
こんにちは.人工知能研究所 自律学習PJの竹森です.富士通研究所では「自律的に学習可能なAI技術」に関する研究開発を行っています.このたび,インド理科大学院との共同研究で得られた「最適化が困難な指標のためのコスト考慮型自己訓練学習」に関する研究論文が,機械学習の主要な国際会議であるNeurIPS2022に採択されたので,その内容を紹介します.
対象論文

- タイトル: Cost-Sensitive Self-Training for Optimizing Non-Decomposable Metrics (Harsh Rangwani, Shrinivas Ramasubramanian, Sho Takemori, Kato Takashi, Yuhei Umeda, Venkatesh Babu Radhakrishnan)
- 発表会議:Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS 2022)
- 論文へのリンク
採択された論文の内容
概要
既存研究や応用事例により,画像認識や自然言語のための機械学習モデルは十分な学習データがある場合に高い精度を持つことが知られています.しかし,最適化の対象となる指標が複雑な場合や(ラベル付きの)学習データが十分にない場合は,既存手法では十分な性能を得ることはできません.
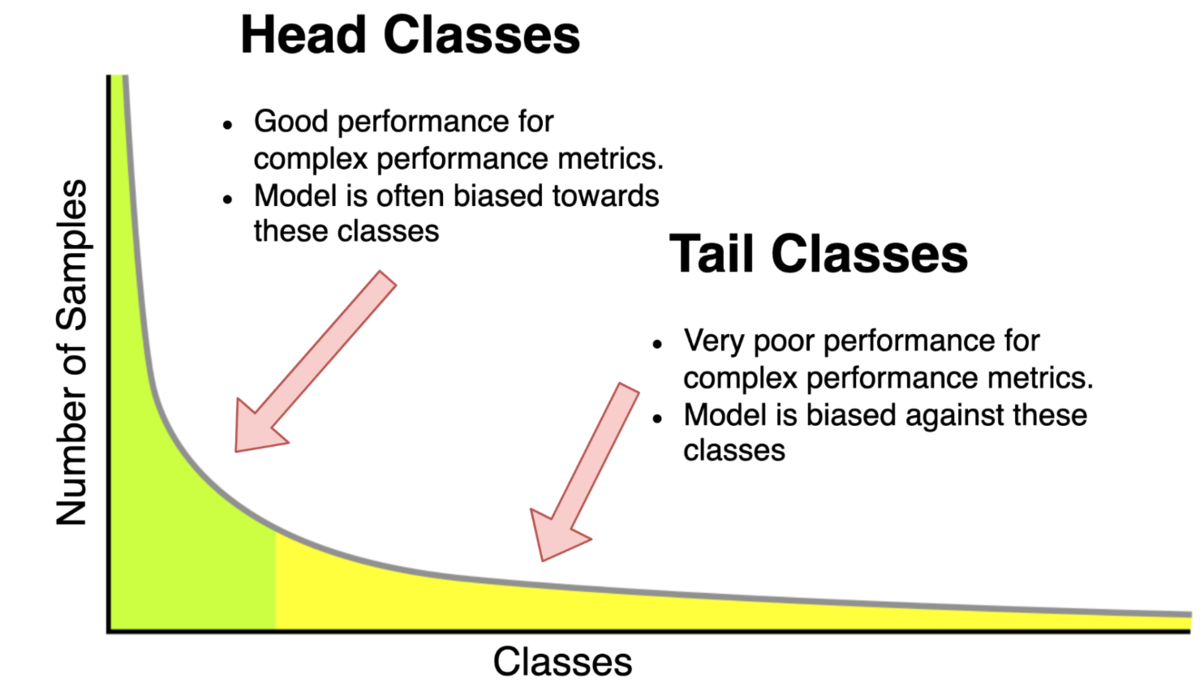
この論文では分類問題に注目していますが,複雑な指標の例として制約付きの指標が挙げられます.例えば,医療診断のためのAIは潜在的な疾病をなるべく捕捉するためrecallが95%以上という制約下において精度などの最適化を行う必要があります. 各クラスラベルを持つデータ数がほぼ同じで十分なデータがある場合には,混同行列をほぼ単位行列にでき,通常の学習により多くの指標を同時に最適化できますが,クラス不均衡な場合(図1)は与えられた指標の最適化を行うことはできません. 最適化の困難な指標の他の例としては,クラス不均衡なデータのための指標があります.クラス不均衡なデータセットでは予測がサンプルの多いクラス(head class)に偏るので,tail classではrecallが低くなります. そのためクラス不均衡なデータセットのために,クラスごとのrecallの最小値(最悪時のrecall)を最大化することが考えられます. 他にも, F_βなどが複雑な指標の例として挙げられますが,これらの指標も(コスト考慮型学習に帰着することにより)本論文で提案している手法により最適化可能です(c.f., [Eban et al 2017]).
