こんにちは。富士通研究所サイバーフィジカル融合基盤PJのmacです。
私たちの部署では、ストリームデータ処理基盤技術 Dracenaを開発しています。また、この基盤を素早く活用できる様に、社内向けにDracena環境を提供するサービス運用も行っています。Dracenaの紹介は別のメンバーにお願いすることにして :-) 、今回はサービス運用にまつわるOSS活用のお話をさせていただきます。
収集メトリクスの巨大化
多段でのメトリクス収集
Dracena環境の提供サービスでは、環境提供と同時に、ちゃんと動いているか、どの様な使われ方をしているか、といった分析を目的として、各ユーザ向けDracena環境の動作状況をサービスメトリクスとして収集しています。
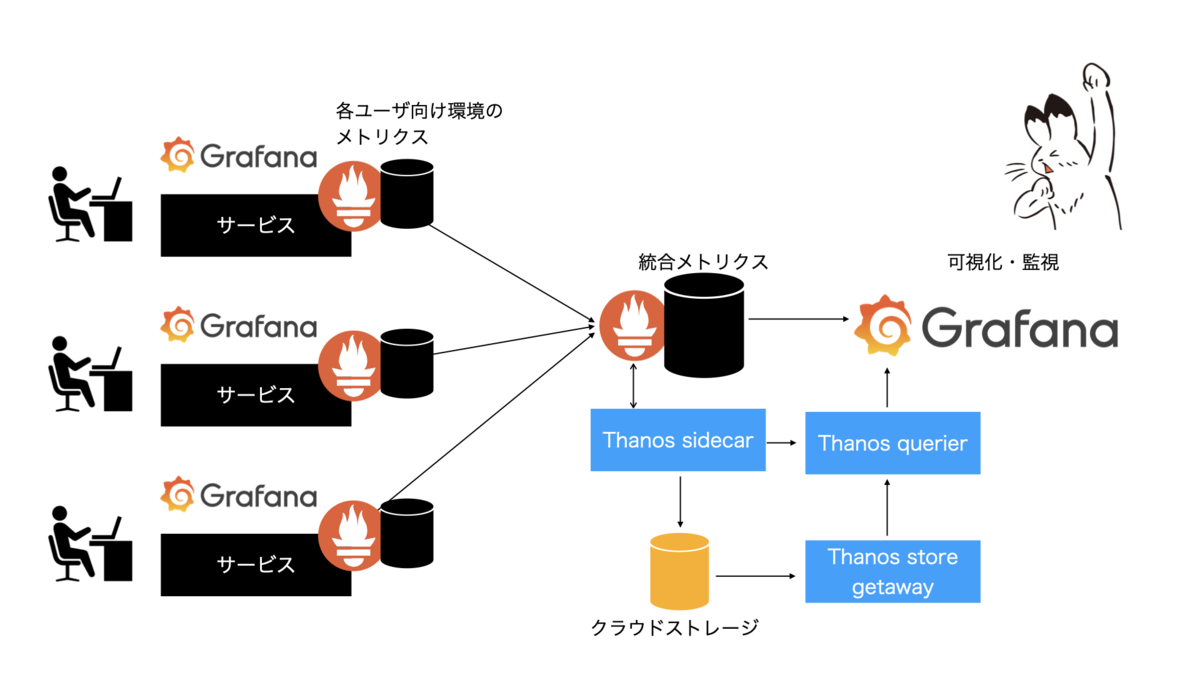
メトリクス収集と可視化には、定番ともいえるPrometheusとGrafana を使っています。Dracena環境のユーザは、自分のサービス稼働状況を確認できるように、Dracenaの各機能のメトリクスを収集・閲覧することができるようになっています。一方で、我々サービス運用者としては、各ユーザ向け環境の動作状況を一目で俯瞰できるようにしたいと考え、ユーザ環境Prometheusと管理者向けPromethuesの2段階構成を取りました。この構成にすることで、ユーザは自分のメトリクスだけを閲覧でき、管理者は全環境のメトリクスを横断的に可視化することができるようになります。

