
こんにちは.人工知能研究所 自律学習PJの浦です.富士通研究所では「自律的に学習可能なAI技術」に関する研究開発を行っています.このたび,我々の研究成果であるAutoML技術であるSapientMLの研究論文が,ソフトウェア工学の主要な国際会議であるICSE2022に採択されたので,その内容を紹介します.
対象論文
- タイトル:SapientML: Synthesizing Machine Learning Pipelines by Learning from Human-Written Solutions
- 発表会議:44th International Conference on Software Engineering (ICSE 2022)
- プレプリント版の論文へのリンク
採択された論文の内容
目的
今回採択された論文はデータ分析を自動化するAutoMLと呼ばれる分野に関するものです.我々が開発したSapientMLは,入力としてデータを受け取り,下図のようなスクリプトを生成して出力することができます.
このスクリプトでは,欠損値埋め(SimpleImputer),カテゴリカル変数変換(OrdinalEncoder),値の正規化(StandardScaler),ラベルの不均衡対策のオーバーサンプリング(SMOTE)の処理を順番に適用していき,最後にCatBoostClassifierのモデルを使って学習し,F1スコアで評価しています.
このコードを生成する際に問題となるのが,与えられた入力データに対して適切な処理(部品)の選択です.これを候補となる部品をいろいろ組み合わせて試すという探索だけで行ってしまうと,試すべき組み合わせ(パイプライン)の数が非常に多くて探索するべき空間が広くなってしまい,短時間では適切なパイプラインを見つけることができません.そこで我々は,分析者が書いたスクリプトから適切だと思われる部品を学習することで探索空間を小さくし,短時間でコードを生成することを目的として研究を行いました.
技術内容
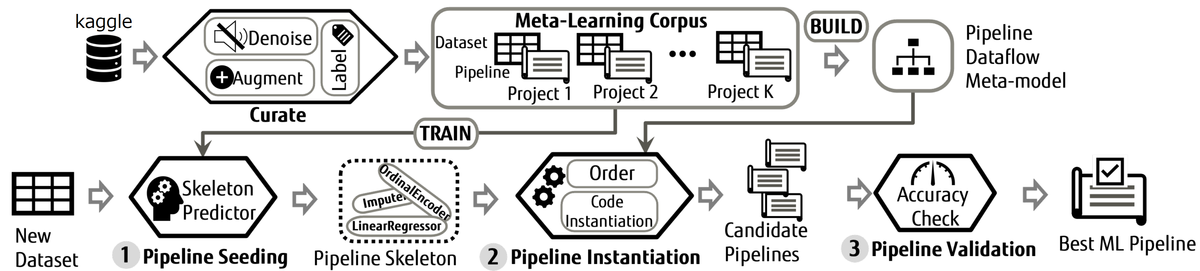
上図はSapientMLの処理の全体を表したものです.大きく分けてオフラインフェーズ(上段)とオンラインフェーズ(下段)に分かれます.オフラインフェーズでは分析者のスクリプトから,各データに適切な部品を学習します.オンラインフェーズでは新しいデータが与えられたときに,そのデータに適したパイプラインをオフラインフェーズで学習したモデルを用いて実際に生成します.本研究では,学習に使うデータとスクリプトとして,データ分析プラットフォームであるKaggleのものを用いました.
オフラインフェーズでは,まず,実行できないスクリプトを除外した上で最終的なモデルを生成するのに関係がない部分をスクリプトから削除します(Denoise).例えば,データの可視化のためにグラフを描画するコードなどが削除されます.その後,各スクリプトのモデル部分をいろいろ差し替えて試すことで,一番精度が高いものを選びます(Augment).これにより,分析者が精度の出ないモデルを使っていたとしても,精度の出るモデルを使ったスクリプトとして学習することができます.次に,各スクリプトに含まれる部品をラベルとしてつけます(Label).ラベルは,"Imputer"や"OrdinalEncoder"や"RandomForestClassifier"といったものです.ここまでの処理で学習用のコーパス(Meta-Learning Corpus)が整備されました.これを用いて,データを表現するメタ特徴量(行数,列数,欠損値の有無,カテゴリカル変数の有無など)からラベルを予測するモデル(Skeleton Predictor)を学習します.合わせて,ScalerはImputerの後に使われるといった,部品同士の順序関係(Dataflow Meta-model)もコーパスから取得しておきます.
