
はじめに
こんにちは。AutoMLプロジェクトの菅原です。
今回は、データサイエンティストではない現場の担当者がFujitsu AutoMLを使ってAIモデルを作成するという実証実験についてご紹介します。
この取り組みは、Pocket RD様との共同によって行われたものです。 pocket-rd.com
Fujitsu AutoMLについてはHugging Face SpacesよりOSS版をお試しいただけます。 huggingface.co
OSS版であるSapientMLのコントリビューターも随時募集しております。
Pocket RD様の抱える課題
Pocket RD様では、AIを使ったアバター作成サービス*1を展開しようとしています。
写真をインプットとして、その人専用のアバターをAI技術によって作成しているのですが、より可愛いアバターをユーザに提供するために、手軽にデザイナーAIを開発可能なツールを探していました。
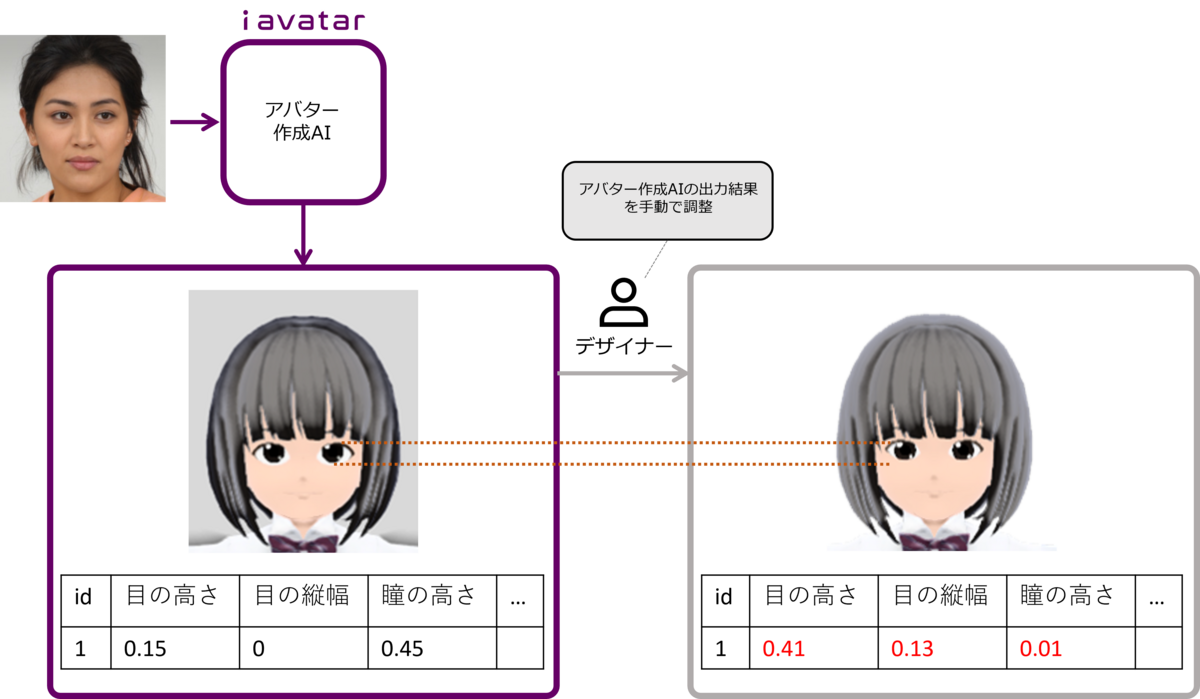
ある女性のアバターを作成する場合を例に、フローを説明します(図1)。アバター作成AIが出力した各パラメータのデフォルト値を、デザイナーはアバターの変化を確認しながら手動で赤字のように調整しています。調整するパラメータは肌の色や顔のパーツの形・位置で、例えば"口"だけでも高さや幅、角度など8つの項目があります。図1の例では、(少しわかりずらいですが)目の位置が元のデータよりも高く、黒目は大きく、また輪郭はシャープになるような修正が行われています。このような調整パラメータは200以上あり、一つのアバターに対して40分程度かけて調整を行っているとのこと。デザイナーの”可愛い”という感性を自動で適用できるようになると、大きなコストメリットがありそうです。
Fujitsu AutoMLで課題をどう解くか
勿論、アバターを作成するAI自体の学習を調整する解決方法もありますが、今回は「デザイナーの調整手法を学習したAIモデルを作る」方法で取り組むことにしました。
Fujitsu AutoMLは、テーブルデータと目的変数をユーザーが指定すると目的変数を推測するAIモデルを自動生成する、AutoMLツールです。このFujitsu AutoMLを使って、図2に示すようにアバター作成AIが出力したデフォルトの値を説明変数、デザイナーが調整した値を目的変数として、回帰問題として解くことにしました。
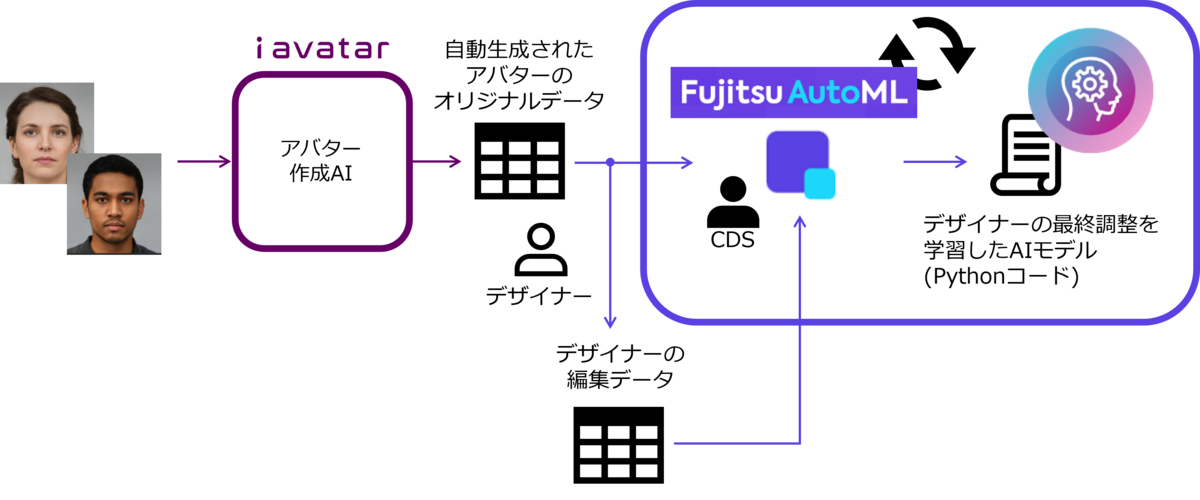
ところで、図2の中にCDSという文字があるのにお気づきでしょうか。CDSとは、市民データサイエンティスト(Citizen Data Scientist)の略で、データサイエンティスト(DS: Data Scientist)ではないが業務に関する深い知識を有しており、明確な課題意識に基づいて業務に関するデータを解析し課題解決を行おうとする人のことを指します*2。
