
はじめに
こんにちは、富士通研究所 コンピューティング研究所の高です。富士通研究所は、オリコン1位を獲得した楽曲55作品を手掛けた著名音楽プロデューサー井上純氏率いる株式会社Amadeus Code(以下、Amadeus Code)と共同で、音楽クリエイターの創作活動をサポートする生成AIを開発しました。今回は開発経緯と技術的な仕組みを紹介します。
音楽制作におけるアイデア枯渇や表現の限界は、多くのクリエイターが直面する課題です。 想像力を掻き立てる閃きを求め、試行錯誤を繰り返す日々…。 そこで、今回開発した音楽生成AIは、クリエイターのインスピレーションを最大限に引き出し、既存の枠にとらわれない独創的な音楽創造を支援します。AIとの協働により、創造性を高め、想像を超える音楽表現の可能性を切り開くことを目指します。
音楽制作におけるボトルネック
プロの作曲家であっても、楽曲完成には数ヶ月を要することが珍しくありません。音楽制作は、高度な音楽理論、演奏スキル、編曲技術を駆使し、聴衆の心を動かす芸術作品を生み出す複雑なプロセスです。 特に、制作時間の7~8割を占めるとされるアイデア出し(共同研究者・井上純氏談)は、クリエイターにとって大きな負担であり、「クリエイターズブロック」と呼ばれる、全くアイデアが浮かばない状態に陥ることも少なくありません。 既存の技術や知識に囚われ、斬新な表現を生み出すことに苦慮することもあります。 また、ヒップポップのビートメイキングなど、既存楽曲のサンプリングを用いる場合には、著作権問題への対応も、著作権保護の観点では重要な工程である一方で、クリエイターにとっては大きな制作コストとなります。
生成AIと共創する新たな音楽制作
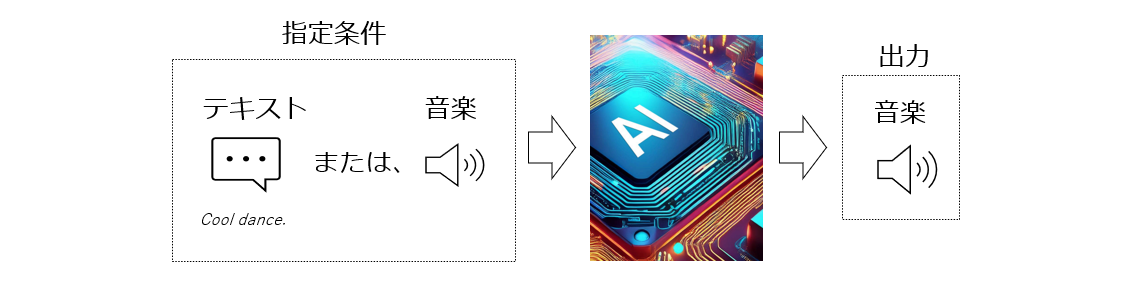
音楽制作における課題を克服するため、富士通研究所はクリエイターの創造性を拡張する革新的な音楽生成AIを開発しました。この音楽生成AIは、テキスト入力だけで、インスピレーションの源泉となる楽曲を自動生成します。更に、生成された楽曲を入力し、任意の長さで続きを生成することも可能です。
その実力を検証するため、音楽家との共創実験を行いました。ヒップホップのビートメーカー/DJである呼煙魔氏、ギタリストのYukihide"YT"Takiyama氏(以下YT氏)、そして共同研究者の井上氏の3名が、AIが生成した(ドラムとベースを除いた)楽曲素材をベースに楽曲制作に挑戦しました。ヒップホップなどのビートメイキングにおいては、ベースとドラムパートがクリエイターの腕の見せ所である為、今回のAIによる楽曲生成ではこれらのパートは除外されています。本実験では、呼煙魔氏がドラムとベースを追加してビートトラックを作成した後、YT氏が即興演奏的にギターパートを加え、最後に井上氏がベースとシンセを追加するというプロセスで、半日で5曲もの楽曲を作成することができました。
