
こんにちは。人工知能研究所 AutoMLプロジェクトの木村です。人工知能研究所では、研究所の先端AI技術を公開するためのプラットフォーム Fujitsu Kozuchi を通して、多くのお客様に我々の技術を素早く提供することで価値検証と技術の改善を迅速に進めていく取り組みを行っています。 この度、Fujitsu KozuchiのいちコアエンジンとしてAutoMLプロジェクトが開発している、Fujitsu AutoMLのデモアプリを以下のURLで一般公開しました。
https://automl.jp.fujitsu.com/
この記事では、デモアプリの内容と利用方法について紹介します。
Fujitsu AutoMLとは?
AutoML (機械学習自動化)は、与えられたデータに対する機械学習タスクを自動化する技術分野です。 Fujitsu AutoMLは、CSV形式の表データと機械学習の要件を入力として、その要件に合った機械学習モデルを構築するためのプログラムを、データ前処理や探索的データ解析 (EDA)も含めて自動生成することができます。 以下の記事で紹介されているSapientMLが技術の土台になっていますので、技術的な詳細は以下の記事をご参照ください。
ICSE2022でコード生成型AutoML - SapientMLについて発表しました
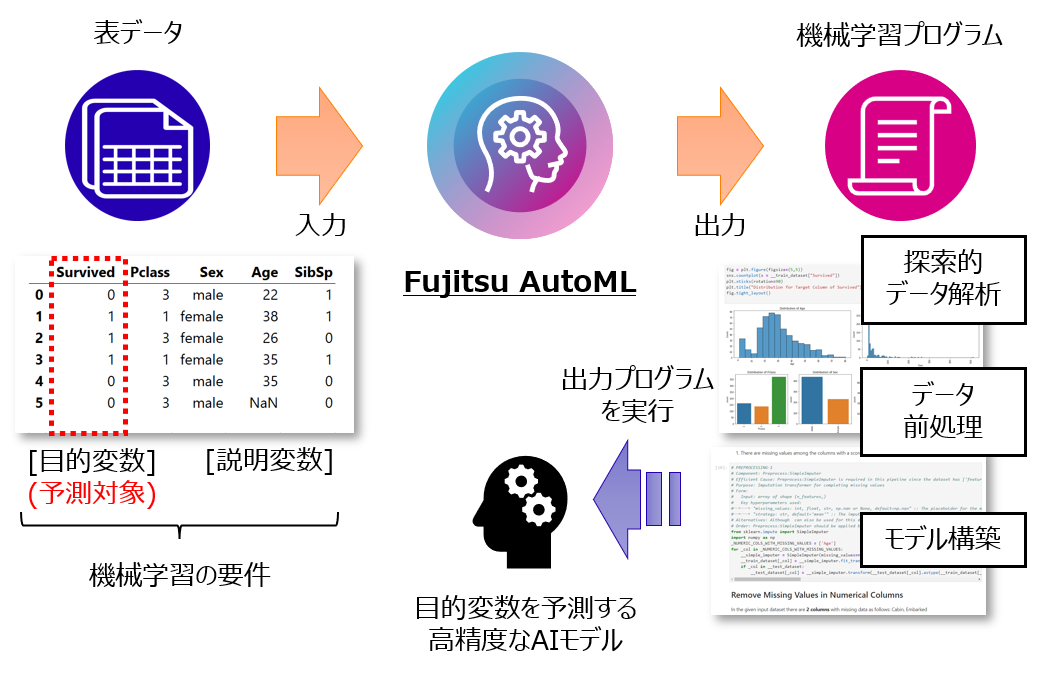
Fujitsu AutoMLを試してみよう
以下のURLをクリックしてください。
https://automl.jp.fujitsu.com/
利用規約をお読みになり「同意して続ける」をクリックすると、以下の画面に遷移します。

1. データセット、機械学習の要件を指定する
デモアプリでは、「サンプルデータセットを利用する」をクリックして手軽にお試しする方法と、お手持ちのCSVをアップロードして試す方法の2通りで進めることができます。 データセットの指定を終えると、学習データのプレビューと機械学習の要件の設定項目が表示されます。

機械学習の要件の各項目の説明は以下の通りです。
タスクの種類
(必須項目) 機械学習タスクの種類として classification (分類)、 regression (回帰)のいずれかを選択します。
目的変数
(必須項目) 機械学習タスクで予測させたいカラム名を選択します。
学習に利用しないカラム
機械学習モデルの学習時に無視させたいカラム名を選択します。
評価指標
機械学習モデルの評価するための評価指標を選択します。選択可能な評価指標は以下の通りです。
classification→F1,AUC,Accuracy,Gini,LogLoss,ROC_AUC,MCCregression→R2,RMSLE,RMSE,MAE
タイムアウト
Fujitsu AutoMLにより生成した機械学習プログラムを実際に実行して構築されるモデルの評価を行う際の、1回のコード実行に対するタイムアウトを指定します。
ランダムシード
乱数生成用のランダムシードを指定します。
データ分割時の学習データの割合
Fujitsu AutoMLでは指定されたデータセットを内部で学習データ、テストデータに分割しますが、その際の学習データの割合を指定します。
ハイパーパラメータ探索
「有効にする」をチェックすることで、モデルのハイパーパラメータ探索を行うコードを生成コードに含めます。その際の「試行回数」と「ランダムシード」も指定します。
データの説明
EDA等のコードを生成コードに含めます。「Permutation Feature Importanceを計算する」については、データセットのカラム数が100を超えると膨大な時間を要するようになるため、チェックしていても計算がスキップされる点にご注意ください。
2. コード生成を実行する
データセット、機械学習の要件を指定した後、「コード生成を開始」をクリックして開始します。 データセットの大きさ、パラメータの内容によりに実行にかかる時間は大きく変わります。 コード生成結果では、選択された前処理とその順序、機械学習モデルの候補上位3つと検証時のスコアを確認することができます。 Fujitsu AutoMLでは、検証時のスコアの最も良かったモデルを選択し、それに合わせた生成コードを出力します。
最良スコアの生成コードの真下に「生成コードをダウンロードする」ボタンがあります。これをクリックすると、表示されたコード以外にEDAを含めたJupyter Notebook (.ipynb)形式のノートブックや、モデル学習、予測用のコード等を含めたzipファイルをダウンロードすることができます。
注意:EDAが含まれているのはzipファイル中の .ipynb のみになります

3. 結果を詳しく見る
コード生成結果の下では、モデルに対する特徴量の重要度や目的変数と特徴量の関係を可視化しています。

4. 生成コードで構築したモデルで予測を実行する
最後に、生成されたコードで構築したモデルを用いて予測を実行することができます。 予測するデータを学習データと同様にアップロードします。サンプルデータセットを用いた場合は「サンプルデータセットを利用する」をクリックしてください。 予測するデータのプレビューの下の「Predict」ボタンをクリックすると予測の実行が始まり、予測結果とメトリクスを見ることができます。

Fujitsu AutoMLの今後にご期待ください
ぜひ、みなさんもFujitsu AutoMLデモアプリを触って、Fujitsu AutoMLの価値を体験いただければと思います。 私たちは今後も継続してFujitsu AutoMLの性能改善・機能追加をしていきますので、Fujitsu AutoMLの今後にご期待ください。