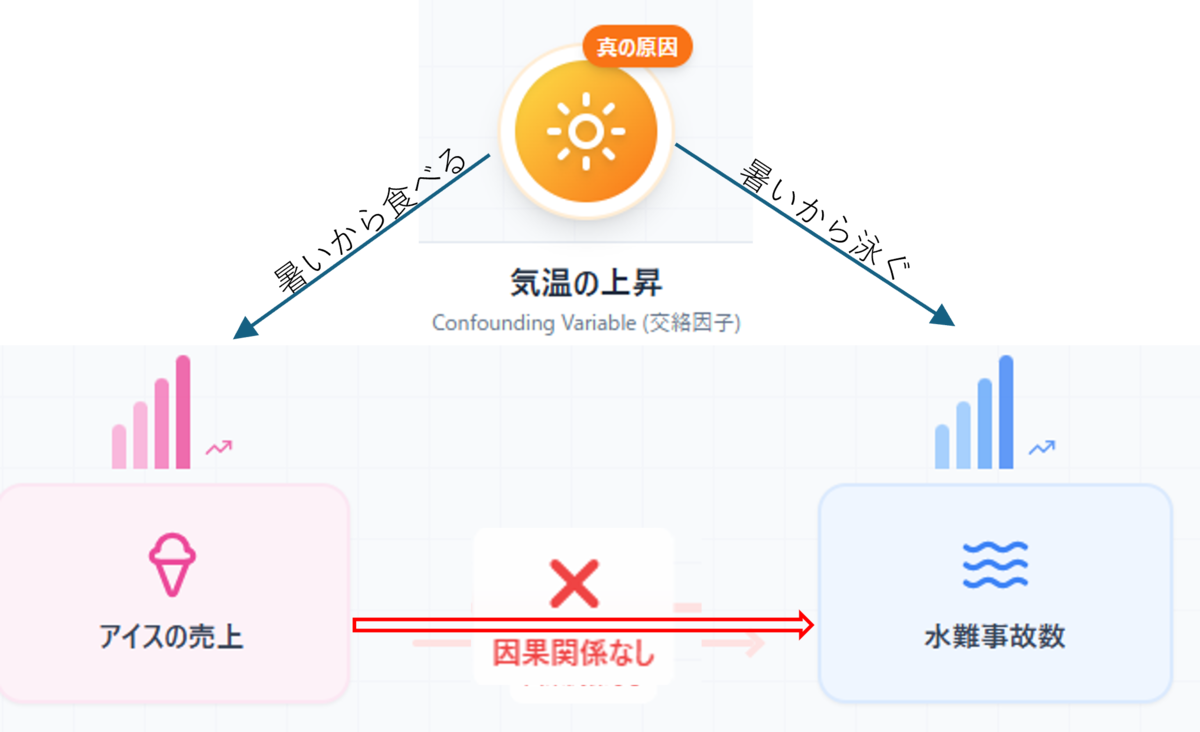
 「アイスクリームの売上が増えると、水難事故が増える」。 人間ならこの裏にある「気温の上昇」という真の原因を推測できますが、AIは表面的なデータに騙されず、正しい「因果関係」を見抜けるのでしょうか?
「アイスクリームの売上が増えると、水難事故が増える」。 人間ならこの裏にある「気温の上昇」という真の原因を推測できますが、AIは表面的なデータに騙されず、正しい「因果関係」を見抜けるのでしょうか?
本連載では、膨大なテキストから因果関係を抽出するというAIにとっての難問に挑んだ、開発と検証の記録を全3回でお届けします。高精度な抽出を行う「AI技術(矛)」と、その実力を厳しく測る「高難易度ベンチマーク(盾)」。この両輪を開発することで見えてきた、AIの限界と進化の可能性について解説します。
第1回(今回): AIマルチエージェントと高難易度ベンチマーク開発
第2回: AIに「自問自答」させる技術:マルチエージェントシステムが因果関係抽出の精度を劇的に高める仕組み(2026年4月ごろ掲載予定)
第3回: 「70%の壁」を突破せよ:高難易度ベンチマークを攻略する次世代・因果関係抽出技術(2026年7月ごろ掲載予定)
連載第1回:AIマルチエージェントと高難易度ベンチマーク開発
1. 問題提起:AIは「それっぽい嘘」を見抜けるか?
