 こんにちは。人工知能研究所の外川、中川です。
こんにちは。人工知能研究所の外川、中川です。
富士通では企業における生成AIの活用促進に向けて、多様かつ変化する企業ニーズに柔軟に対応し、企業が持つ膨大なデータや法令への準拠を容易に実現する「エンタープライズ生成AIフレームワーク」を開発し、2024年7月よりAIサービス Fujitsu Kozuchi (R&D) のラインナップとして順次提供を開始いたしました。
本記事では、生成AIがもたらすシステム運用・保守の変革に焦点を当て、既存の設計書からテストケースの生成を自動化するテスト仕様書生成技術についてご紹介いたします。
生成AIが変革する企業システム開発運用プロセスと自動化技術
生成AIがソフトウェア開発の前提を塗り替えています。コード補完や自動テスト生成は入口にすぎず、要件定義から設計、実装、運用までの各工程で「AIを前提とした開発プロセス」へ移行が進みつつあります。大規模言語モデル(LLM)は社内文書やログを横断して知識を引き出し、仕様の草案づくりや影響範囲の推定、リリースノート作成までを高速化します。一方で、品質やセキュリティ、説明責任をどう担保するかなどの課題が取り組まれています。
特に企業システム開発は難易度が高い領域です。複雑な業務ドメイン、レガシー資産との連携、厳格な監査と可用性、頻繁な法改正への追随――これらは単純な自動生成では解けません。正確な要件の可視化・言語化、非機能要求の見える化、変更の波及を制御しながらアーキテクチャの一貫性を維持する仕組みなどが不可欠です。
富士通はこれらの課題を解決する先進的技術の研究開発に取り組んでいます。コアとなる技術は大量データを正確に参照・活用できるFujitsuナレッジグラフ拡張RAG技術です。この技術はさまざまなシーンで汎用的に活用できますが、本連載ではシステム開発・運用の自動化・効率化に焦点を当て、以下の7つの技術を紹介します。将来的には、AIが多様な開発・運用タスクで横断的にアクセスできる統合データベースとして機能させることで、要件定義から設計・実装・運用までを高信頼かつ適切に統制のとれた形で推進するマルチエージェントシステムの構築を目指します。

表1:技術が適用できるシステム開発・運用プロセス
| 要件定義 | 設計 | 実装 | テスト | 運用 | 保守 | |