オンラインフェーズでは,入力データのメタ特徴量を学習したモデル(Skeleton Predictor)に入力することで,入力データに対して使うべき部品(Pipeline Skeleton)を予測します(Pipeline Seeding).これで使うべき部品が絞られるので,それをオフラインフェーズに取得した順序関係(Dataflow Meta-model)を使って並び替え,実際にスクリプトをいくつか生成します(Pipeline Instantiation).最後に生成したスクリプトを実際に実行し,最も精度が高いスクリプトを出力します(Pipeline Validation).
評価
実験では,OpenML,PMLB,Mulan,Kaggleの41個のデータを用いてベンチマークを行いました.比較対象のAutoML技術としては,SapientMLと同様に分析者のスクリプトから学習したAL(Cambronero 2019)と,従来のAutoMLのツールであるAuto-sklearn(Feurer 2015)とTPOT(Olson 2016)を用いました.
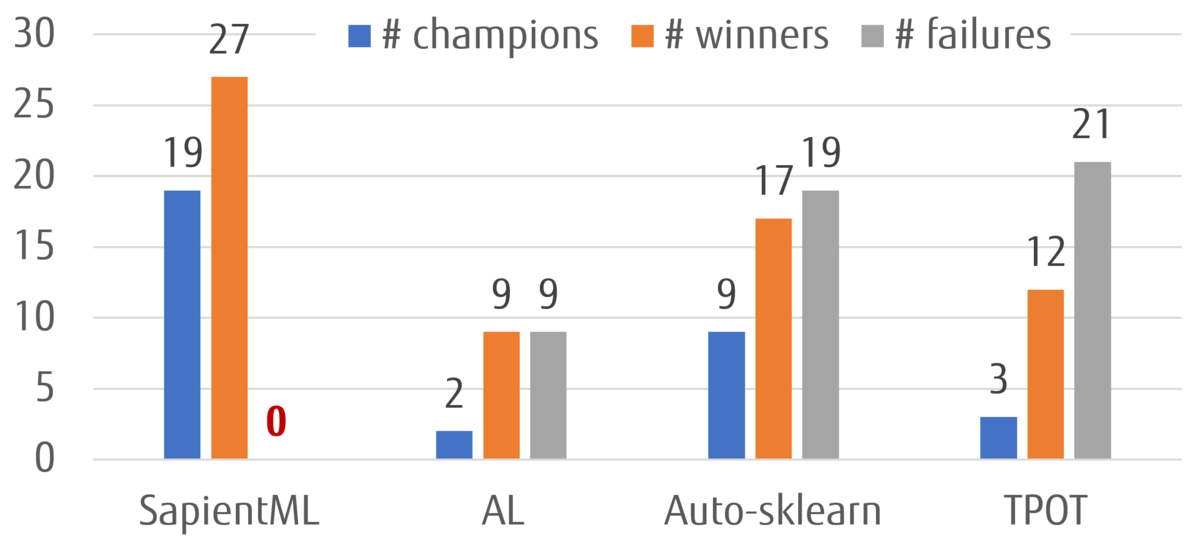
終わりに
本記事では我々が開発しているAutoML技術であるSapientMLについて,ICSE2022に採択された論文を基に紹介しました.
富士通研究所では一緒に働ける方やインターンシップを随時募集しています.もし興味を持たれた方がいらっしゃいましたら,自律学習PJの小橋がカジュアル面談を行いますので,是非ご連絡ください.