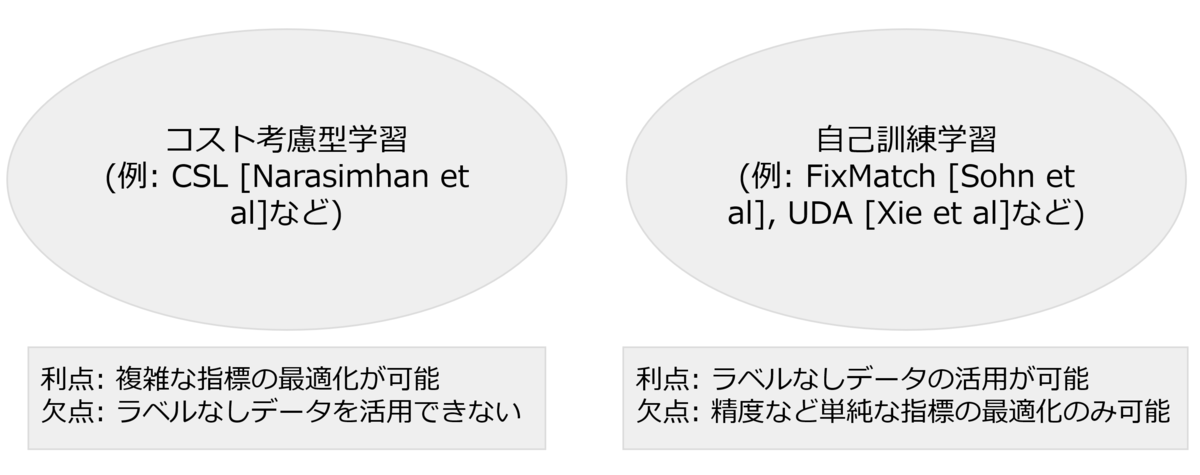
いくつかの既存研究は、教師あり学習の設定で複雑な指標の最適化のための手法を提案しています. 例えば、[Narasimhan et al, 2021]などで考えれらているコスト考慮型学習(cost-sensitive learning)では 多くの複雑な指標の最適化を行うことができますが, 高い性能を得るためには十分なラベルありデータを必要とし,ラベルなしのデータの活用を行うことができません. 一方で,FixMatch[Sohn et al 2020]やUDA[Xei et al 2020]など自己訓練学習(self-training)の手法はラベルありのデータが少数であっても ラベルなしデータを活用することにより高い精度を達成することができますが,複雑な指標を扱うことができません(図2). 私たちの論文では,ラベルなしデータを活用できるよう半教師あり学習の設定で複雑な指標の最適化を考えます.
主結果
本論文では,コスト考慮型自己訓練学習という手法を提案し,2種類の既存手法の利点をもつ新規手法を提案しました.
より詳しく述べると,混同行列の各成分に対してコストを定義しコストを考慮した自己訓練学習のための損失関数を提案しました.
学習中にコストが動的に変わるので,複雑な指標の最適化のための動的な損失関数を考えています.
理論的にはコスト考慮型の一貫性正則化(consistency regularizer)を導入した半教師あり学習のための損失関数を定義し,
それがこの問題設定にとって妥当であること証明しました.
