
こんにちは。人工知能研究所 AI品質プロジェクトの徳井翔梧です。富士通研究所では深層学習(DNN)モデル修正について、国立情報学研究所 NII と共同研究を行っています。今回は、DNNモデルのパラメータ(重み)を探索的に変更することでDNNモデルの誤判定を局所的に修正する技術に関する論文が、国際会議SANER 2022 に採択されたので、その概要を紹介します。
対象論文
- タイトル:NeuRecover: Regression-Controlled Repair of Deep Neural Networks with Training History
- 著者:Shogo Tokui, Susumu Tokumoto, Akihito Yoshii, Fuyuki Ishikawa, Takao Nakagawa, Kazuki Munakata, Shinji Kikuchi
- 発表会議:The 29th IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER 2022)
- 論文リンク : https://arxiv.org/abs/2203.00191
採択された論文の内容
本論文では、画像分類問題に対して、DNNモデルのパラメータ(重み)を探索的に変更することで、再訓練することなくDNNモデルの誤判定を局所的に修正する技術を提案しています。以下では、まずDNNモデル修正の背景を説明し、提案手法と評価実験について簡単に述べます。
背景:DNNモデル修正、既存手法 Arachne
近年、医療技術や自動運転技術など安全性や品質がより重要視されるドメインにDNNが適用されており、DNNモデルの更新に伴って発生しうるデグレードを抑制することがますます重要になっています。DNNを用いたシステムで誤判定を検出した場合、通常ではデータを追加して再訓練することでDNNモデルを修正します。しかし、再訓練を行うためには追加データを用意する必要があり、それなりの工数がかかります。また、再訓練に伴ってステークホルダが許容できないデグレードが発生する可能性があります。そこで私たちは、再訓練を行わずに、DNNモデルを修正する方法を研究しています。
従来のソフトウェア工学技術であるプログラムの自動修正技術 [2] のアイデア・考え方は、DNNモデルを修正する技術に転用できる可能性があります。プログラム自動修正は、失敗テストケースを含むテストを実施してプログラムのバグの原因箇所を絞り込み、修正パターンからパッチを探索的に生成し、最終的にテストがすべて通るパッチを出力する手法です(図1)。プログラム自動修正技術は多く提案されており、特に "Generate and Validate (G&V) 方式” は単純な欠陥に対する修正について大きな成功を収めており、DNNモデル修正のための重要なアイデアを与えてくれました。