|---|---|---|---|---|---|---|
| (1)システム仕様可視化 | 〇 | 〇 | ||||
| (2)設計書レビュー支援 | 〇 | |||||
| (3)設計書-コードチェック | 〇 | 〇 | ||||
| (4)テスト仕様書生成 | 〇 | 〇 | ||||
| (5)障害分析 | 〇 | 〇 | ||||
| (6)ログ分析 | 〇 | 〇 | ||||
| (7)QA自動化 | 〇 | 〇 | 〇 |
(1) システム仕様可視化 (ナレッジグラフ拡張RAG for Software Engineering 公開中)
本技術はソースコードをデータとして、ソースコードを理解するだけでなく上位の機能設計書や要約を生成、モダナイゼーションを可能にします。
(2) 設計書レビュー支援 (公開中)
複雑な構造のシステム設計書を生成AIが理解できるよう変換することで、システム設計書の曖昧性・整合性のチェックを自動化します。
(3) 設計書-コードチェック (Code Specification Consistency Analysis 公開中)
本技術は、ソースコードと設計書を比較して差分を検知、問題個所を特定することで、障害発生時の原因調査を短縮します。
(4) テスト仕様書生成 (本記事)
本技術は、既存の設計書とテスト仕様書からテストケースを洗い出すルールを抽出することで、プロジェクトの特性を考慮した抜け漏れのないテスト仕様書の生成を可能にします。
(5) 障害分析 (ナレッジグラフ拡張RAG for Root Cause Analysis 公開中)
本技術はシステムのログや障害事例のデータをもとに、障害発生時のレポートを作成し、類似する障害事例をヒントに対策案を提示いたします。
(6) ログ分析 (ナレッジグラフ拡張RAG for Log Analysis 公開中)
本技術はシステムログのファイルを自動で分析し、障害の原因特定や異常検知、予防保守に関する専門性の高い質問に回答することが可能な技術です。
(7) QA自動化 (ナレッジグラフ拡張RAG for Q&A 公開中)
本技術は製品マニュアルなどの膨大なドキュメントデータを対象に、全体を俯瞰した高度なQ&Aをおこなうことを実現します。
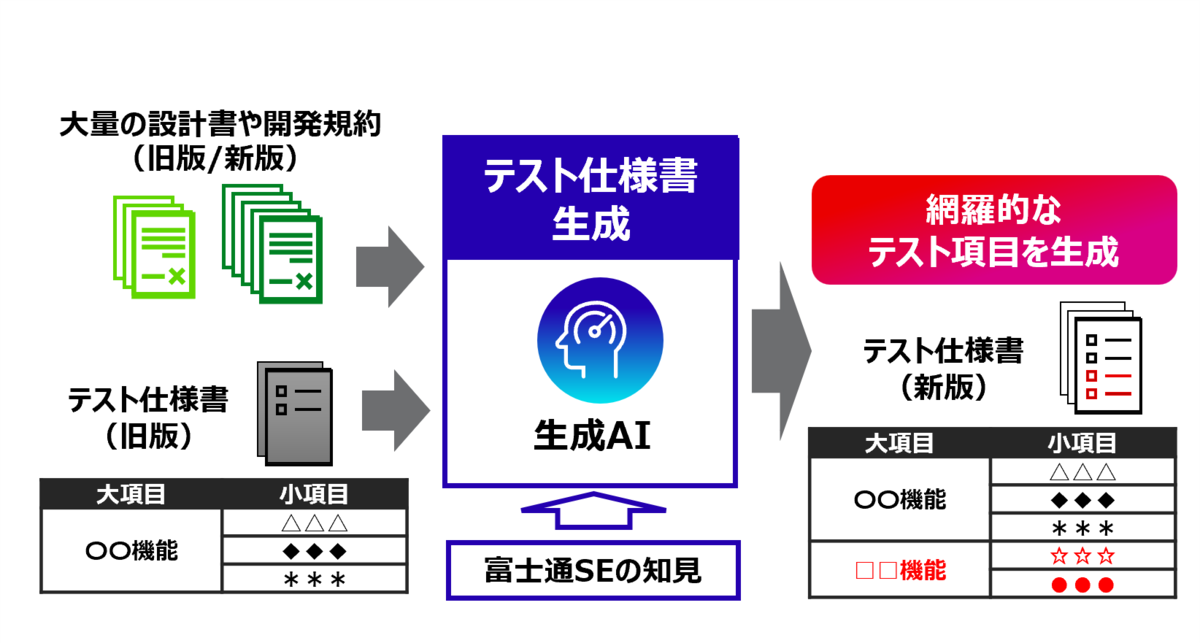
