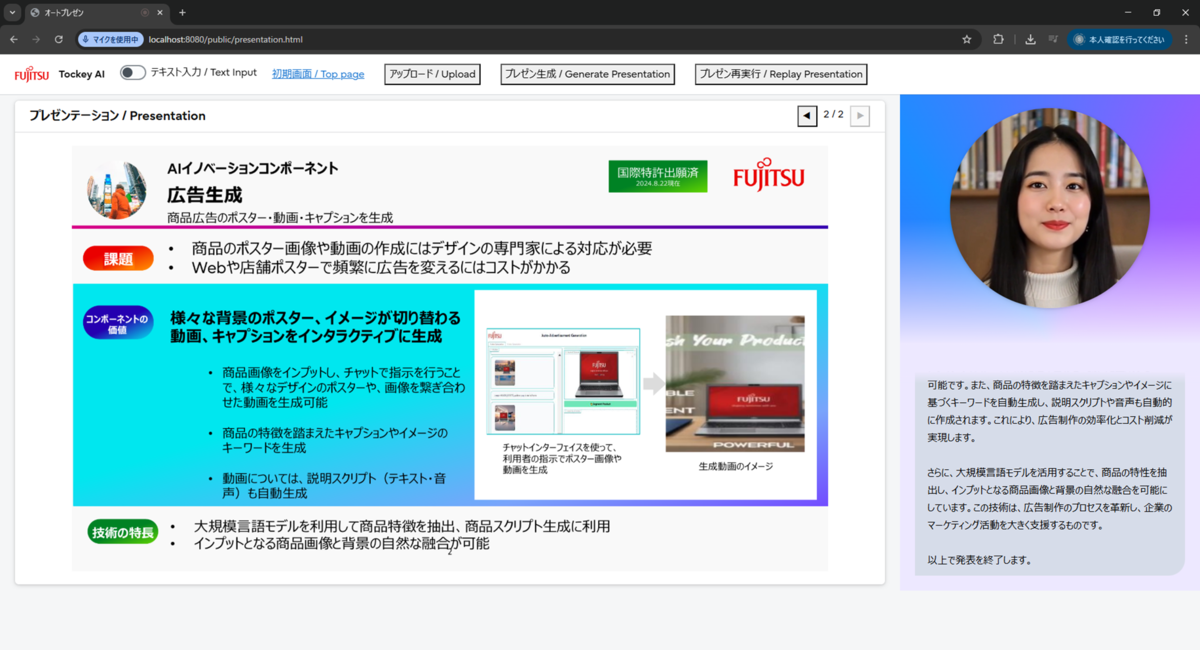
Fujitsu ナレッジAIアバター
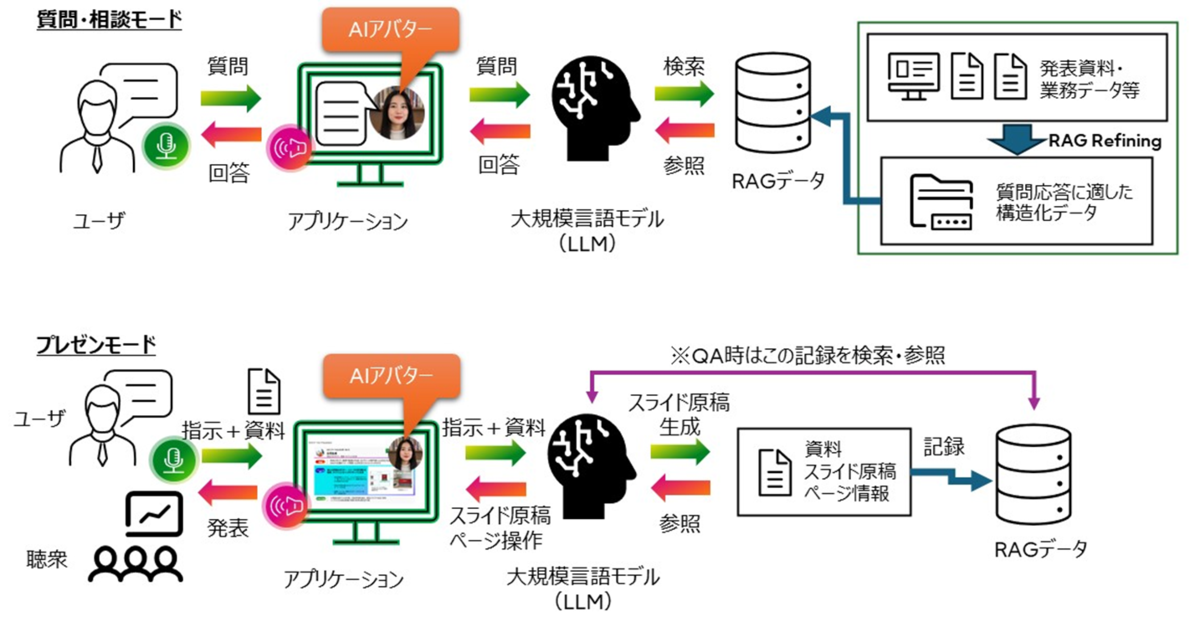
「Fujitsu ナレッジAIアバター」は、質問に対し、ナレッジを組み込んだAIアバターが音声で回答を行うコミュニケーションツールです。本ツールには、AIアバターによる質問・相談モードとプレゼンモードの2つのモードがあります。(下図:Fujitsu ナレッジAIアバターの特徴)質問・相談モードでは、RAG(Retrieval Augmented Generation)を用いています。経営戦略資料やインタビュー記事など、ナレッジに関するドキュメントをアップロードすると、後述する独自のRAG Refinig技術により、質問回答に適したRAGデータを生成します。これにより、ユーザからの質問に対して、大規模言語モデル(LLM)がナレッジに基づいた回答を生成し、AIアバターが音声で回答を行います。プレゼンモードでは、プレゼンテーション資料をアップロードすると、オートプレゼン技術により、LLMが資料を分析してスライド原稿を作成し、AIアバターがスライドを操作しながら発表を行います。QAにも対応しており、ユーザから質問があった場合は、関連するスライドを検索して表示しながらスライド情報に基づいた回答を行います。
