
はじめに
こんにちは。富士通株式会社ICTシステム研究所のMLPerf HPC五人衆です。先週、国際学会SC’21 において、理化学研究所/富士通が共同で開発した新しいスーパーコンピュータ(スパコン)「富岳」がスパコンランキングで4期連続の4冠(TOP500, HPCG, HPL-AI, Graph500)を獲得しましたが、同会議で発表された、実際のディープラーニング(DL)学習処理に特化したMLPerfTM HPC ベンチマークにおいても世界一を獲得しました。 本ブログでは、このMLPerf HPCの一つのアプリケーションであるCosmoFlowの学習を「富岳」で大規模に行い世界一となった、その挑戦についてお話させてもらいます。
背景
MLPerf HPCって何?(白幡)
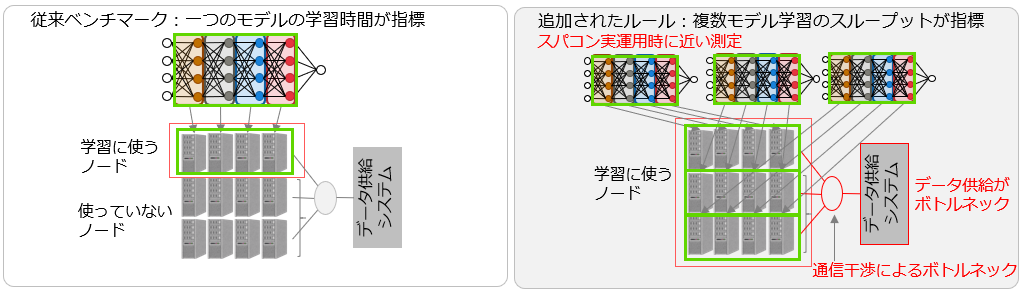
MLPerf HPC ベンチマークスイートは、科学シミュレーションデータセットでの大規模なモデルトレーニングなど、HPCシステムでの新たな機械学習ワークロードの特徴を捉えるために2020年に策定されました[1]。MLPerf HPCは、気候分析や宇宙論に関連するタスクにおいて、科学データでの機械学習モデルを学習するのにかかる時間を測定します。2020年に行われたMLPerf HPC v0.7(第1回)ではCosmoFlowとDeepCAMの2つの新しいベンチマークが策定されました。v0.7では1つのモデルを学習するのにかかる時間(strong scaling)を指標として測定が行われていました。
実際のHPCシステムでは、同時に多数の処理が実行されますが、従来の指標では同時多数処理でしか顕在化しない性能ボトルネックの影響が出ない状態で測定が行われていました。そこで、2021年に行われたMLPerf HPC v1.0 (第2回)[2]ではシステム全体を用いて多数のモデルを同時に学習させる際のスループットを競う指標(weak scaling)が新たに導入されました。同時に多数のモデルを学習させることで、スパコンが実際に運用される場面に近いAI処理性能を測定します。主にスパコンシステム上でパラメータサーチ等を並列に行う際の指標と解釈することができます。ファイルシステムから各計算ノード(1つのA64FX プロセッサを搭載したサーバに相当し、「富岳」は158,976台のノードがある)へのデータ供給(データステージング)や並列計算での通信干渉によるボトルネックが発生するためシステム全体の性能やそれを使いこなす技術が重要となります。Weak scalingでの結果を見ることで、ユーザは適切なスパコンを選ぶことができるようになると考えられます。
CosmoFlowって何?(田渕)