本記事では、(4)テスト仕様書生成技術について詳しくご紹介します。この技術は、生成AIを活用して大量の設計書や開発規約等の資料群の読み込みと解析を行い、富士通SEのナレッジを活用することで、テスト項目を生成することができる技術です(図1)。
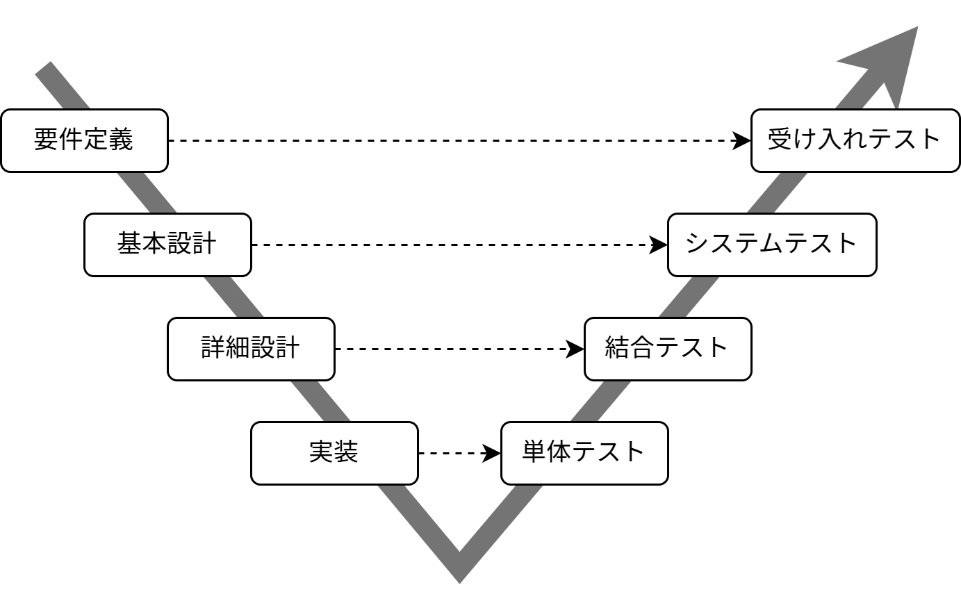
ソフトウェア開発におけるテストとは
富士通では金融・行政といったミッションクリティカルなシステムを含む多種多様なソフトウェアを開発しています。要件定義、設計から運用保守にわたるソフトウェア開発においてテスト工程はシステムのリリース前の信頼性確保のために必要不可欠で非常に重要な工程です。
図2はソフトウェア開発における、設計工程とテスト工程との対応関係を示したもので、V字モデルと呼ばれています。これによると、設計・実装の各工程と個々のテスト工程には対応関係があります。そのため、設計と同時に設計の抽象度に応じたテスト仕様を決定し、実装後にテストを実施することが想定されています。
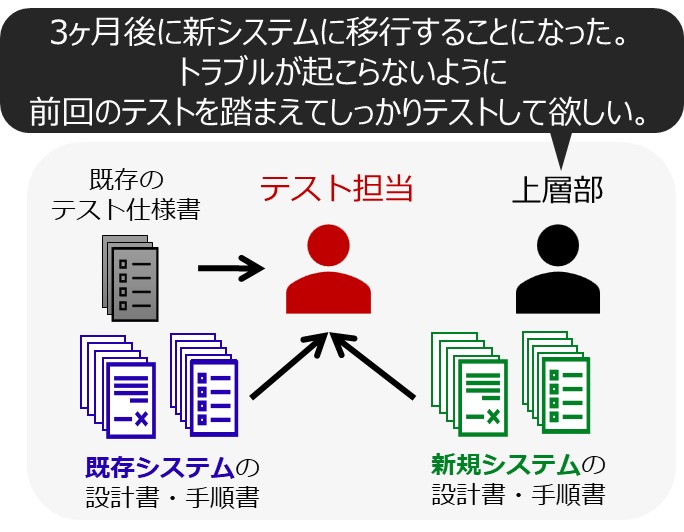
従来は、システム全体の設計や運用を熟知している有識者が、ソフトウェアの改修内容に対応するテストケースを作成し、テストを実施していました(図3)。しかし、システム規模が大きくなるほど影響範囲は広くなり、また設計書間の依存関係も複雑で暗黙の依存関係が多く含まれるため、設計変更の影響を受けるテスト範囲の特定およびテストケースの策定は非常に困難でした。さらに、システム更新があった場合に全設計書や過去のテスト資料を読み直すなど膨大な時間を要しており、テスト担当者の作業負荷が高くなる課題がありました。
また、最近では生成AI技術の進歩により、設計を理解できる可能性のあるAIが登場し始めており、これを利用して大量のテスト仕様書や設計書を読むことが可能になりつつあります。このような技術の導入により、従来は高度かつ手間がかかっていたテスト仕様書の更新も自動化でき、負荷軽減にも、人間とのダブルチェックによるテストケースの網羅性・品質の向上にも役立つことが期待できます。
テスト工程における課題