課題
ナレッジに基づいた回答生成の課題
RAGデータにナレッジと無関係な情報が混在していると、誤った回答が発生しやすい
例えば自社の経営戦略などのナレッジに基づいた回答生成にあたっては、経営や自社製品に関するドキュメントを集めてRAGデータを構築し、質問に関係するデータを検索・参照して回答を行うことが一般的です。(下図:一般的なRAGの構造)
しかしながら、自社製品に関する資料の中に、参考資料として他社の製品情報が入っているなど、自社のナレッジと無関係な情報が混在している場合、製品に関する質問に対して他社の製品情報が検索結果に反映されてしまうことがあり、精度の高い回答を得られなくなるという課題があります。
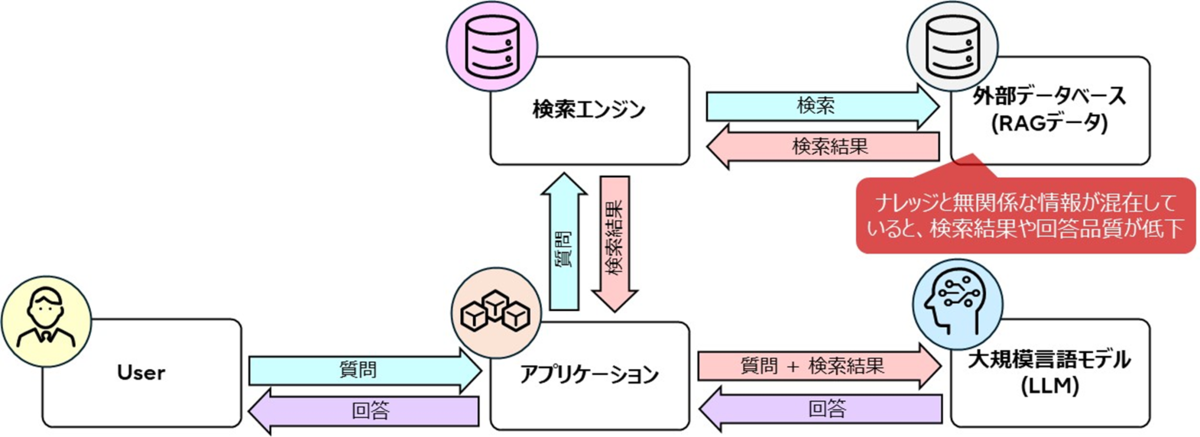
回答にタイムラグがあるとUXが低下
AIアバターによる音声対話のUXを向上するためには、迅速なレスポンスが重要です。例えば、多段階での繰り返し検索や、ナレッジグラフの活用など、RAGにおけるデータ検索性能を上げる手法が多く提案されていますが、検索精度が向上する代わりに処理速度が遅くなるという課題があります。
自動プレゼンテーションの課題
ユーザの作業負荷が高い、質疑応答に対応できない