DSが不足している中で、CDSは現場の担当者が担うことができる役割である、という点で潜在的な人口は多いと考えられています。
Fujitsu AutoMLはDSだけでなくCDSが自律的に使えるツールとして研究開発しています。今回の取り組みでは、Pocket RD様の現場の担当者にCDSとなっていただき、Fujitsu AutoMLを使って自分の業務の課題を解決するAIモデルを作ってもらうことにしました。
CDSによるFujitsu AutoMLを使ったAIモデル作成
まずは200種類以上ある特徴量の傾向をつかむべく、EDA(Exploratory Data Analysis: 探索的データ解析)を実施しました。
Fujitsu AutoMLでは実行可能なjupyter環境とnotebookを提供しており、そこで基本的なEDAを確認したり、自分で追加したりすることができます。ですので、データさえ準備できれば即座にEDAを行うことができます。
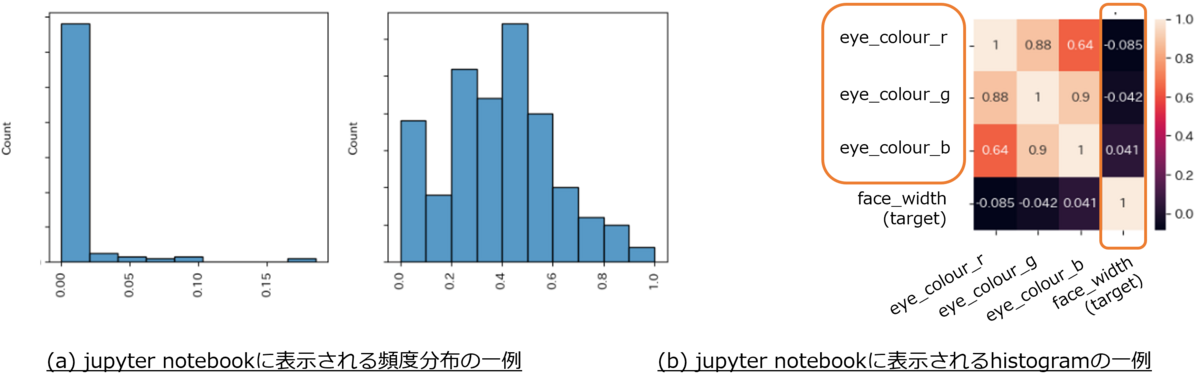
今回、CDSの役割を担っていただいた現場の担当者の方は、アバター作成AIが出力するデータの意味を知っていますが、最終調整をするという業務を自分では行ってはいません。データを一旦全て可視化し、その概要を知る作業はこういった場合でもとても重要だと思います。実は、EDAを行っていくなかで、ほとんど調整していないパラメータがあったり(図3(a))、他の特徴量と相関が小さく、業務知識からも削除してよさそうなパラメータがあったり(図3(b))などの発見がありました。また、EDAだけでなく、Permutation Importance(PI)を取り組みの初期段階に確認することで、データの不備がないかの確認や仮説検討を行うのも大事なポイントです。このようなデータの解析や業務知識を基にした仮説検証を経たのち、200以上あったパラメータを30程度に絞り込むことができました。
次に、タスク設定を改めて考えます。 Pocket RD様からは「一つのモデルで複数の目的変数を予測したい」という希望がありました。そこで、まずは編集データが豊富にあり、かつ相関係数の高い特徴量を持つ顔のパーツ毎(目や輪郭)に絞ってモデルを作成し、単一の目的変数で性能の良いモデルを作れることを確認してから、複数の目的変数を一度に予測するモデルを作成することにしました。
このように、入力するデータのカラムを削除したり(もしくは追加したり)、目的変数を変えたりするような初期のタスク設定を検討する際に、機械学習の知識がDSほどないCDSであっても気軽に素早く試行錯誤を行うことができるのが、Fujitsu AutoMLの特徴です。 (Fujitsu AutoMLがなぜ早いかは過去記事 「ICSE2022でコード生成型AutoML - SapientMLについて発表しました」をご覧ください。)