さて、実際にこのような課題をAIに解かせるためには何が必要でしょうか。 たとえば「設計書の改修箇所の全行について、既存テスト仕様書の全行と比較し、影響有無を判別する」というのはどうでしょうか。このアプローチは素直ですが、「改修行数×仕様書行数」に比例する大量のAIへの問合せを必要とします。仮に複数の設計書に影響されるテスト仕様があれば、考慮すべきパターンは天文学的な数になってしまうでしょう。また、仮に全てのパターンを網羅できたとしても、AIの不確実さのために大量の誤った改版が提案され、自動改版の精度自体も落ちてしまうことでしょう。
テスト仕様書の改版シナリオ
この課題を解くため、わたしたちは「もともとのテスト仕様書が作られた手順」に注目しました。開発プロジェクトには一般に、どの設計項目に対し、どんなテストを行うかを定めた計画や標準が存在するため、各テスト仕様の根拠にあたる記述が設計書・テスト計画・標準のどこかにあるはずです。この関係性に基づいて、どの設計書の改修が、どのテスト仕様書に、どのように影響するかを予め判断できれば、比較すべき設計書・テスト仕様を絞り込み、効果的で高精度な自動改版を実現できるでしょう。
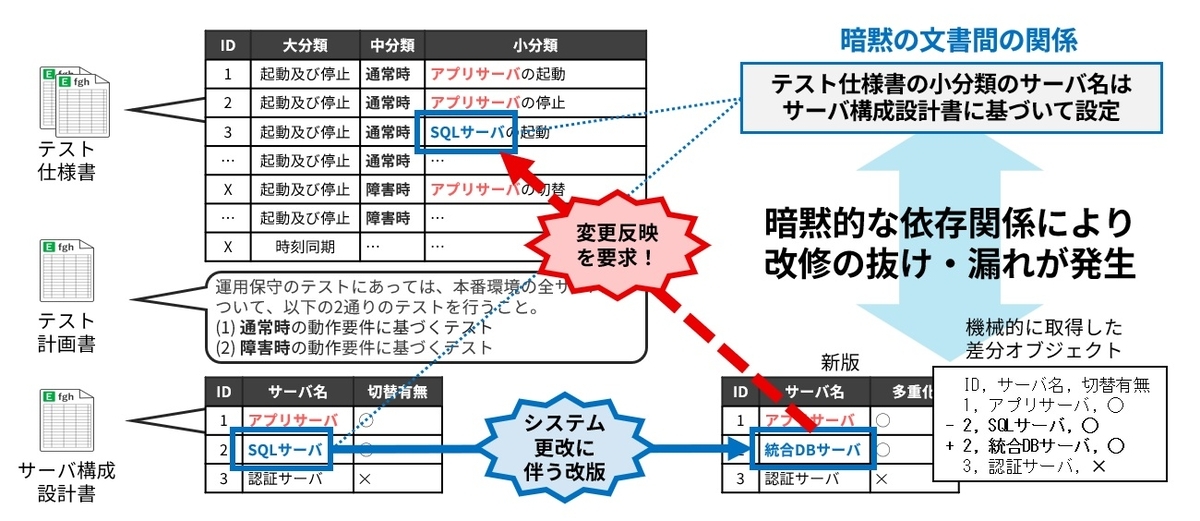
しかし残念ながら、このような「テスト仕様-根拠記述」間の関係性(トレーサビリティ)は多くの場合手に入らないか、あっても不完全なものでしょう。すなわち、関係性が暗黙知化したり、失われたりしているのです。図4に示したテスト仕様書にはシステムを構成する各種のサーバの起動や停止に関するテスト項目が列挙されています。ここで、実のところテスト仕様の「小分類」には「サーバ構成設計書」に記述された各サーバを列挙するというルールがあるのですが、それは暗黙知化しています。
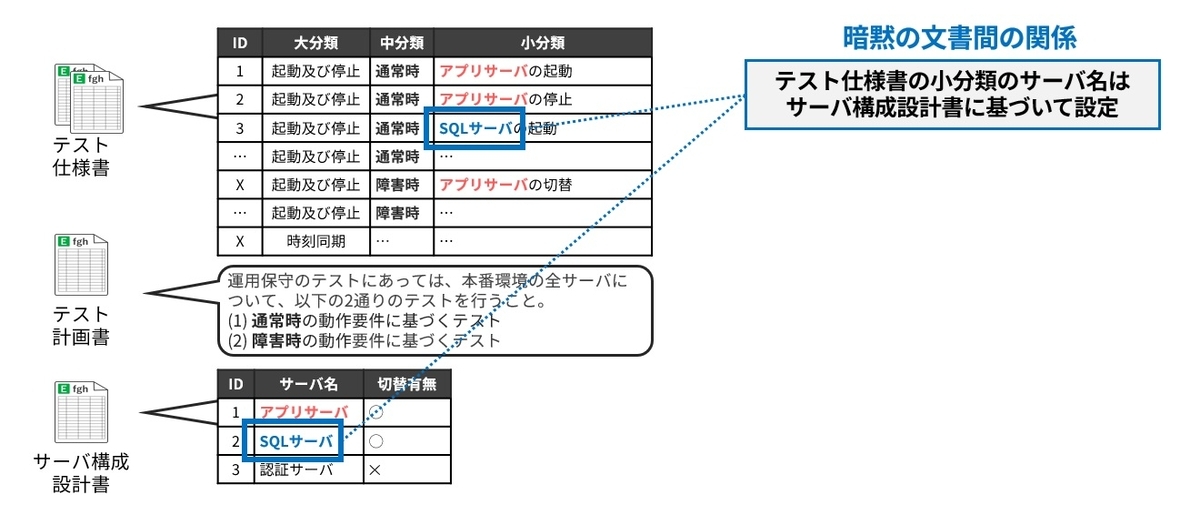
ここで、図5のように仮にサーバ構成設計書が改修されるとしましょう。改修前はSQLサーバとなっていたものが、統合DBサーバという別種のサーバに変わっています。この変更はテスト仕様書にも反映されるべきなのですが、もし先の暗黙知化した関係性を知っている有識者が全員いなくなっていとしたら、どうでしょうか。誰かがこの関係性に気づくまで、テスト仕様書の改修を見落としたり、最悪の場合、古い記述に基づくテストが削除されるだけになるかもしれません。
従来手法とその課題