Sohnらは、プログラム自動修正技術を応用して、DNNモデルの局所的なパラメータを探索的に変更してDNNモデルを修正する手法、Arachne [3] を提案しました。Arachne は、失敗テストデータに対する影響度により失敗の原因だと思われるパラメータ(重み)を絞り込む欠陥局所化を行い、粒子群最適化 [4,5] により多くの失敗を修正できる値を探索します(図2)。
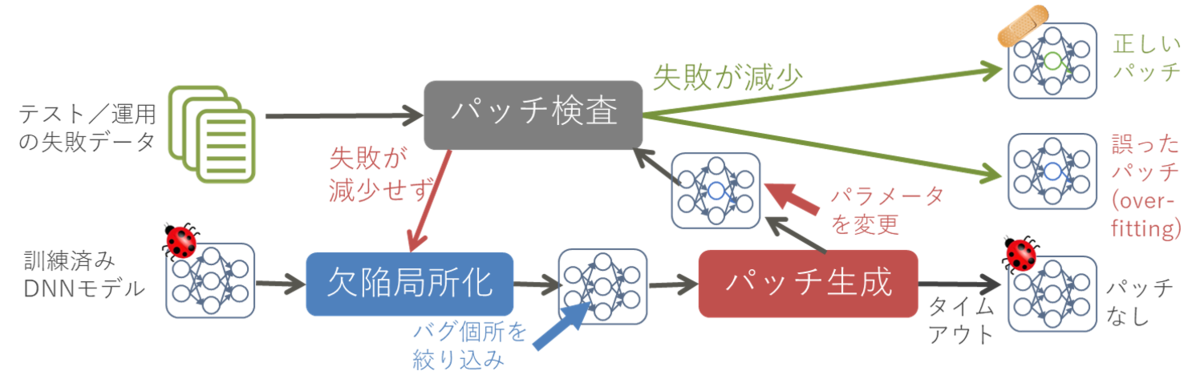
しかし、既存手法 Arachne の欠陥局所化は失敗データの影響のみで重みを絞り込むため、Arachneは成功データを誤判定に変えてしまう可能性がありました。そこで、本論文では、デグレードを引き起こす可能性が高い重みを除いて特定の失敗データにのみ影響する重みを特定する欠陥局所化を提案しました。
提案手法 NeuRecover
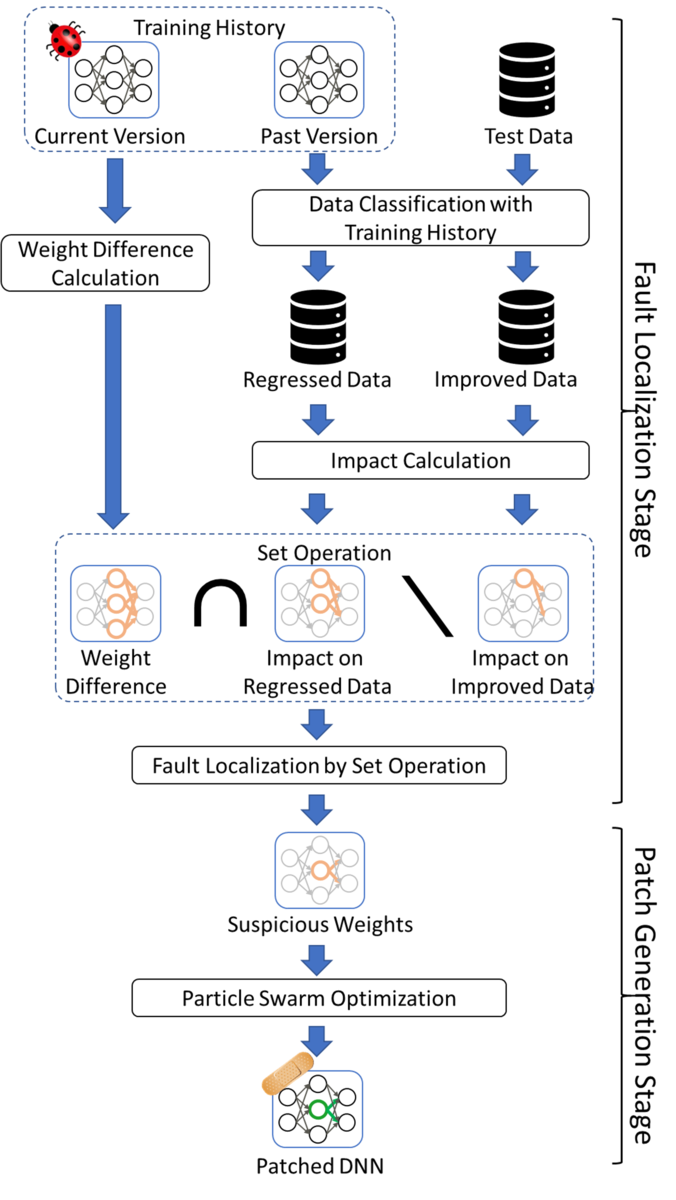
本論文では、デグレードを抑制しつつDNN モデルを局所的に修正する技術として、訓練履歴を用いた欠陥局所化によるDNN 修正技術、NeuRecover を提案しました。NeuRecoverの基本的なアイデアは、訓練履歴から過去の正しい振舞いを見つけ、それと現在との差分をあぶりだすことで得られる知識により安全に欠陥を修正できる箇所を特定することです。
具体的には、NeuRecoverは、改善データ(訓練過程において誤分類から期待する分類に推移したデータ)での出力に影響せず、退行データ(期待する分類から誤分類に推移したデータ)での出力に影響し、訓練過程で値が大きく変化したパラメータ(重み)を特定します。特定した重みに対して粒子群最適化を行うことで、正しい振舞いへの影響が少なく誤った振舞いに影響が限定されるようにDNNモデルを修正します。影響度には損失勾配の値と順伝播の値を利用します。(図3)
評価実験
本論文では、3つのRQ、①NeuRecoverの設計妥当性、②従来手法と再訓練との比較、③特定の誤判定データの修正における比較、について評価実験を行いました。ここでは、②他手法との比較と③特定データの修正、についての実験結果をご紹介します。
実験準備