プレゼンテーションの自動化にあたっては、従来人手で多くの作業を行いプレゼンテーション動画を作成する必要があります。例えば、スライド原稿の作成、発表者によるプレゼンテーション映像や音声の収録、動画編集などが必要となり、ユーザの負荷が大きくなるという問題があります。また、あらかじめ収録した動画を再生するのみであるため、質疑には対応できないという問題もあります。
ナレッジAIアバターの技術の仕組み
RAG Refine技術(特許出願済み)
高速かつ精度の高い回答を実現するため、RAGデータの品質を向上させるRAG Refine技術を開発しました。(下図)本技術は、ナレッジとして登録するドキュメントを解析し、QA形式にデータ変換した上でRAGデータを構築することが特徴です。まず、元となるドキュメントを、QA生成用のLLMにより、特定の領域の専門家への質問を想定したQA集に変換します。その後、QA集と元ドキュメントを、QA評価用のLLMにより、QA集が特定領域のナレッジを反映した回答か否かを評価し、評価結果をQA生成用のLLMにフィードバックします。この生成と評価のサイクルを回すことで高品質なRAGデータを生成します。そして、このRAGデータをナレッジAIアバターの回答システムに組み込むことで、回答性能を向上しています。このRAG Refine技術を用いることの利点は2つあります。