CosmoFlowは宇宙現象を解明するためのDLモデルです。3次元空間のダークマターの分布を入力として与えて、宇宙論における4つの重要なパラメータを予測します。このモデルは畳み込み層、プーリング層、および全結合層から成る典型的な畳み込みニューラルネットワーク(CNN)ですが、入力が3次元空間データであるため3次元畳み込み層を用います。そのため、画像を処理するために2次元畳み込み層を用いる一般的なCNNよりも必要な計算量が多いという特徴があります。 学習データはN体シミュレーションによって生成された多数のダークマターの分布データです。4つのパラメータの値とそれを用いて生成されたダークマターの分布データをもとに、ダークマターの分布から逆にパラメータの値を推測するように学習します。ダークマター分布の入力データは128×128×128の大きさで、1サンプル当たり16MBのファイルサイズがあります。MLPerf HPC v1.0では学習用に512Kサンプル、検証用に64Kサンプルが用意されているためデータセットは合計で約9 TBにもなります。この学習データを使って学習を行い、検証データでの誤差が一定値を下回る(Mean Absolute Error (MAE)≦0.124)までの時間を測定します。1台のGPUを使うと1週間程度かかる非常に計算量の多いベンチマークです。
「富岳」って何?(田渕)
「富岳」は、スーパーコンピュータ「京」の後継機として理化学研究所に設置された計算機で、令和2年6月から令和3年11月にかけてスパコンランキング4部門で1位を4期連続で獲得するなど、世界トップの性能を持ており、令和3年3月9日に本格運用が開始されています。
プロセッサ
「富岳」のプロセッサ(CPU)はスマートフォンなどでも広く使われているARM命令セットを採用したA64FXです。SVE (Scalable Vector Extension)と呼ばれるベクトル演算に対応した計算コアが48個あり、さらに32GBの広帯域メモリ(HBM2)がオンチップで搭載されているため、多数のデータを高速に計算できます。「富岳」にはこのプロセッサを1つ搭載した計算ノードが全部で158,976ノードあります。
通信ネットワーク
すべてのノードはTofuDという通信ネットワークで接続されています。これはスーパーコンピュータ「京」で使われていたTofu通信ネットワークの後継です。6次元メッシュ/トーラスと呼ばれるネットワーク形状で多次元的に接続されており、非常に高速に通信を行うことができます。実際には6次元形状ですが、ユーザへは48x69x48の3次元形状として見えており、複数のノードで計算を実行する際には使用するノード形状を3次元形状で指定します。
ストレージ
「富岳」では、16台の計算ノード(BoB=Bunch of Bladesと呼ぶ)ごとに、SSDストレージが用意されており、これを第1階層ストレージと呼びます。通常、このストレージは計算ジョブごとに次に紹介する第2階層ストレージのキャッシュや、データステージング、一時保存ファイルなどに使用します。 共有ストレージとしては、Fujitsu Exabyte File System (FEFS)が使われており、これが第2階層ストレージとなり、ユーザはデータやプログラムをここで作成・保存します。