メトリクスの巨大化による問題
さて、この構成、サービス開始当初は問題なく動いていましたが、ユーザが増加してきたのに合わせて、管理者むけPrometheusが落ちるようになってしまいました。原因を探ってみたところ、ユーザ増加に伴いPrometheusが扱うメトリクスが増大、結果としてPrometheusの動作に必要なメモリやストレージといったリソースが増加してしまうという状態になっていることがわかりました。当初はメモリやストレージを増強することで凌いできましたが、費用も増大してしまいますので、何かしらの対策が必要です。
対策を色々と探ってみたところ、メトリクスを外部ストレージに逃すことで対処できそうなことがわかってきました。Prometheusは、内包している時系列DBにメトリクスを保存しますが、標準ではローカルファイルシステム上にデータを保持します。また直近のメトリクスをできる限りメモリに保持しようとします。そのため、ユーザ数が増加→保持すべきメトリクスが増加→メモリやストレージが不足する、という状態になっていたようです。ユーザ数が増加しても、メトリクスをPrometheus管理下から逃してあげることで、保持しているメトリクスを減らすことができそうです。
Thanosによる解決
この様なことできるツールはいくつかありますが、今回は、Thanosを使うことにしました。
Thanosの概要
Thanosは、Prometehusと合わせて使うことで、データの長期保存ができるようになるOSSです。データの保存先にオブジェククトストレージが利用できるため、ファイルシステムに保存するよりも安価にメトリクスを保存することができます。また、保存してあるメトリクスに対してもPromQLで問い合わせることができるため、Grafanaでの可視化もPrometheusと同じようにアクセスできます。
Thanosは大きく5つのコンポーネントで構成されています。
- Sidecar: Prometheusと連携し、queryからの要求の処理、オブジェクトストレージへメトリクスの保存などを行います
- Store Gateway: オブジェクトストレージのメトリクスを取得します
- Querier/Query: PromQLによるメトリクス取得要求を受け付けます
- Compactor: オブジェクトストレージ上のメトリクスを整理します
- Ruler/Rule: 保存されたメトリクスを対象としてアラートマネージャにアラートをあげます

Thanosの組み込み
今回は、まずはThanosを試してみようということで、管理者むけPrometheus環境にThanosを取り込んでみました。統合メトリクス収集を行うPrometheusにThanos sidecarを配備、そこからクラウドストレージ(今回はAWS S3を利用)に保存、Grafanaとのインターフェースとしてquerierとstore gatewayを利用します。CompactorとRulerは、まずは導入しませんでした。
管理者むけPrometheus環境はdocker-composeを利用して構成しているので、docker-compose.yamlファイルに以下のような項目を追加します。
services: : prometheus: : grafana: : thanos-sidecar: image: thanosio/thanos:master-2019-12-14-bec86666 volumes: - ./thanos:/etc/thanos - promdata:/prometheus command: - 'sidecar' - '--tsdb.path=/prometheus' - '--prometheus.url=http://prometheus:9090' - '--grpc-address=0.0.0.0:10091' - '--http-address=0.0.0.0:10902' - '--objstore.config-file=/etc/thanos/bucket_config.yaml' depends_on: - prometheus thanos-querier: image: thanosio/thanos:master-2019-12-14-bec86666 command: - 'query' - '--grpc-address=0.0.0.0:10091' - '--http-address=0.0.0.0:10902' - '--query.replica-label=dpprom' - '--store=thanos-sidecar:10091' - '--store=thanos-store-gateway:10091' ports: - 10902:10902 depends_on: - thanos-sidecar thanos-store-gateway: image: thanosio/thanos:master-2019-12-14-bec86666 volumes: - ./thanos/:/etc/thanos/ command: - 'store' - '--grpc-address=0.0.0.0:10091' - '--http-address=0.0.0.0:10902' - '--data-dir=/tmp/thanos/store' - '--objstore.config-file=/etc/thanos/bucket_config.yaml'
こうして組み込んだシステムを起動し、GrafanaのデータソースにPrometheusとしてthanos-querier:10902を指定、従来のGrafana PanelのデータソースをThanosに変更すると、無事、今までと同じ使い勝手でGrafanaによる監視が可能になりました。

まとめ
これでThanosにより、オブジェクトストレージにメトリクスの大半を逃すことができるようになりました。ファイルシステムメモリの消費を抑えることができ、また、長期保存が可能になりましたので、月間でのサービス利用状況統計もエビデンス込みで取得可能になり、月・年単位でのSLOの確認が可能となりました。
今回は、お試しということもあり、統合PrometheusにThanos sidecarを導入しましたが、各環境のPromethusにThanos sidecarを導入することで、統合PrometheusをThanosに置き換えることでき、さらなるリソース消費の削減ができるのでは、と考えています。