実験では、特定の条件に偏った評価にならないように3つのモデルアーキテクチャと3つのデータセットの組み合わせを試しました。モデルアーキテクチャは、8層CNNモデル (8CN)、VGG16、VGG19の3種類用意しました。8CNは6個の畳み込み層と2個の全結合層、VGG16は13個の畳み込み層と3個の全結合層、VGG19は16個の畳み込み層+3個の全結合層でそれぞれ構成されます。画像分類のデータセットは、GTSRBとCIFAR10(C10), Fashion-MNIST(FM)を利用しました。各データセットに対して各モデルアーキテクチャで5エポックまたは10エポック訓練し、修正対象とする18つのモデルを用意しました。
NeuRecoverの評価実験では、データセットの訓練データを「訓練用データ」と「修正用データ」に分割しました。一般的によく用いられる機械学習の評価データセットには訓練データとテストデータが含まれます。しかし、DNN修正技術の評価実験では訓練済みモデルの修正に用いるデータが必要です。そのため、訓練データを訓練用データと修正用データに分割し、訓練に用いられたデータや評価用データを用いて修正することを避けました。
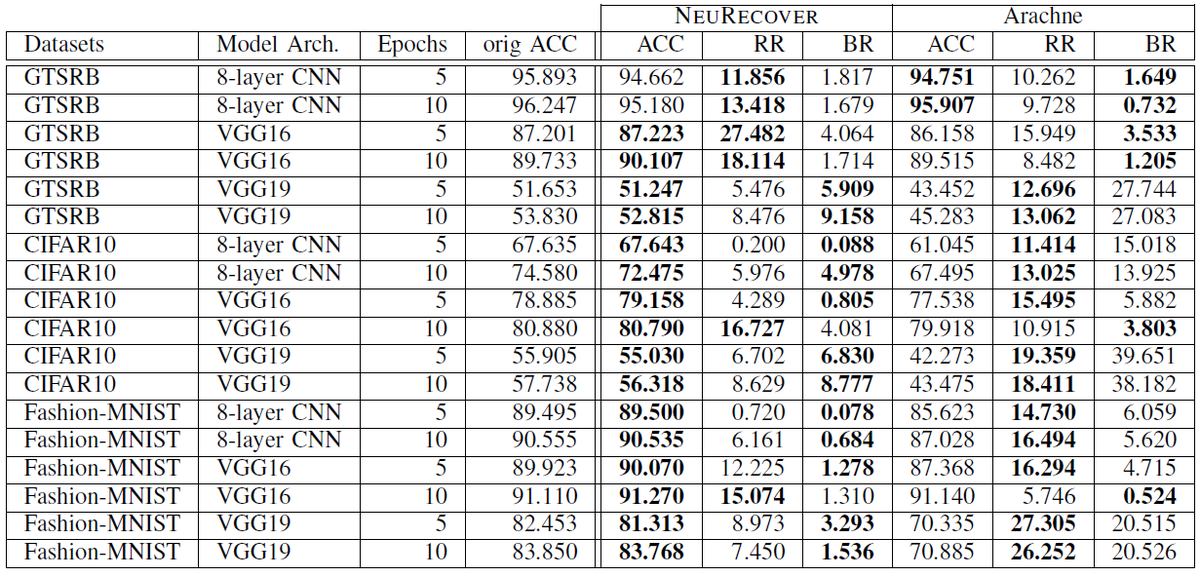
実験結果RQ2(従来手法、再訓練との比較)
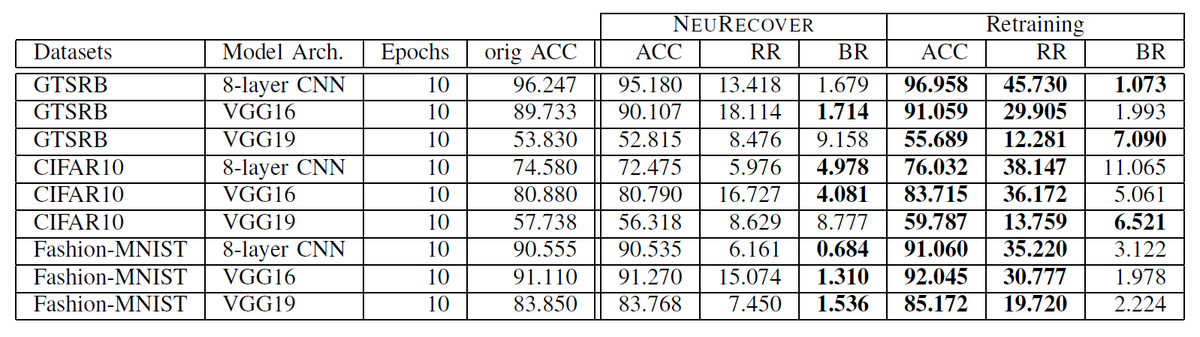
下の表1と表2は、NeuRecoverとArachneの実験結果の比較、NeuRecoverと再訓練 (Retraining) の実験結果の比較を示しています。修正用データの失敗データを修正対象として各手法でモデル修正を行いました。ACCはモデル修正後のモデルの精度(評価データ中の成功判定の割合)、RRは修正率(修正前後で成功判定から誤判定に推移した評価データの割合)、BRはデグレード率(修正前後で誤判定から成功判定に推移した評価データの割合)を表します。
表1より、NeuRecoverは先行研究であるArachneと比較してBRを4分の1以下、場合によっては10分の1以下に抑えることができています。デグレードを抑制した結果、全体の精度(ACC)はArachneよりNeuRecoverの方が優れています。一方で、表2より、NeuRecoverの方がBRが低いケースが多いですが、ACCとRRは全体的に再訓練の方が優れていることが分かります。1つの仮説は、探索的な重み修正の可能性は、誤判定したすべての入力の修正を目指すことではなく、特定の誤判定データを成功判定に改善することにあるということです。この点について、次のRQ3で実験を行いました。
実験結果RQ3(特定のラベルの誤判定データを修正対象とする実験)