「何が原因で何が結果なのか」——この因果関係を理解することは、医療、経済、科学などあらゆる分野で不可欠です。「因果ナレッジグラフ」は、この関係性を構造化し、より高度な推論や意思決定を可能にする技術として期待されています。
しかし、その構築基盤となるテキストからの因果関係抽出は、AIにとって長年の課題でした。従来の自然言語処理(NLP)技術は、ルールベースや統計的手法に依存しており、言語特有の「曖昧さ」や「複雑な文構造」に対応しきれませんでした。
「アイスクリームの売上が増えると、水難事故が増える」——有名なこの相関は、AIが「気温の上昇」という共通の原因(交絡因子)を見抜けなければ、「それっぽい嘘(欺瞞的な相関)」に騙され、誤った結論を導き出してしまいます。
私たちは、この重要なタスクをAIに任せたいと考えました。しかし、ここで根本的な疑問が生じます。AIが「それっぽい嘘」に騙されていないと、私たちはどうやって確認すればよいのでしょうか?もし、AIの性能を測る「物差し(ベンチマーク)」自体が簡単すぎたら? AIが「賢くなった」のではなく、「簡単なテストで高得点を取るコツ」を掴んだだけだとしたら?
ここがポイント: 私たちの挑戦は、高精度なAIを作ること(矛)だけでなく、そのAIの真の実力を測る「高難易度の物差し」(盾)をも作ることでした。
2. 解決策 Part 1:AIマルチエージェント
従来の課題を克服するため、私たちは複数の大規模言語モデル(LLM)を連携させた「AIマルチエージェント」アーキテクチャを開発しました。これは、単一のLLMが持つ「予測不能な失敗モード」や性能のばらつきを、システム全体で吸収するアプローチです。
このシステムの核心は、あるLLMが抽出した因果関係の候補を、別のLLMが独立して「検証・レビュー」する多段階のプロセスにあります。AI同士が相互にチェックすることで、抽出の信頼性を飛躍的に向上させます。
AIの精度を最大化するため、各エージェントの役割を明確に定義しました。 AI-1(判定器)には、「何をすべきか」だけでなく「どう考えるべきか(思考プロセス)」の例まで明示した精緻なプロンプトを与えました。さらに、思考の精度を高めるため、少量の高品質な学習データとして「因果関係がある事例」と「因果関係がない事例」の両方を与えました。 一方、AI-2(正誤判定器)には、AI-1が出力した「因果関係の有無」の判定結果だけでなく、AI-1自身に生成させた「なぜそう判断したか」という明確で詳細な説明文も入力として与えます。これにより、AI-2はAI-1の思考プロセスそのものをレビューし、論理的な誤りや見落としがないかを厳しく検証します。