目的変数を、顔の輪郭、口、目のパーツに関連する13個のカラムに設定して一つのAIモデルを作ったところ、Fujitsu AutoMLは図4のようなMLモデルを候補として返してきました。FujitsuAutoMLではデータのメタ的な特徴量から適切なMLモデルを3つ推薦し、その中でもっとも性能の良いものを最終的なMLパイプラインに組み込んでコードを出力します。今回の取り組みはデータ数が少なく、その少ないデータに過剰に適合してしまう過学習が起きてしまわないか、注意が必要でした。ここで図4のMLモデル候補を確認すると、候補の一つ目はDecisiontreeという表現力の抑えられたモデルが推薦されています。また、他の二つの推薦モデルはExtratree, RandomForestというbagging系のモデルであり、モデルが複雑になりすぎるのを抑える方向のアルゴリズムのMLモデルが推薦されていました。これらの推薦結果は”データ件数が少ない”という特徴から、Fujitsu AutoMLが過剰に適合しないモデルを選択してくれたと考えられます。
現状ツールの範囲外ですが、データの不足によって学習が十分に行われていないかどうかの確認は学習曲線を描いて別途行っています。この辺りの機能も今後充実させていきたいところです。

作成したAIモデルの推測結果
作成したAIモデルを、予め分割しておいたテストデータで評価したところ、r2スコア(決定係数。1に近いほど推測性能が良いことを示し、0はAIモデルが正解値の平均を予測した場合を示す。)では13の目的変数に対して平均0.3という値でした。これは、目的変数に加えるべきではない、ほぼ編集されていない特徴量を見落としていたため、平均値が低くなっていたのでした。この特徴量を除けば平均0.5程度と、r2スコアとしてはまずまずといえる値です。
定性的な評価を行うために、AIモデルの推測結果をアバターに適用した結果を図5に示します。図5(a)より、デザイナーの手動調整と同様に、目の高さや黒目の大きさ、輪郭のシャープさが修正されたアバターができていることがわかります。図5(b)では、黒目を大きくかつ口の高さを低めにという調整の方向性は同じですが、デザイナーの調整よりも大きく変化しているようにみえます。元の写真は初老の男性ですが、学習データにこのタイプの修正データが少なかったことが原因の一つと考えています。デザイナーの修正実績が増えて学習に使えるデータが増えれば、安定した出力を目指せるのではないでしょうか。

今回の取り組みの注目ポイント