このようなクリエイティブな楽曲制作には、従来であれば数ヶ月を要することも珍しくありませんでした。
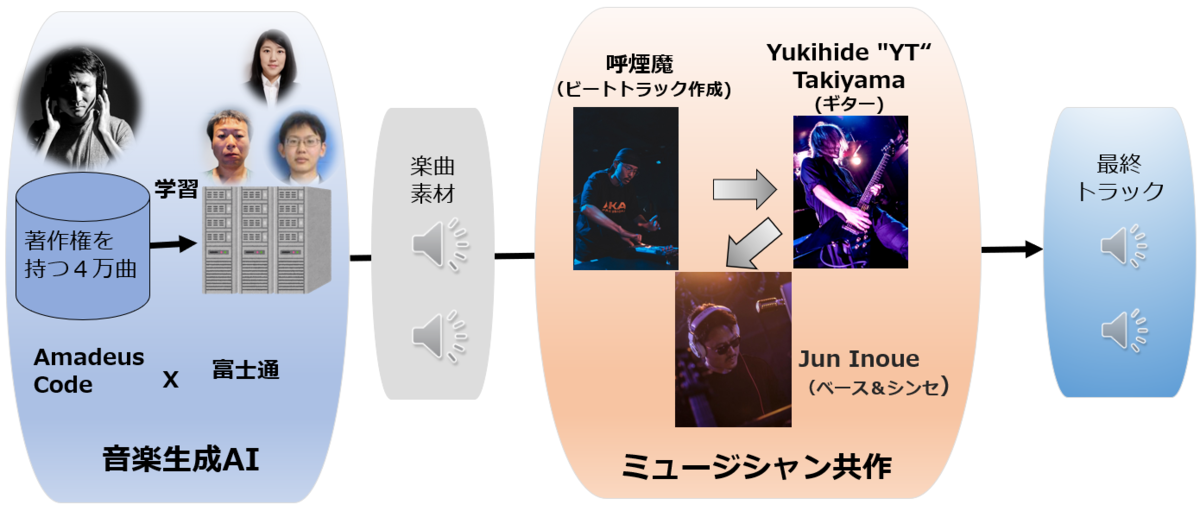
この共創ワークフローは、生成AIによる楽曲原型の自動生成によってアイデア出しの時間を大幅に削減し、制作効率を飛躍的に向上させます。クリエイターは、AIが生成した素材を基に独自のアレンジや調整を加えることができます。さらに、AIが提案する斬新なサウンド、メロディー、スタイルは、クリエイターに新たなインスピレーションを与え、想像を超える表現への挑戦を可能にします。AIとの共創を通じて、従来は不可能だった斬新な表現や新しい音楽スタイルの開拓に挑戦できます。
音楽生成AIの仕組み
今回開発した音楽生成AIは、トランスフォーマーベースのモデルを用いて音楽の時系列データを処理することで、メロディーやコード進行など、楽曲全体にわたる依存関係を捉え、複雑な音楽構造を表現できます。以下の4つのステップで楽曲を生成します(下図)。
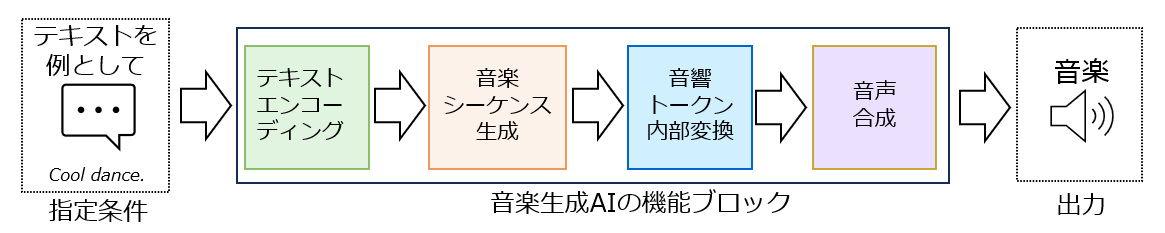
ユーザーがジャンル、テンポ、ムード、楽器などを入力したテキスト(例:「Cool dance.」)は、その言葉で表される音楽的な特徴量の数値表現であるトークンに変換されます。これをテキストエンコーディングと呼びます。テキストと音楽データ間の対応関係を理解するために、事前に大量の音楽データとそれに付与されたテキストでモデルの学習を行います。音楽データからの継続生成の場合は、同じモデルを使って音楽的特徴を直接エンコードしてトークンを生成します。
次に、トランスフォーマーベースのモデルが、このテキストエンコーディングで生成されたトークンに基づき、音楽のシーケンス、つまり時間的な流れを予測します。この音楽シーケンス生成においては、メロディー、ハーモニー、リズムなどの配置や進行が決定され、楽曲の骨格となる構造が構築されます。
その後、生成された音楽シーケンスのトークンは、より詳細な音楽特徴量を含むトークンに内部的に変換されます。
最後に、これらの音響情報を用いて、音楽合成器が最終的な音声データ(.wavファイル)に変換します。
このように、複数のモデルを巧みに組み合わせることで、入力に応じて自動的に音楽生成を実現しています。
著作権問題への対応