1つ目はデータ品質の向上です。異なる役割をもったLLMによるQA生成と評価のサイクルを回すことで、テキスト・Web・PDFに限らず元ドキュメントに含まれる、例えば広告情報のようなナレッジと無関係なデータを除去し、データ検索の性能を向上することができます。2つ目は質問に対する応答速度に影響しないことです。検索精度を高めるために多段階の繰り返し検索などを使う場合、処理時間が増加してしまいます。本技術の場合、事前にRAGデータを構築することができ、RAGシステム自体に高度な処理を組み込む必要がないため、応答速度には影響を及ぼさないという特徴があります。
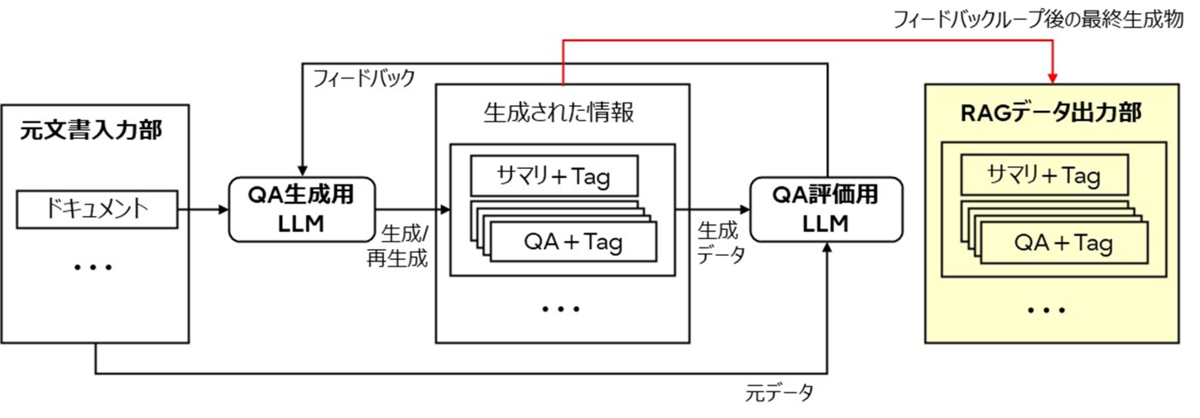
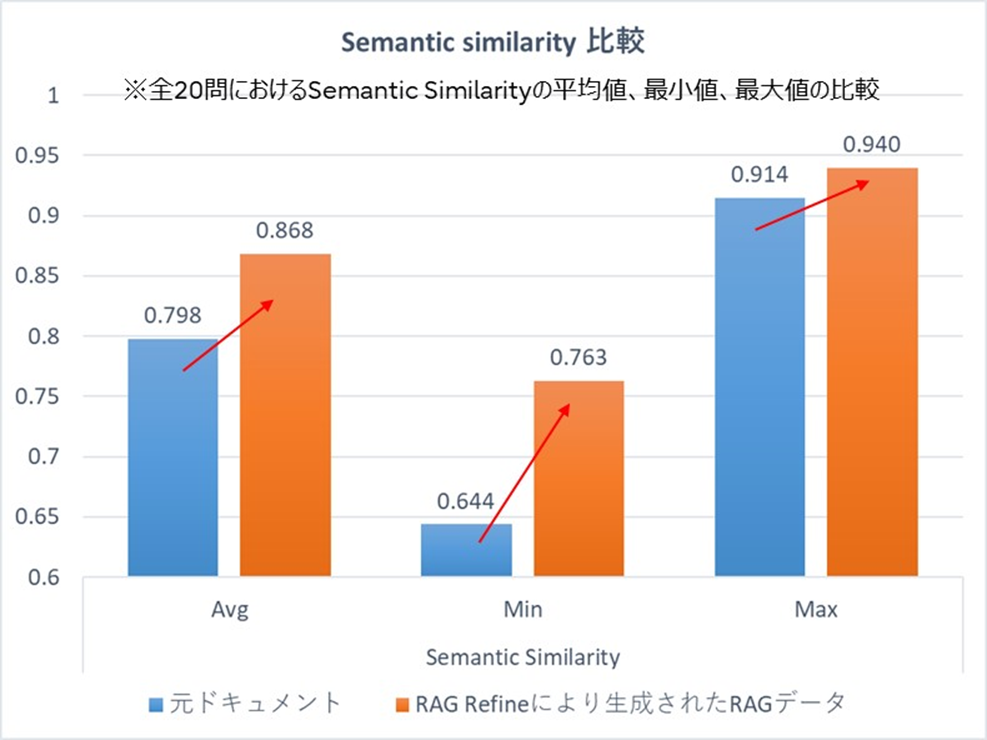
下の図は、ある経営者のインタビューやメッセージをもとに、RAGデータを生成し、評価を行った結果となります。評価は、インタビューの一部から質問と正解を作成し、元のドキュメントをもとに回答を生成した場合と、本技術により生成したRAGデータを用いて回答を生成した場合で評価を行っています。なお、評価尺度には、正解と生成した回答の意味的な類似度を示すSemanticSimilarityを使用しています。結果を見ると、本技術を使用した方が高いスコアを示している、すなわち、本人に近い回答を生成していることが確認できます。