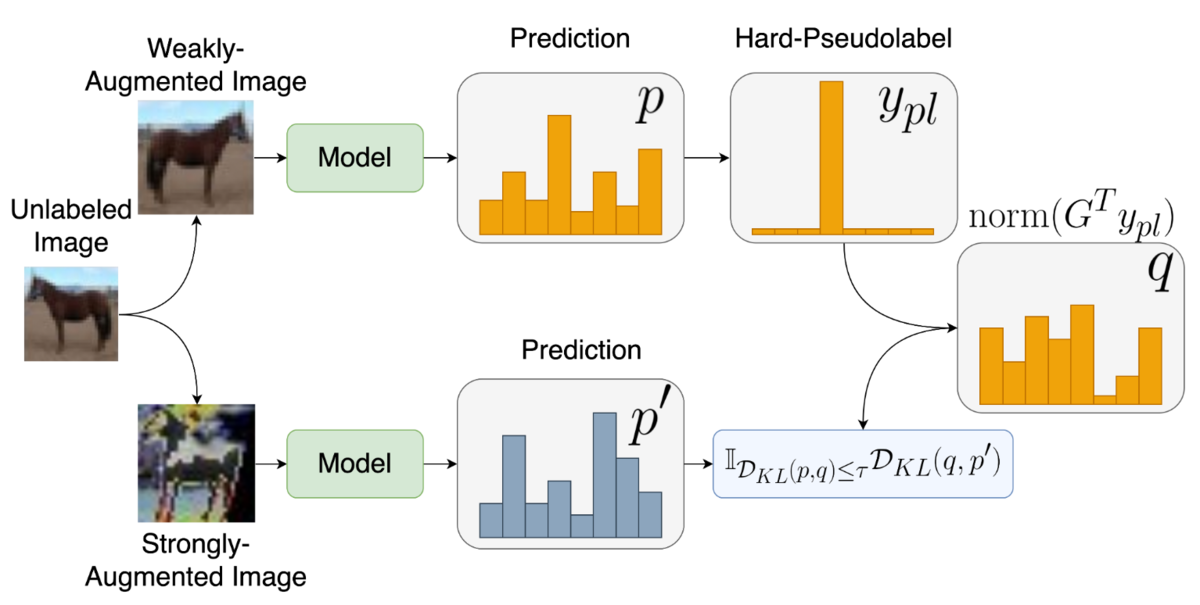
より実用的な損失関数と信頼できる疑似ラベルだけを使うための新規フィルタリング手法を用いて
画像認識や自然言語における複数のタスクで複雑な指標の最適化を行うことができることを示しました(図3は最悪時のrecallに関する実験結果).

最適化が困難な指標とコスト考慮型学習への帰着
まず[Narasimhan et al, 2021]に従って,最悪時のrecallのような複雑な指標をコスト考慮型学習にどう帰着するかについて説明します.
そのために以下の記号を紹介します.Kをクラス数とし,Fを分類器とします.またこの節では使いませんがF_plでpseudo labeler,つまり半教師あり学習の設定で疑似ラベル(pseudo label)を生成する分類器とします.
Cで分類器の混同行列を表し,πでクラスラベルの分布を表すK次元のベクトルとします.

最悪時のrecallは以下のようにクラスごとに定義されるrecallの最小値として定義されますが, 定義から混同行列の成分を用いて表すことができます(以下の2つ目の式). さらにλというクラスごとの重みを表すベクトルを導入することにより, 混同行列の成分に対して線形な関数値のベクトルλに関する最小化ととらえることができます.
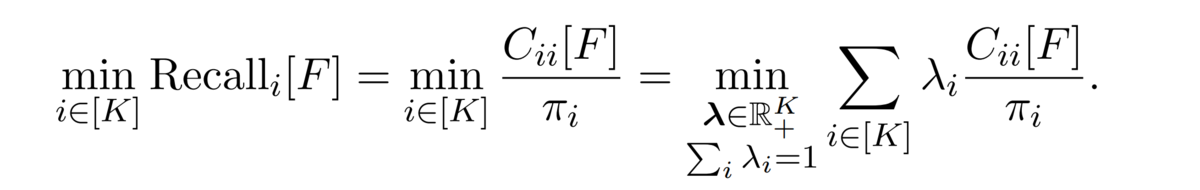
この指標を分類器Fに関して最大化したいので,鞍点を求める問題になっていますが,
実用上はλについての最小化とFについての最大化を交互に行うことによりこれを達成します.