特定のデータの修正が可能かを確認するため、特定の誤分類パターンに絞った修正を評価しました。具体的には、特定の誤分類が頻繁に発生する一般的なシナリオを検討し、それを修復します。CIFAR‐10では、ラベル3(cat)をラベル5(dog)に誤分類したデータを修復目標とし、Fashion-MNISTの場合、ラベル6(shirts)をラベル0(T-shirts)への誤分類したデータを修正目標としました。どちらも紛らわしい (視覚的に近い) ラベルの代表例です。GTSRBはラベルが多く、ラベルごとのデータ数が少なすぎるため、実験では CIFAR-10 と Fashion-MNIST を対象としました。
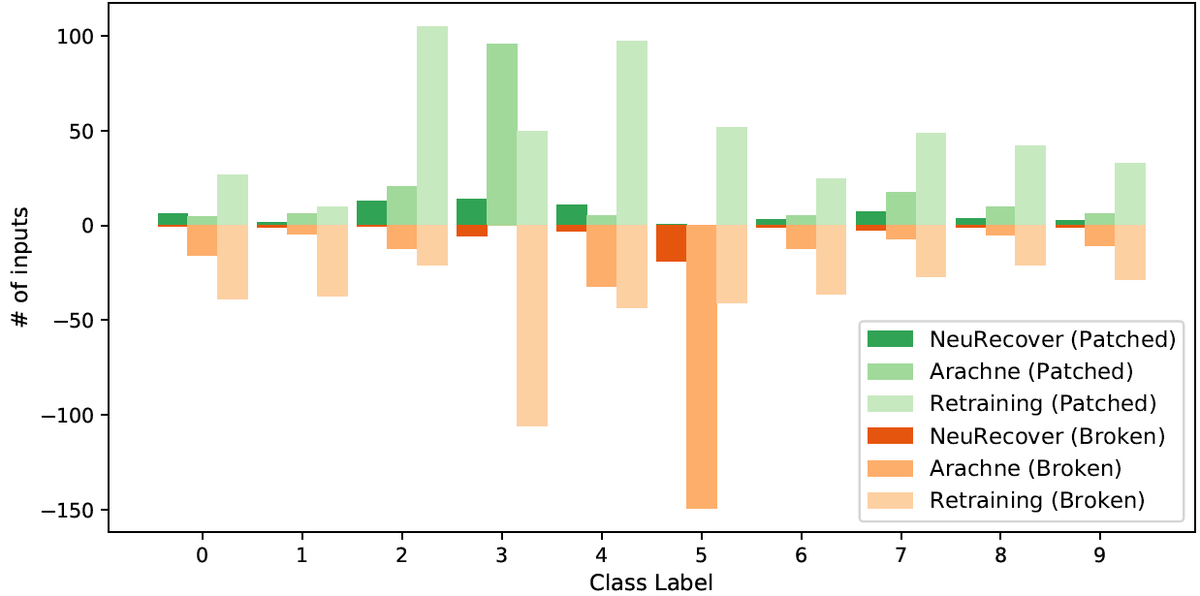
表3と図4と図5は、NeuRecover, Arachne, 再訓練(Retraining)で特定データを修正したときの実験結果を示します。 表3では、修正対象のラベルはLWで表しており、LW-#negは修正対象の特定の誤判定データの数、LW-RR特定ラベルの修正率を表します。NeuRecoverは、安定的に低いBR (2%未満) であり、Arachneより優れた性能を示しています。一方で、再訓練はRQ2の結果(前述の実験結果)と比較して、ACCとBRが悪化しています。そのため、特定ラベルの修正においては、NeuRecoverは安定的に低いBRで、多くの場合、再訓練と比較してBRを4分の1以下に抑えることができていました。
図4と図5では、ラベルごとの修正の性能の詳細を示します。CIFAR‐10とFashion‐MNISTを用いたVGG16の実験結果です。2つの図では判定結果がどのように推移したか(成功判定→誤判定、または誤判定→成功判定)を示しています。NeuRecoverは修正されたデータの数は控えめですが、デグレードしたデータの数を低く抑えています。Arachneは修正対象のラベルを特に修正する傾向がありますが、その代わりに別のラベル(CIFAR-10ではラベル5、Fashion-MNISTではラベル0)において急激なデグレードがみられます。再訓練では、デグレードしたデータがさまざまなラベルに表示されており、再訓練では特定ラベルの修正においてデータの入れ替わりが発生していると考えられます。例えば、Fashion-MNISTのラベル4のように、同じラベルであっても多くの改善とデグレードが同時に発生しています。これは、全体の精度が同等かそれ以上であっても、誤判定に推移したデータのリスクをチェックするコストがかかってしまいます。


終わりに
本研究について、Engineerable AI プロジェクト(eAI project) の観点から、国立情報学研究所の石川准教授と富士通の徳本研究員の2人が回答したインタビュー記事が公開されています。こちらのインタビュー記事では本研究の背景や将来性について詳細に説明されています。ご興味があれば、合わせてご参照ください。(インタビュー記事リンク)