オートプレゼン技術(特許出願済み)
プレゼンテーションにおいて、発表資料の内容を理解して発表を行う発表内容制御機能と、発表後の質問に対して関連資料を検索し回答を行う回答制御機能を備えたオートプレゼン技術を開発しました。それぞれ以下のような特徴があります。
[発表内容制御機能]
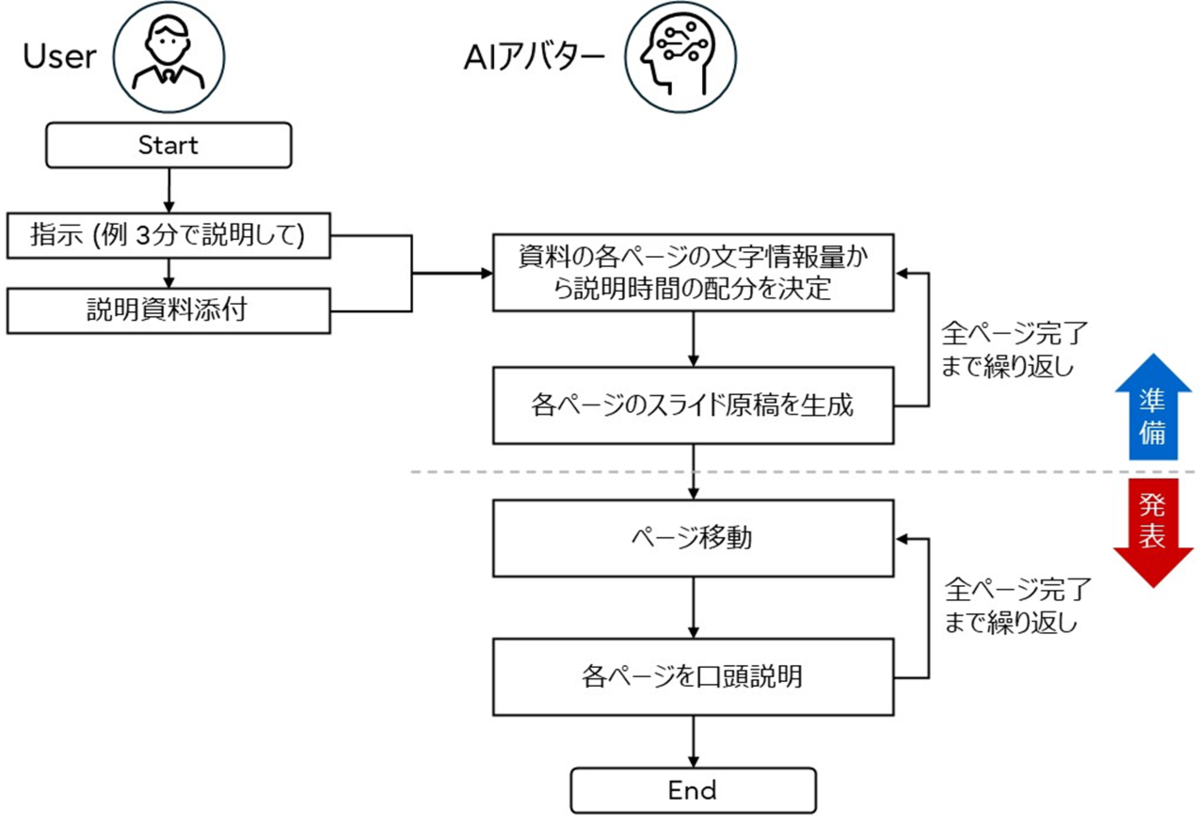
以下のフローチャートにそって機能の特徴を説明します。ユーザから資料の添付と説明の指示(例えば、「3分以内に説明して」)をシステムが受け取ると、AIアバターは、LLMを用いて説明の指示や資料の各ページの文字・図の情報を分析して、各ページの説明時間の配分を決定し、スライド原稿を生成します。そして、この生成した原稿にそって、AIアバターが資料のページを操作しながら、音声で説明を行います。このように、指示や説明資料の内容をもとに、資料の各ページの時間配分を最適化することにより、ユーザが資料の一つ一つのページに対して、スライド原稿を用意しなくてもプレゼンテーションが可能となります。
[回答制御機能]
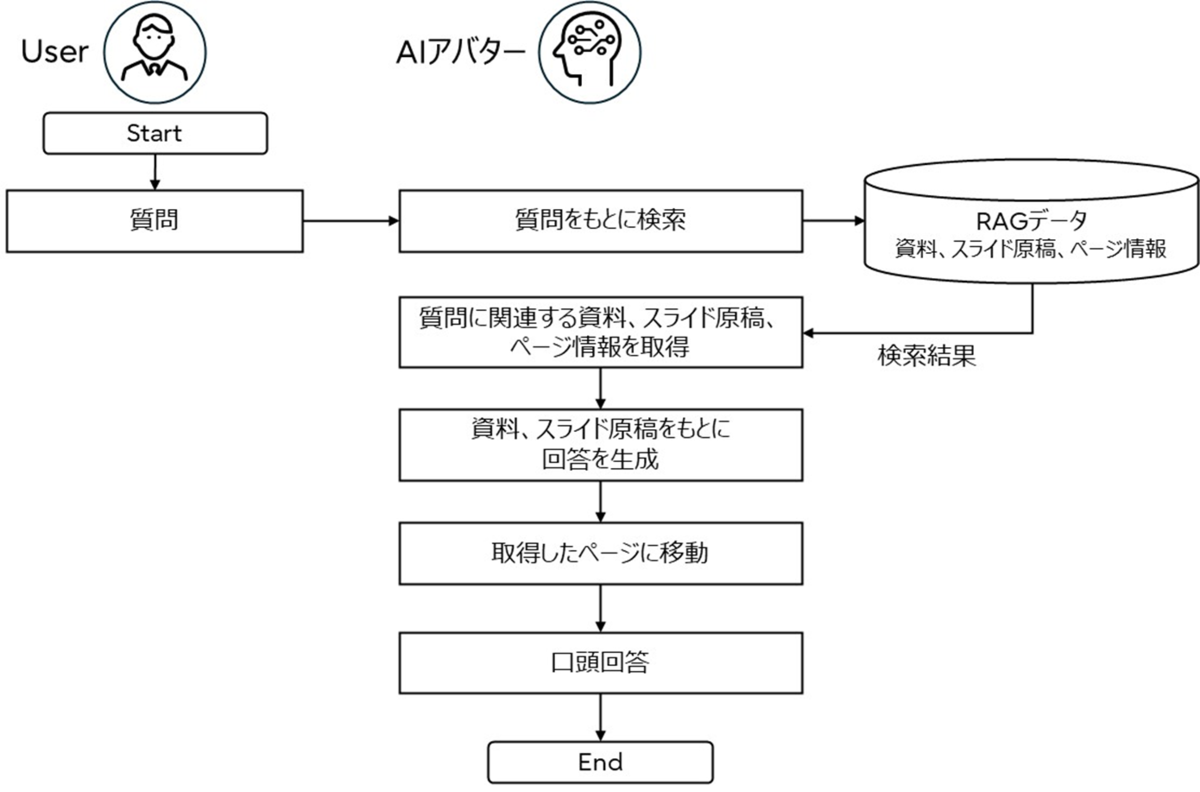