今回の取り組みで最も強調したい点は、ドメイン知識を持った現場担当者がCDSとなり、自分でAIモデルを作ることができたことです。Fujitsu AutoMLのユースケースとして提案している、現場の担当者がデータ収集からAIモデルの構築まで行う初の事例となりました。 作業時間はチュートリアル1時間を3回行った後、CDSのみの作業時間が約5時間 であり、非常に短時間で現場の課題を解決するAIモデルを作成することができました。
想定される運用
今回の取り組みから、考えられるFujitsu AutoMLを組み込んだ運用案を図6に示します。 今回はデザイナーの編集データを使って学習しましたが、対象をユーザーに広げて、ユーザーの編集データを蓄積しそこからAIモデルを作る、といったことも考えられます。ユーザーのメタ情報(所属や好みなど)も特徴量として使えると、さらにAIモデルの性能をあげることができるかもしれません。
※ あくまで運用案であり、Pocket RD様がこの運用を行うとは限りません ※
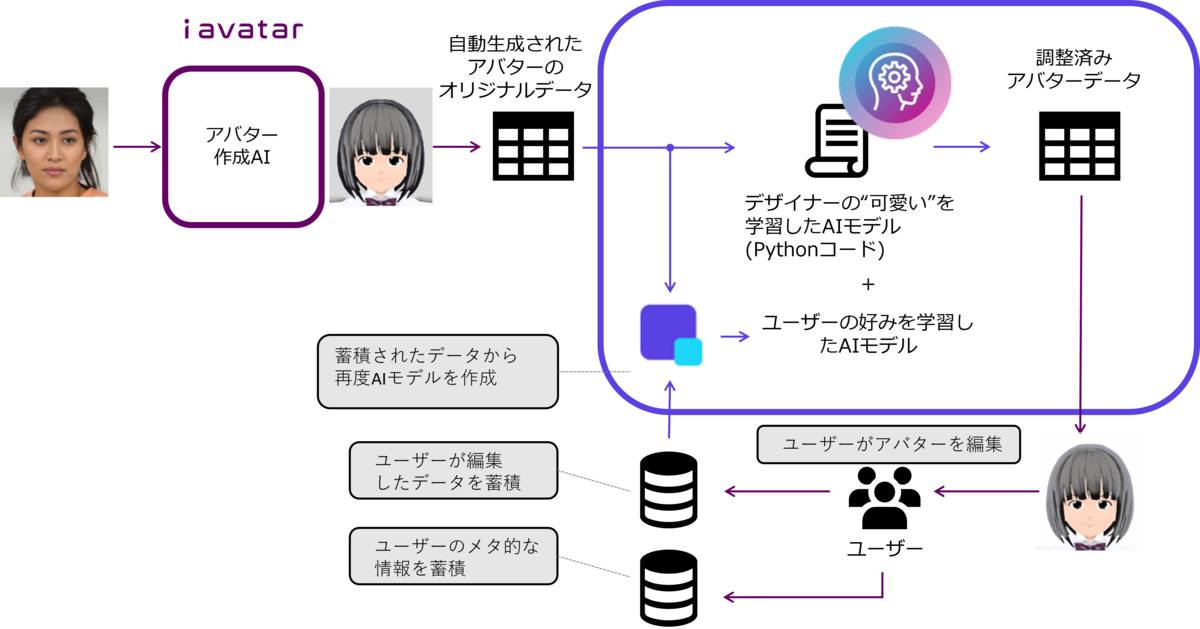
また、今回の実証実験では一人のデザイナーの”可愛い”を学習したAIモデルでしたが、他のデザイナーの"可愛い"を学習させて別のAIモデルを作るということも考えられます。デザイナー毎の感性を、デザイナーテンプレートとしてユーザーに提供できるかもしれません。
考察
今回の実証実験はデータを作成するところからスタートしたのですが、期間中に作成できたデータ数が非常に少なく、タスクとして機械学習には適さないという結論になることも視野に入れつつ、取り組みを行いました。Fujitsu AutoMLの想定ユーザーはCDSも含まれるため、手持ちのスモールデータで取り組みを始める今回のようなケースは今後もあり得ると考えており、その際に、ツールとしてデータが少なすぎることをどう判断してユーザーに伝えるか、検討していきたいと思います。(例えば、学習が十全に行われているかについては単純に学習曲線を表示することが一助になりうる。もしくは、交差検証を行って各分割の評価値のばらつきがある一定以上でアラームをあげる、など。)
サマリ
- アバター作成のデータセットを使って、現場の担当者自らが市民データサイエンティストとなり、Fujitsu AutoMLを使ったデータ分析及びAIモデルの作成を行うことができた。
- デザイナーの感性を学習したAIモデルによって、自動で”可愛い”アバターを作成できるようになった。
ここまで読んでいただき、ありがとうございました。
今後もPocket RD様とは現場の課題を解決するAIというところで協業していきたいと思っています。
謝辞
Pocket RD様にはデータ準備からCDSの役割を担うところまでご対応いただき、当検証を進めることができました。また、当ブログの執筆に当たってもご助力いただきました。 ご協力いただき、誠にありがとうございました!