因果関係の候補を抽出 → AI-2 (正誤判定器)
AI-1の出力を厳しく検証 → 最終結果
このアーキテクチャのもう一つの大きなメリットは、コスト効率です。たとえ前段の判定器(AI-1)に比較的安価で小規模なLLMを用いたとしても、後段の検証器(AI-2)がその誤りを効果的に修正できるため、システム全体として高い精度を維持しつつ、コストを下げることができる可能性を示しました。
これにより、システムは効率的に学習し、個々のAIの性能のばらつきを吸収しながら、全体として高い精度と頑健性(ロバストネス)を両立させることに成功しました。
ここがポイント: AIが「ドラフト」し、別のAIが「レビュー」する体制により、単一AIの誤りや見逃しを劇的に削減します。
3. 従来の物差しでの成果
開発した「AIマルチエージェント」システムを、因果関係抽出の標準的なベンチマーク(SemEval-2007 Task 04)で評価しました。
この評価実験において、私たちのシステムは89.7%という非常に高い精度を達成しました。
この数値が重要である理由は、このベンチマークを作成した際の「人間同士の判定一致率(複数の人手によるアノテーションの一致率)」が約89%であったためです。つまり、AIが人間と同程度の判断能力を持つことを示唆しています。
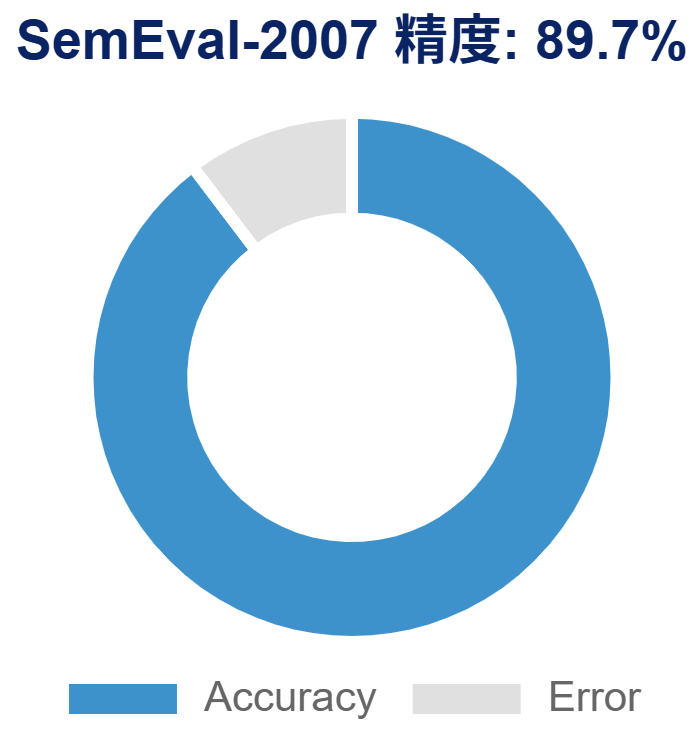
ここがポイント: 89.7%という精度は、人間による判定の一致率(約89%)に匹敵します。つまり、私たちのAIは「従来の物差し」において、人間レベルの性能を達成したことになります。一見、これで「ゴール」のように見えました。
4. 新たな課題:物差しは正しいか?
「人間レベル」を達成したにも関わらず、私たちはある強い疑念を抱いていました。それは、AIの性能を測った「SemEval-2007」という"物差し"自体が、現代のAIの能力を測るには不十分ではないか、という点です。