以下のフローチャートにそって機能の特徴を説明します。システムは、説明資料、前述の生成されたスライド原稿とページ番号をデータベースに記録しており、ユーザから、資料に関する質問があった場合は、最も質問と関連性の高い資料のページを、RAGを用いて検索します。検索後、関連するページが見つかった場合は、資料のページと生成されたスライド原稿の情報をもとに、AIアバターがLLMを用いて質問に対する回答を生成します。その後、AIアバターは見つかったページへ移動させ、該当する資料のページを表示しながら音声で回答を行います。このように、資料情報や生成したスライド原稿をRAGデータとして取り込むことで、質問に対し関連する情報を視覚化しながら回答を行うことが可能となります。
おわりに
本稿では、AIアバターによる質疑応答やプレゼンテーションを実現する「Fujitsu ナレッジAIアバター」技術について紹介させていただきました。本技術は、経営層に代わり従業員に経営ビジョンを伝える発信ツールとしての利用や、ベテラン技術者の知識や経験をもとにした技能伝承、トップ営業のノウハウ資料を活用した講演・教育など、幅広い分野で利用可能な技術であり、今後ユースケースを拡大していくつもりです。また、本技術はFujitsu Kozuchiの「Fujitsu ナレッジAIアバター」としてリリースしております。ご興味のある方は、下記よりアクセスしてください。