準備
環境の構築、チューニング(山崎)
次に、「富岳」でCosmoFlowを動かす方法についてご紹介します。
TensorFlow + OneDNN for aarch64
今回チャレンジしたCosmoFlowアプリケーションは、深層学習の基盤ソフトとして広く使われているTensorFlowを用いています。もともとTensorFlowは、CPU環境でもGPUを搭載した環境でも動作しますが、オリジナルのままでは「富岳」のプロセッサであるA64FXが持つSVEというベクトル命令はサポートされていませんでした。 「富岳」の性能を引き出すためには、この命令を活用する必要があります。私たちの部では、昨年OneDNN for aarch64ライブラリを開発しました。 blog.fltech.dev このリンクのブログで紹介しているように、Convolutionなどの重い処理についてはXbyakというJIT(Just In Time)コンパイラ(最適なコードをその実行に作成したうえで実行する仕組み)を用いてA64FX プロセッサ向けの実装を行い、さらにXbyak translator for aarch64という仕組みで、より多くの既存のIntel社製CPU向けに最適化されたコードを利用する仕組みを開発しました。 今回の測定には、このOneDNN for aarch64を組み込み、他にも高速化カスタマイズを行ったTensorFlow for aarch64を使用しました。このTensorFlowは、富士通よりgithubで公開されています。
Mesh TensorFlow
また、私たちは昨年Mesh TensorFlowと組み合わせて、2種類の並列動作に対応させました。 Mesh TensorFlowは、昨年取り組んだMLPerf HPC v0.7(第1回)のCosmoFlowの学習処理高速化のために取り入れたライブラリで、データ並列と、モデル並列という2種類を同時に行う事ができます。 私たちは昨年、データ並列とモデル並列という2種類の手法を用いて、1つの学習処理を「富岳」全体のおよそ10分の1(16,384ノード)を使って、CPUベースのスパコンとしては最高の性能を実現しました (MLPerf HPC v0.7)。
Weak scaling
今年のweak scalingでのチャレンジにおいては、「富岳」により多くの学習処理(インスタンス)を詰め込むことも重要です。つまり、もし一つの学習処理に使用する計算ノードを半分にしても、計算時間が2倍より短い場合には、そちらのほうがより良い性能となります。この時、スケーラビリティという、計算ノード数に対する性能の向上率が重要になります。実のところ、データ並列に比べてモデル並列は、このスケーラビリティの値が良くありません。そこで、今回はデータ並列のみを使うことにし、さらにより少ない演算量で収束が見込めるようバッチサイズも減らし、1つの学習処理(インスタンス)は128ノードとすることにしました。 