この従来のベンチマークは主に以下のような課題を抱えていました。
- 単純な文脈: 主に「短い文章」を対象としており、複数の文にまたがるような複雑な文脈や論理構造を評価できません。
- 汎用性の欠如: 現実世界のレポートやニュース記事、科学論文に含まれる、より長く複雑なテキストに対するAIの汎用的な能力を検証するには、全く不十分でした。
AIが「真の知性」を獲得したのではなく、単に「簡単なテストで高得点を取るコツ」を掴んだだけかもしれない。この仮説を検証し、AIの真の実力と限界を暴き出すためには、従来の物差しを置き換える、より現実に即した「高難易度の物差し」を自ら開発する必要がありました。
| 特徴 | 従来(SemEval 2007) | 従来(SemEval 2010) | 新開発 |
| 文章の長さ | 1から3文 | 1から3文 | 5文以上 |
| データ件数 | 220件 | 1003件 | 10,000件 |
| ラベル、カテゴリ | 方向性のみ | 方向性のみ | 20種類のカテゴリと難易度 |
ここがポイント: AIの真の実力を測るため、より現実に近い「高難易度の物差し」を自ら開発する必要がありました。
5. 解決策 Part 2:高難易度ベンチマーク
そこで私たちは、AIの「本当の実力」と「限界」を暴き出すため、全く新しいベンチマークを自ら開発しました。これは、AIを「意図的に騙す」ために設計された、大規模かつ複雑なデータセットです。
データ生成にはGPT-4.1を用いました。その理由は、GPT-4.1が、長文を扱い、高度な論理的推論や意図的な制約(欺瞞的な相関)を設けたデータ生成を行うベンチマーク構築に非常に適したモデルであると判断したためです。これにより、因果関係を明示せずに「もっともらしいが欺瞞的な相関」を示唆するような、難易度の高い長文テキスト(5文以上)を10,000件生成しました。
このデータセットの最大のメリットは、単に大規模であることだけでなく、ポジティブ(因果関係あり)10種類、ネガティブ(因果関係なし)10種類、合計20種類の詳細なカテゴリに分類した点にあります。
これにより、AIが特定の単純なパターンに過度に依存していないか、多様な因果推論能力を持っているかを多角的に検証できます。特に「複数の原因が絡み合う」や「隠れた要因による見せかけの相関」といった、AIが最も騙されやすい複雑なシナリオを網羅しており、システムの「汎用性」と「堅牢性」を厳しくテストすることを可能にしました。