本記事ではSANER2022で採択された研究の概要をご紹介しました。本研究の初期の評価結果について、2021年3月に情報処理学会第207回ソフトウェア工学研究発表会 (SIGSE) にて日本語で発表しました[6]。光栄なことにコンピュータサイエンス領域奨励賞を授賞しました。
References
- Shogo Tokui, Susumu Tokumoto, Akihito Yoshii, Fuyuki Ishikawa, Takao Nakagawa, Kazuki Munakata, and Shinji Kikuchi. Neurecover: Regression-controlled repair of deep neural networks with training history. In proceedings of SANER 2022.
- C. Le Goues, M. Dewey-Vogt, S. Forrest, and W. Weimer, “A systematic study of automated program repair: Fixing 55 out of 105 bugs for $8 each,” in 2012 34th International Conference on Software Engineering (ICSE). IEEE, 2012, pp. 3–13.
- J. Sohn, S. Kang, and S. Yoo, “Search based repair of deep neural networks,” arXiv preprint arXiv:1912.12463, 2019, Available: http://arxiv.org/abs/1912.12463
- J. Kennedy and R. Eberhart, “Particle swarm optimization,” in Proc. of ICNN’95, vol. 4. IEEE, 1995, pp. 1942–1948.
- A. Windisch, S. Wappler, and J. Wegener, “Applying particle swarm optimization to software testing,” in Proc. of GECCO’07. Association for Computing Machinery, 2007, pp. 1121–1128.
- 徳井翔梧, 徳本晋, 菊池慎司, 石川冬樹. "訓練履歴を用いた欠陥局所化によるディープニューラルネットワーク修正技術の開発". ソフトウェア工学研究会(SIGSE), 2021.