このようにして、実行できる環境が整いました。まず小規模ではじめ、徐々に大きな規模で実行しながら、調整(チューニング)を行いました。チューニングは、地道にプロファイル(処理を細分化してタイミングとかかっている時間を網羅的に取得すること)をとりながら、時間のかかっている部分の特定をします。 次の章からは、「富岳」での大規模ならでは、の対策について紹介します。
処理の同期、スケジューリング(田渕)
ジョブ間同期
weak scalingの計測では複数のモデルを同時に学習し、学習開始時間の最も早い時間から学習終了時間の最も遅い時間までを全体の時間として測定します。開始時間を揃えたほうがより良い結果が得られるため、学習開始直前にモデル間での同期を行いました。
通常のスパコンでは、実行したい処理をジョブとして登録します。ジョブが実行できるだけコンピュータが空いてくると、ジョブが実行されます。通常、ジョブ内のノード全体でMPI(Message Passing Interfaceという並列コンピュータで広く使われている規格、ソフトウェア)を使用して他のノードと同期をとります。しかし今回は複数のモデルをジョブ内で実行し、かつ複数のジョブを同時に実行するため、この方法ではモデル間での同期ができません。そこで同期が開始時の1度だけである点に着目し、FEFS上にフラグファイルが置かれるまで待機するというシンプルな方法を利用しました。この方法でも開始時間のずれは1秒未満であり、十分な性能が実現できました。
ジョブの配置
「富岳」の大規模実行で利用可能なノード数は「富岳」全体の約半分である82,944ノードで、これらのノードの形状は48x36x48です。1つのモデルの学習に用いるノード数は、学習時間、ノード当たりのデータ量、学習の収束性などの観点から128ノードとしました。すなわち128ノード×648モデルを同時に実行することになります。しかし、一つのジョブから、数百にも及ぶようなMPIプログラムを実行することは、「富岳」でも想定されていませんでした。そのため、富岳運用やSEの担当者様へ相談、調整させていただき、ジョブを分割して挑戦できることになりました。方法としては、まず24x6x48の形状のジョブを12個同時に実行し、さらに各ジョブの中で8x2x8の形状のモデルを54個実行することで648モデルを実行することにしました。
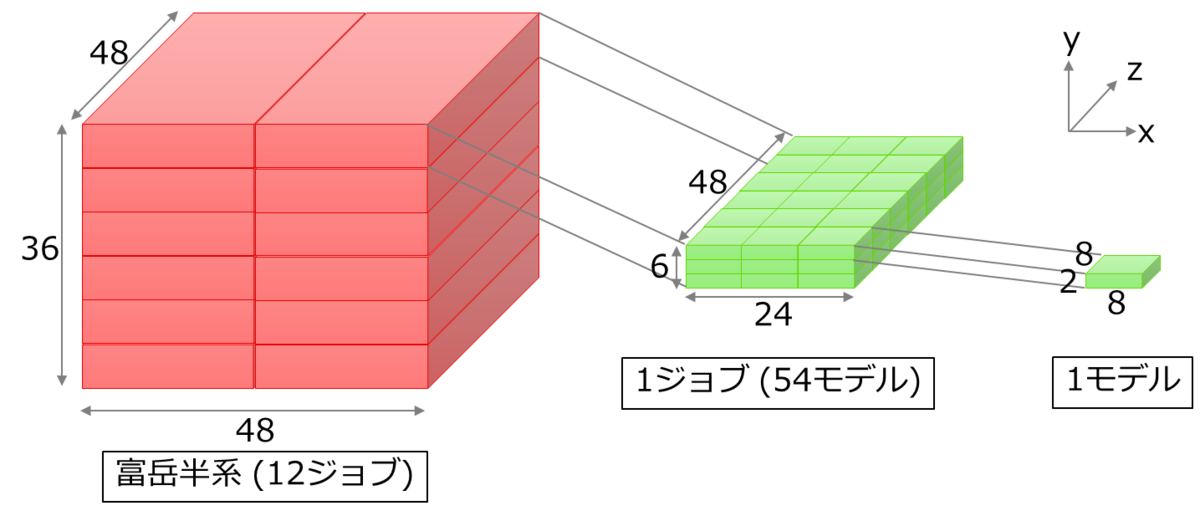
また一つのモデルの中のノード配置についても、高速化(通信によるオーバヘッドを最小にするため)に重要です。DLの学習処理では1ステップ(バッチと呼ばれる数十個から数百個のデータ単位で行う、推論、勾配算出、重み調整の処理単位)ごとに勾配を集約するallreduce通信が実行されます。各モデルのプロセスが立方体かつ一筆書きできるようにノードにマッピングすることで、多数のモデルでも TofuD 通信ネットワーク上で高速に通信が可能となります。
