
Hello, I am Xiantan Zhu, a researcher from FUJITSU RESEARCH & DEVELOPMENT CENTER (FRDC). Recently, we got the top-1 place on H3WB (Human3.6M 3D WholeBody, https://paperswithcode.com/sota/3d-human-pose-estimation-on-h3wb). Our result is far superior to the second place. In this blog, I will introduce the challenging and the key ideas of our solution.

In Figure 1, you can see that we obtain the first place on H3WB benchmark, exceeding the second place (3D-LFM [1]) by 15.44 in Mean Per Joint Position Error (MPJPE) measurement.
Overview of the challenging
Human3.6M 3D WholeBody (H3WB) [2] is a large scale dataset with 133 whole-body keypoint annotations on 100K images, making possible by a new multi-view pipeline. It is designed for three new tasks : 1) 3D whole-body pose lifting from 2D complete whole-body pose, 2) 3D whole-body pose lifting from 2D incomplete whole-body pose, 3) 3D whole-body pose estimation from a single RGB image. We mainly took part in the task 1.
Data - It consists of 133 paired 2D and 3D whole-body keypoint annotations for a set of 100k images from Human3.6M, following the same layout used in COCO WholeBody.
Metrics - Mean Per Joint Position Error (MPJPE) measurement. The less MPJPE is , the better performance you will get.
Our solution
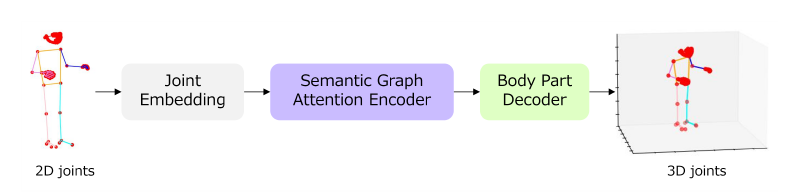
Self-attention mechanisms and graph convolutions have both been proven to be effective and practical methods. Recognizing the strengths of those two techniques, we have developed a novel Semantic Graph Attention Network (SemGAN), which can benefit from the ability of self-attention to capture global context, while also utilizing the graph convolutions to handle the local connectivity and structural constraints of the skeleton. We also design a Body Part Decoder that assists in extracting and refining the information related to specific segments of the body. Furthermore, our approach incorporates Distance Information, enhancing our model’s capability to comprehend and accurately predict spatial relationships. Finally, we introduce a Geometry Loss which makes a critical constraint on the structural skeleton of the body, ensuring that the model’s predictions adhere to the natural limits of human posture.
We describe our proposed architecture for 3D whole-body estimation, as shown in Figure 2. Next we will introduce our four innovative ideas one by one.
Semantic Graph Attention Encoder
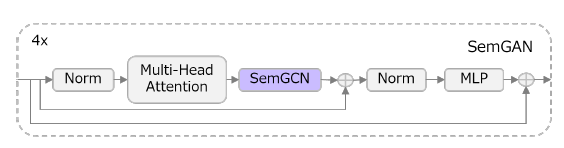
The pipeline of Semantic Graph Attention Encoder is shown in Figure 3, consisting of four layers of SemGAN. We embed the SemGCN [3] in the last layer of self-attention of Jointformer [4]. It helps to maintain the global information from self-attention and equip with local information from SemGCN.
Body Part Decoder
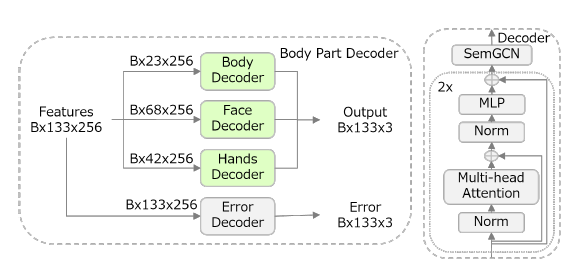
The framework of Body Part Decoder is designed as shown in Figure 4. Here B stands for batch size, 133 for the joint number of whole-body, 256 for the dims of feature, 23 for the joint number of body, 68 for the joint number of face, and 42 for the joint number of hands. In the Body Part Decoder, there are three parts: Body Decoder, Face Decoder and Hands Decoder. In the right part of the figure, you can see that we use self-attention network by twice in each decoder part to capture more correlated features within different body parts and endorse the SemGCN at the last layer instead of traditional linear layer, which helps to get accurate location with assistance information from adjacency.
Distance Information
To explore the spatial relationships inherent in skeletal structures, we provide a data process method to obtain the distance between every joint and its parent. With this additional information, a deeper sense of spatial orientation and relative position can be obtained.
Loss Function
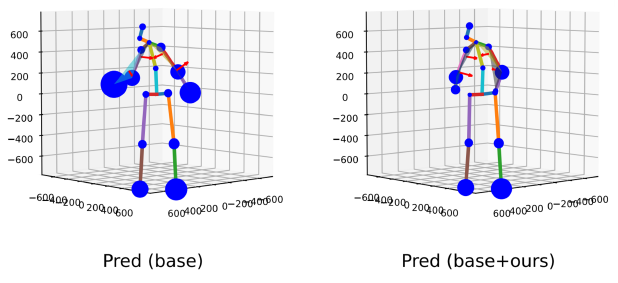
We find that the key points further from torso have less accuracy (see the left part in Figure 5). Here the size of the blue circles indicates the gap between predicted keypoints and GT. It means that the larger the circles are, the less accurate is. In the right part, it shows our prediction with multi-loss has smaller circles. In order to narrow the gap, multi-loss functions have been used. Not only the losses from Jointformer, we also add another two effective losses during our training, normal loss and bone loss. For normal loss, we follow the strategy in [5] and use four limbs to build the normal vector of the local plane. For bone loss, bone length is the distance between adjacent joints which represents structural information. We adopt Bone loss to deliver a limitation on skeleton and echo with the additional input distance information.
Acknowledgement
I would like to thank my colleagues Sihan Wen and Zhiming Tan. Sihan Wen can quickly realize our thought and brainstorm the new ideas. Zhiming Tan is our mentor who encourages us to research more cutting-edge papers and try more innovative ideas .
References
- Mosam Dabhi, L´aszl´o A. Jeni, and Simon Lucey. 3d-lfm:Lifting foundation model. ArXiv, abs/2312.11894, 2023.
- Catalin Ionescu, Dragos Papava, Vlad Olaru, et al. Human3.6m:Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(7):1325–1339, jul 2014.
- Long Zhao, Xi Peng, Yu Tian, Mubbasir Kapadia, and Dimitris N. Metaxas. Semantic graph convolutional networks for 3d human pose regression. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3420–3430, 2019
- Sebastian Lutz, Richard Blythman, Koustav Ghosal, Matthew Moynihan, Ciaran K. Simms, and Aljosa Smolic. Jointformer: Single-frame lifting transformer with error prediction and refinement for 3d human pose estimation. 2022 26th International Conference on Pattern Recognition (ICPR), pages 1156–1163, 2022.
- Ai Matsune, Shichen Hu, Guangquan Li, Sihan Wen, Xiantan Zhu, and Zhiming Tan. A geometry loss combination for 3d human pose estimation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3272–3281, 2024.