生成AIにおける重要な課題である著作権問題への対策として、共同研究先のAmadeus Codeが保有する高品質なオリジナル楽曲4万曲(平均約3分間)をデータセットとして利用しました。既存のモデルに対するファインチューニングではなく、スクラッチからの学習を行い、著作権リスクを回避しています。 このデータセットは、音楽シーケンス生成と特徴抽出だけでなく、テキストエンコーディングモデルの学習にも用いられています。プロの音楽家による楽曲のジャンル、使用楽器、雰囲気などの詳細なアノテーションデータを含んでおり、AIが音楽的特徴を正確に理解するための基盤となっています。
高速化への取り組み
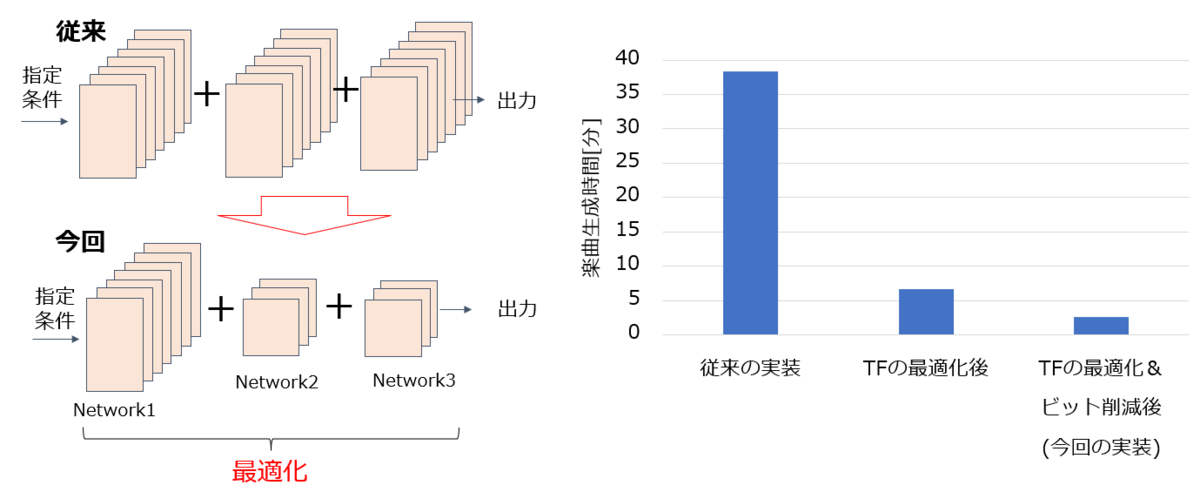
同じ機能の音楽生成AIの実装例では、A100 GPUを用いた場合、1分間の楽曲(15秒×4曲)生成に約38.3分を要していました。そこで、処理速度の高速化を目指し、トランスフォーマー構造 (TF) の最適化に着手しました。特に、処理時間の88%を占めていた、2段階のトランスフォーマーで構成される音響トークン内部変換部分を重点的に軽量化することで、ネットワーク全体の効率化を図りました。その結果、実行時間を38.3分から6.7分に短縮することに成功しました。さらに、ビット削減技術を適用することで、実行時間を2.6分まで短縮し、従来実装と比較して15倍の高速化を実現しました。なお、この高速化による音楽品質への影響は軽微であることを、高速化後の音楽例で確認しています。
テンポ・和音崩れ検出による生成楽曲の自動選別
AIによるコンテンツ生成では(楽曲生成だけでなく画像生成等においても)、生成されたコンテンツの一部が崩れてしまうことがあります。コンテンツ制作に活用するために、クリエイターは崩れのないコンテンツを選別する必要があります。
本研究では、テンポ・和音に崩れが生じている生成楽曲を自動検出する機能を実装しました。 本機能では、事前に設定した閾値を超えるテンポ・和音の崩れを示す楽曲を自動的にフィルタリングすることで、クリエイターの楽曲選別の労力を削減し、楽曲制作に集中できる環境を提供します。
但し、テンポ・和音崩れが時にクリエイターにインスピレーションを与える事もある為、フィルタリングの有無は設定可能です。
今後の展望
テキスト入力に応じて、自動的に音楽を生成できるAIを実現しました。Amadeus Codeのデータを活用することで、クリエイターは従来の生成AIの課題であった著作権の問題を気にすることなく、楽曲制作に活用可能です。また、最適化されたモデル構成により、実用的な生成速度を達成しました。 今後の研究では、より多様な音楽ジャンルへの対応とさらなる高速化、そしてより直感的なユーザーインターフェースの実現に取り組んでまいります。クリエイターの皆様と共に進化するAIを目指し、音楽制作の可能性をさらに広げていきます。