実は、このような暗黙知化した文書間の関係性を再発見しようとする研究テーマがあります。トレースリンク回復と呼ばれる分野で、成果物(文書やソースコード)間の依存関係、派生関係や類似性などを情報検索、機械学習などに基づいて同定します。ここへ近年の生成AI(特に、テキスト生成AI)の発展があわさり、同定した関係性(リンク)の意味、つまり「具体的にどういう関係なのか?」を説明するタスクとして、トレースリンク説明が登場しました。 強力な技術にみえるトレースリンク説明ですが、自然文を使って説明するだけあって、とりうる説明の観点が非常に多く、タスクの目的に応じて観点を選んであげる必要があります。また、説明観点をどう選ぶかということが、そもそも発見できるトレースリンクの種類や質に影響するという指摘もあります。そのような中で、他方の改版がもう一方にどのような影響を及ぼすべきかを明らかにできるようなトレースリンク説明手法は、今のところ提案されていないという現状があります。
技術の特長・概要
幸いなことにわたしたちの目的は明らかで、それは (目的A)テスト仕様書に影響を与えた設計文書を特定し、 (目的B)その設計文書を変えるとテスト仕様書にどう影響するかを説明することです。そこで、あるテスト仕様(の集合)が記述される原因となった作業手順(記述ルール)を説明できれば、改修影響波及という観点でのリンク回復・説明を達成できると考えました。その上で、図6に示すような3ステップに問題を分割して解くことを目指しました。
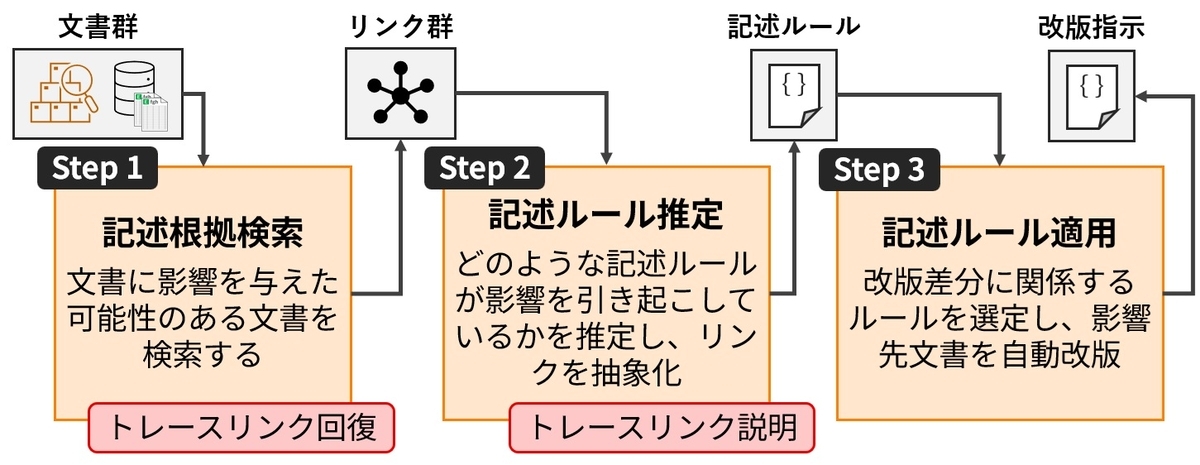
Step 1. AIエージェントによる記述根拠検索
第一のステップでは、ある文書に影響を及ぼした可能性のある文書を自律的に特定します。今回はマルチターンで自律思考を行う、ReAct型のAIエージェントにキーワード検索や類似度検索のツールを渡して設計文書群を探索させ、根拠になった可能性の高い文書を列挙させています(図7)。Step 2.で確実性と抽象度の高い「ルール記述」に集約する際に内容の正確さを検討するため、この段階では、完璧さは求めず、あくまでそれらしい根拠候補を発見することが目的です。
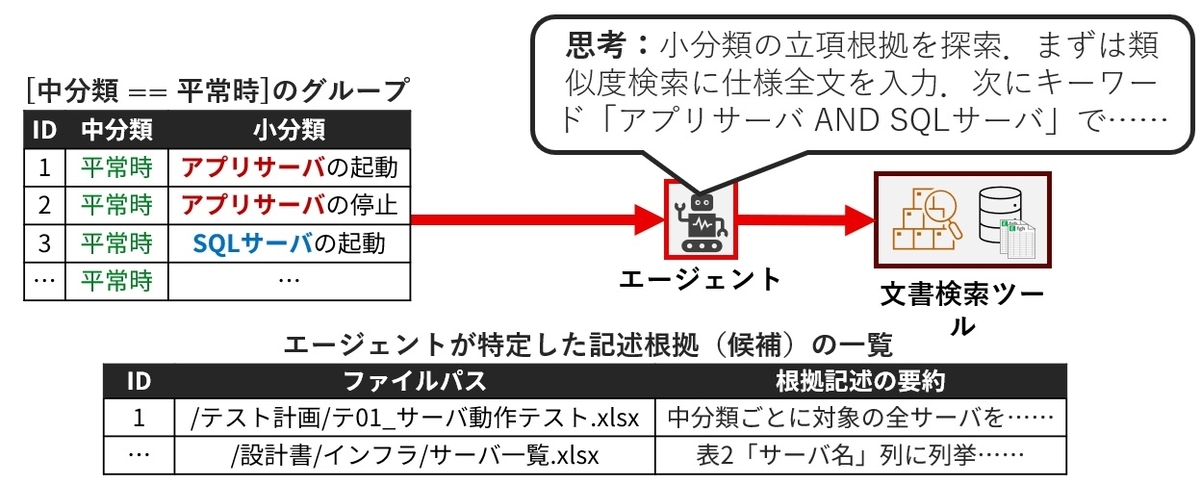
Step 2. 生成AIによる記述ルールへの抽象化
次に、Step 1.で収集したリンクの集合を生成AIに確認させ「テスト仕様の記述ルールを特定してください」という依頼を投げ、ばらばらのリンク群をルールの形にまとめあげます(図8)。もちろん、現在の生成AIの能力では、単に上記のような指示のみでは高品質な記述ルールを導くことはできません。