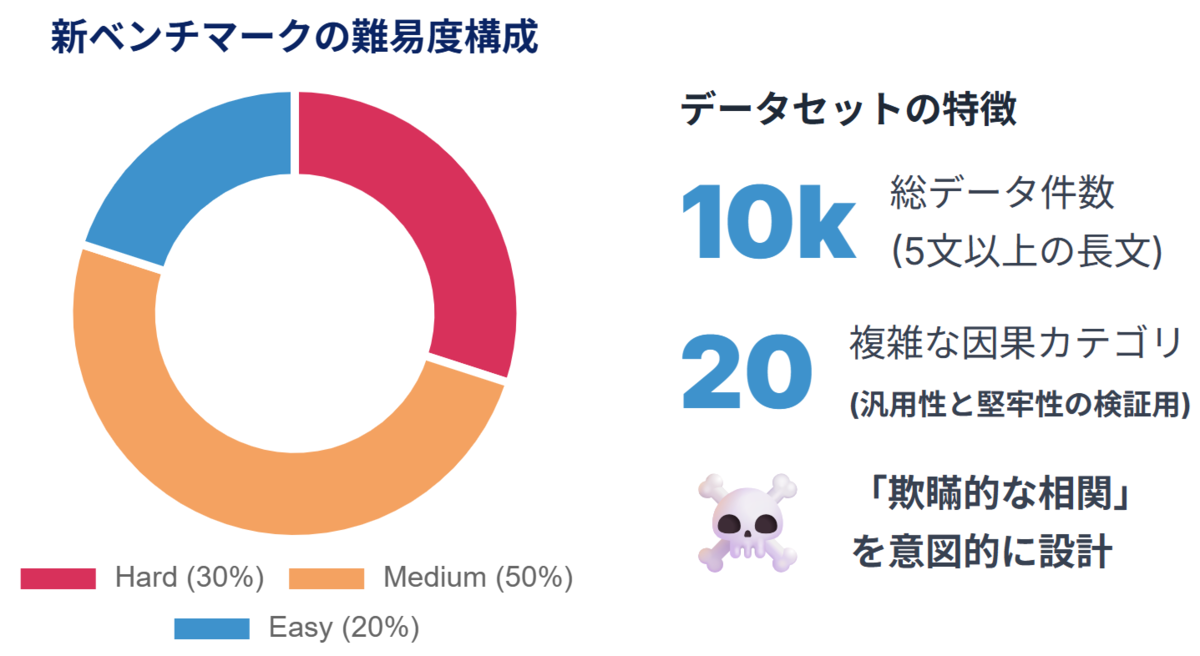
ここがポイント: グラフが示すように、データセットは「Medium」と「Hard」のカテゴリが80%を占めており、AIの限界を試す高難易度な設計になっています。
6. 衝撃の結果:AIの"化けの皮"が剥がれた
自信作であった「人間レベルAI」(マルチエージェントシステム)を、この新しい「高難易度ベンチマーク」で再評価しました。結果は衝撃的でした。
この結果が信頼できるのは、ベンチマーク自体の品質にも理由があります。PCA(主成分分析)を用いた評価により、この10,000件のデータセットが特定の分野や語彙に偏っておらず、汎用性の高い「一様な」物差しであることが統計的に示されています(第10主成分までの累積寄与率が0.366と低く、特定の主題に偏る科学論文データの0.496より有意に低い)。
偏りがなく高品質な「物差し」で測った結果、AIの精度は89.3%から70.00%へと大幅に急落しました。
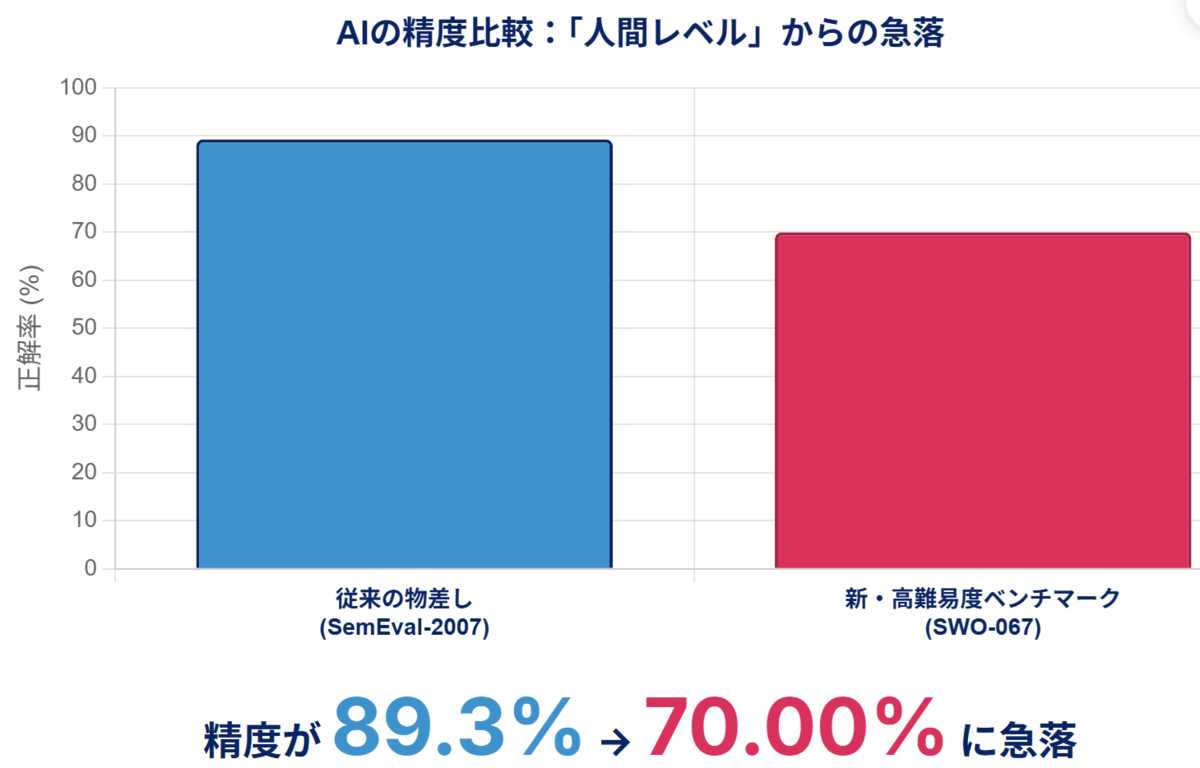
ここがポイント: これは「失敗」ではありません。従来の物差しでは見えなかったAIの「限界」を統計的に信頼できる、高品質かつ高難易度な物差しが正確に暴き出した「成功」です。AIが乗り越えるべき「本当の壁」が改めて可視化されました。
7. 今後の展望:矛と盾、その先へ
私たちは、高精度なAI(矛)と、その限界を暴くベンチマーク(盾)を同時に手に入れました。AI開発の最前線とは、「AIを作ること」と「そのAIを評価する物差しを作ること」の両輪で進みます。
今後の目標は明確です。私たちが作った「最強の盾」を打ち破る、次世代の「最強の矛」を開発することです。それには、LLMが誤った推論を行う根本原因の分析や、形式的な因果推論モデルを組み込むハイブリッドアプローチが鍵となります。
それが実現した時、AIは「それっぽい嘘」に騙されず、医療、金融、科学といった複雑な意思決定の場で、人間の真のパートナーとなるでしょう。
※本研究で開発した高難易度ベンチマークは、研究コミュニティの発展のため、一般公開を予定しています。