データの準備、ステージング(笠置)
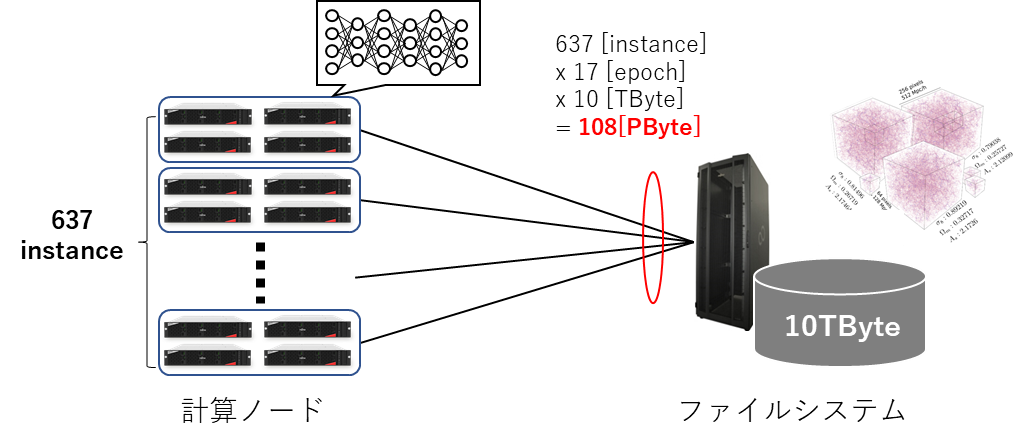
深層学習では大規模な入力データを使用し、そのデータを数十~数百回(1回をエポックとも呼ぶ)ニューラルネットワークに読み込ませる事で学習を行います。MLPerf HPCのCosmoFlowでは約9 TByteのデータセットを使用するので、一つのニューラルネットワークは9 TByte×エポック回数のデータを入力する必要があります。MLPerf HPCのWeak scalingでは、さらに数百ものニューラルネットワークモデルが同時に動作するため、入力データへのアクセス回数と通信量は非常に大きくなります。
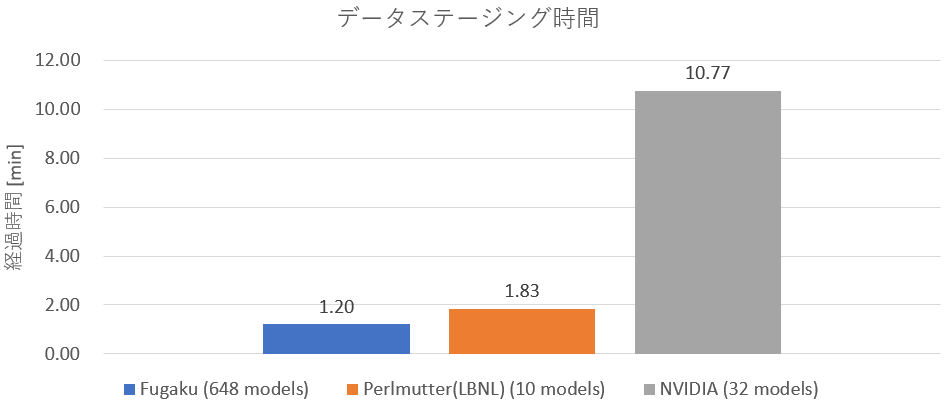
データステージングはHPCの分野では広く用いられる手法で、ファイルシステム上の入力データを必要な分だけをローカルなディスクへコピーし、ファイルシステムへの通信回数、及び、通信量を軽減する手法になります。例えば、我々が測定したCosmoFlowがデータステージングを実行しなかった場合、以下の図のような負荷がファイルシステムにかかります。
「富岳」でのステージング
「富岳」では計算時だけでなくファイルシステムであるFEFSとのデータ転送に対してもTofuD通信ネットワークを使用して通信を行います。このTofuD通信ネットワークは集合通信に対して非常に優れた通信性能が得られるため、この特性を活かしてステージングを行います。 「富岳」ではA64FXによる計算ノードが2つ搭載されたブレードサーバを大量に並べて構成されています。このブレードサーバ8つ分をBoBと言います。「富岳」では1つのBoBに対してLLIO(Lightweight Layered IO-Accelerator)が搭載されており、BoB上の計16基の計算ノードの第1階層ストレージキャッシュとして動作します。 CosmoFlowのデータセットのステージングには2つの手法で高速化しています。1つ目はデータの圧縮です。データセットは約9 TBですが、TensorFlowのデータ形式であるTFRecordはgzip圧縮に対応しており、これを用いるとサイズを1/6程度まで削減できます。それにより必要な通信帯域も削減することができます。2つ目はMPI通信によるデータセットの配布です。各モデルが使用するデータセットはすべて同じなので、1つのモデルを担当するノードがFEFSからデータセットを読み出し、それを他のモデルを担当するノードにMPIで配布しても結果は同じになります。FEFSへのアクセス集中を解消し、Tofu通信ネットワークで高速に集合通信を行うことで、1モデルのみの学習と同程度のステージング時間を実現できます。このステージングを行うMPIプログラムは、学習処理とは別に、ジョブ単位で実行しています。
結果(白幡)