根拠候補の探索では、たとえば行単位や項目単位など、具体的で細かい単位で候補を列挙しますが、実際の記述ルールは図4でも説明したように、一つのルールで複数のテスト仕様を導けるような形になっているケースが多く見られます。一方でStep 1.で抽出した候補には誤りも含まれるため、どのリンクを最終的な記述ルールの根拠として残すかの判断基準を与える必要があります。 今回わたしたちは、「より多くのリンクを説明できる最小の根拠候補を選択する」というヒューリスティック(経験則)を判断基準として与えることで、少数の記述ルールで多くのことを説明することを目指しています。実際のソフトウェア開発の流れにおいても、なるべく簡潔な計画・標準から網羅的なテスト仕様を作成できるよう目指していると考えられ、このような経験則を当てはめています。 ただし、手に入る文書群には根拠がそもそも記述されていないケースや、複雑すぎて同定できない場合を考慮し、多くの事象を説明できる共通ルールと、少数の例外事例を記述するための例外ルールという区分を設け、抽象化から漏れてしまう項目をなるべく取り扱えるようにする工夫も行いました。 なお、Step 2.までは現行資産の分析プロセスになるため、改修に先立って実行しておくことができます。
Step 3. 改修差分(Diff)に基づく記述ルールの適用
第三のステップでは実際に改修が起きた時、その内容を記述ルールと突き合わせて、テスト仕様の更新を行います(図9)。ここでは、設計書の改修内容をどう与えるかということがポイントになります。設計書はプロジェクトによって形式がまちまちで数百ページという大きなサイズになる場合もあります。
そこでわたしたちは、設計文書の差分(以降, Diff)を機械的に取得して生成AIに読み込み、章・節の切れ目を答えさせてDiffを小さなパーツに分割する方法を取りました。あとは、各改修差分に対して、ルールとの対応関係があるかどうかを生成AIに判別させ、関連性がある場合は、テスト仕様書に対する改修内容をJSON形式で提案させるだけです。
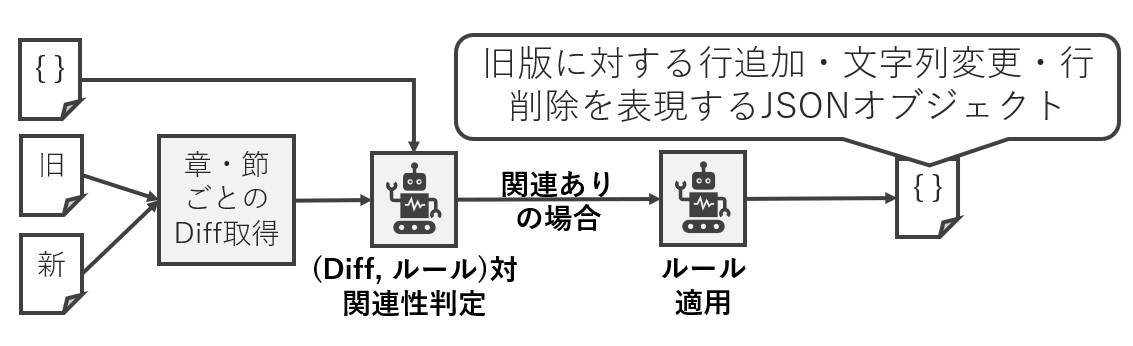