この際,固定されたλに対して上式の最右辺の和を分類器Fに対して最大化しますが,この論文では利得行列(gain matrix)という行列Gを用いて,より一般に以下のような混同行列の成分の線形結合で表すことのできる量の最適化を考えます.最悪時のrecallだけでなく多くの制約つきの最適化指標,また上で述べたようにF_betaなどの指標もこのような量の最適化に帰着できることが知られています([Eban et al 2017]).
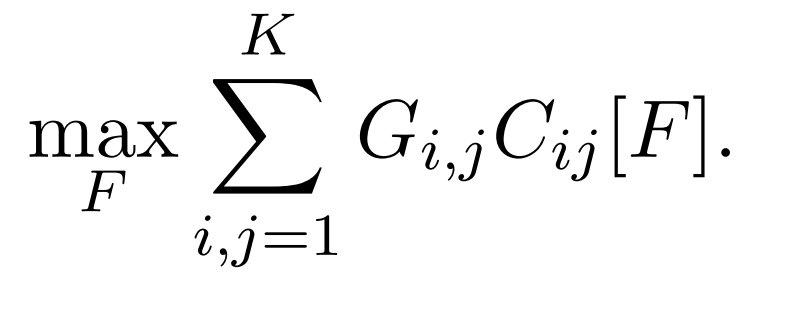
このようなコスト考慮型学習における最適化を教師あり学習の設定で行うために,[Narasimhan et al, 2021]では,logit-adjusted(LA)クロス・エントロピー損失関数や LA損失関数と重み付き損失関数のhybridであるhybrid損失関数が提案されています.
理論的な損失関数とその妥当性
前節では,教師あり学習の設定で複雑な指標の最適化を考えましたが,この節では半教師あり学習の設定で複雑な指標のための損失関数を考えます.
この節では,疑似ラベルを生成する pseudo labeler F_plが与えられているとし,pseudo labeler とラベルなしデータ,ラベルありデータを用いて分類器の学習を行いたいとします.また理論的な結果のために,利得行列ではなく重さを表す行列wを導入します.wに関する重み付き誤差を以下で定義します.
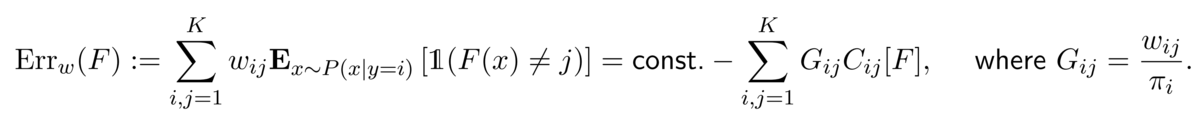
上式からわかる通り,重み付き誤差の最小化と利得行列により定義されたコスト考慮型学習の目的の最大化とは同値になっています.
そして,分類器Fに対して以下のような損失関数を考えます.
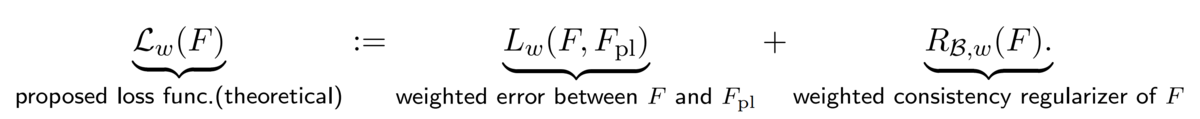
ここで,右辺の第1項は分類器Fとpseudo labelerとの重みつき誤差を表していて以下で定義されます.