8つの主要なスーパーコンピューティング機関が参加し、新しいweak scaling(スループット指標)で提出された8件を含む30件以上の結果が発表されました。今回のベンチマークには、アルゴンヌ国立研究所(ANL)、スイス国立スーパーコンピューティングセンター(CSCS)、富士通と理化学研究所の共同チーム、Helmholtz AI(ユーリッヒスーパーコンピューティングセンターとカールスルーエ工科大学のSteinbuch Centre for Computingの共同プロジェクト)、ローレンスバークレー国立研究所(LBNL)、米国立スーパーコンピュータ応用研究所(NCSA)、NVIDIA、テキサス先端計算センター(TACC)が参加しました。
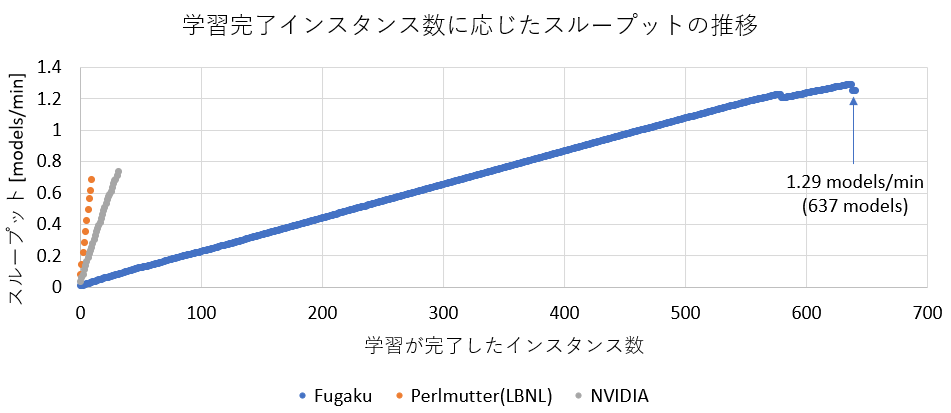
富士通と理化学研究所の共同チームは「富岳」を用いてCosmoFlowに参加しました。「富岳」全体の半分強となる82,944ノードを用いて測定し、インスタンスあたり128ノードを用いて648インスタンスを同時に学習させました。その結果、637インスタンスまで学習が完了した時点(495.66分)でスループットが最大となり、他のシステムの1.77倍である1.29 models/minとなりスループット性能世界一を達成しました。
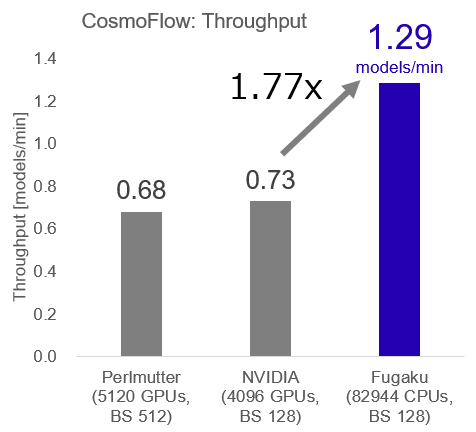
今回、他システムでは32インスタンスまでしか同時に学習できていないのに対し、「富岳」では637インスタンスを同時に学習させることができており、スループットの推移を比較すると、インスタンス数の増加に応じてスループットも増加していることが確認できます。
まとめ(田原、白幡、笠置、田渕、山崎)
昨年に引き続き、今年もMLPerf HPCにおけるCosmoFlowアプリケーションの大規模実行にチャレンジしました。 Weak Scaling(スループット)性能が高いということはすなわち、様々なDLアプリケーションの性能向上のための大規模なハイパーパラメタ探索などを効率的に行える、という事になります。この分野においても「富岳」が世界一を達成したということは、DLを用いたAI高性能化に今後も貢献し続けていけることを示せたと思います。 チャレンジの中では、事前に想定した準備・対策を行った上での測定でしたが、幾度となく大規模実行ならではの問題に遭遇しました。大規模での測定は限られた日程の中で他の課題実施者との調整で深夜に及ぶこともありました。また、長時間の実行の中でハード故障等にも遭遇しましたが、「富岳」運用関係者、SEメンバの手厚いサポートのおかげで、最終的にほぼ理想に近い性能で完走させることができました。この場を借りてお礼申し上げます。 今後もAIやシミュレーションの高性能化を通じて、社会課題解決へ貢献していきたいと考えています。
参考
[1] MLPerf HPC v0.7 results, LIST
[2] MLPerf HPC v1.0 results, LIST