ここまでの内容をいつでも一気通貫に実行できれば素晴らしいのですが、実際にはかなりの数のAIによる判断が間に挟まっています。特にStep 2.のルール抽象化では抽象度がやや不足するルールや、内容の重複するルールが得られることもあります。そのため、人手による確認やブラッシュアップも行うことで、さらに高品質なルールを得ることが成功の秘訣になります。一度正しいと確認できたルールは次回以降の改修でも使い回せるため、この作業は初回だけ必要な暗黙知の言語化作業になっており、その意味でも有用であると考えています。
技術導入の効果
①誰でも自動でテスト項目を設計可能!
本技術をソフトウェア開発のテスト工程に導入することで、システム開発の知識・経験が必要でこれまで困難だったテスト項目の網羅的な抽出が可能になります。
あるプロジェクトのテスト設計に本技術を適用する検証評価を行ったところ、人手で判断したテスト項目の70.6%(12項目/17項目)を本技術で抽出できることを確認しました。実用に向けて更なる精度改善が必要ですが、将来的には経験の浅いエンジニアでも生成AIの支援を受けながら経験豊富なエンジニアと同等のテストを実施することが期待できます。
②システム変更時の作業負荷を軽減!
図表を含む膨大な設計書(旧版/新版)から、生成AIが追加・変更となるテスト項目を自動生成するため、テスト担当者による資料の読み直し等の作業負荷を軽減することが期待できます。
おわりに
本記事では、生成AIを活用することでテスト項目を自動生成する「テスト仕様書生成」技術について紹介しました。 本技術による取り組みは、第8回機械学習工学研究会(MLSE夏合宿2025)にて優秀発表賞を受賞し、日本ソフトウェア科学会第42回大会にて招待講演を行いました。 また、本技術はFujitsu Kozuchiに搭載されており、Webアプリケーションにおいて利用者が用意したシステムの設計書(旧版/新版の2種類)、テスト計画書、および旧版のテスト仕様書をブラウザ上でアップロードするだけで、設計書の改版内容に基づいたテスト項目を生成することができます。そのため、今後システムの改修計画がある運用・保守部門のみなさま、本技術を是非お試し下さい。
なお現在はテスト項目生成の精度向上や汎用化のための取り組みをしているほか、対応するテストコードを自動生成する技術との連携を進めており、将来的には様々な業種・業務システムにおけるテスト工程全体の自動化を目指しています。