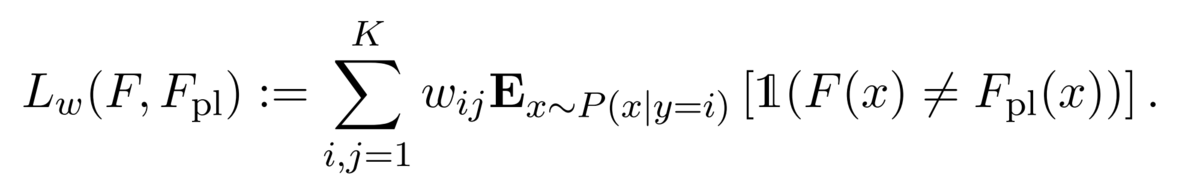
Fがデータオーギュメンテーションやノイズに対してロバストなときに小さくなるものです.重み付きの一貫性正則化項はさらに行列wのi行目の成分が他より大きければP(x | y = i)からサンプルされたものに対してより強いロバスト性を要求します.
定義にP(x | y = i)という分布が現れますが実際の手法では信頼できる疑似ラベルだけに注目することにより,ラベルなしでも重み付き一貫性正則化項の対応物を計算できるようにします.
この提案された損失関数が妥当であるということを示す以下の結果を紹介します.ただしここでは簡単のため厳密な主張は省略します.
定理(厳密でない主張)
psuedo labelerF_plが重み付き誤差Err_wに関して妥当な性能を持つとし,分布の族{P(x | y=i)}_iに関する重み付き分布がexpansion property という自然な性質を満たすとします.さらに重み付き誤差Err_wに関する最適な分類器はデータオーギュメンテーションに関して十分ロバストであるとします.
また提案された損失関数で学習された分類器を以下で定義します.
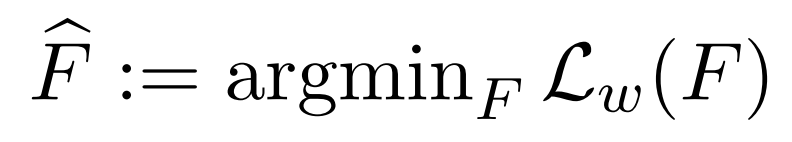
このとき,学習された分類器(Fハット)は以下の不等式を満たします.

右辺の第2項を無視すると,この不等式は,学習された分類器が重み付き誤差の意味でpseudo labelerより良い性能をもつことを示しています. つまり重み付き一貫性正則化項を適切に定義すると,疑似ラベルを用いた半教師ありの学習により疑似ラベルを生成した分類器より,重み付き誤差の点で良い性能を持つことを示しています.
この定理はaccuracyについて同様の結果を示した[Wei et al 2021]の一般化になっています.[Wei et al 2021]では分布の族{P(x | y = i)}_iの台がそれぞれdisjointであると仮定していますが,クラス不均衡なデータセットで(コスト考慮型学習に帰着できる)複雑な指標を最適化する場合にはこの仮定は不適当であるので,我々の結果はより一般的な設定を考えています.
コスト考慮型自己訓練学習のための実用的な損失関数
前節では理論的な損失関数を定義しその妥当性を示しましたが,実験ではより実用的な損失関数を考えます.既存の自己訓練学習(例: FixMatch[Sohn et al 2020])のように,教師あり学習の損失関数と教師なし学習の損失関数との和で定義します.ここで教師あり学習の損失関数は目的に応じて[Narasimhan et al, 2021]で提案されているコスト考慮型学習の損失関数を用います.


l_u^wtは以下で定義される疑似ラベルを用いた重み付き損失関数です.
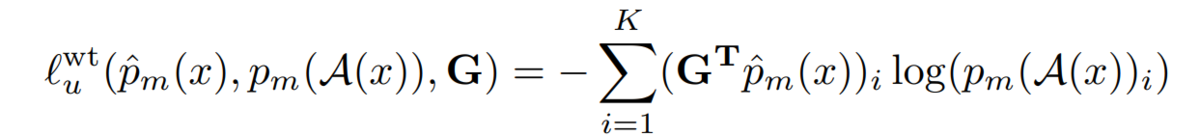
実験結果
CIFAR10-LTという図5のようなCIFAR10をクラス不均衡にしたデータセットでの実験結果を紹介します(自然言語のデータセットでも同様の実験結果を得たのですがここでは省略します).

実験では最適化が難しい指標として,最悪時のrecallとカバレッジ制約とよばれる制約付きの指標を扱いました(ここで各クラスに対して,カバレッジとはそのクラスであると分類器が判断した割合を指します).
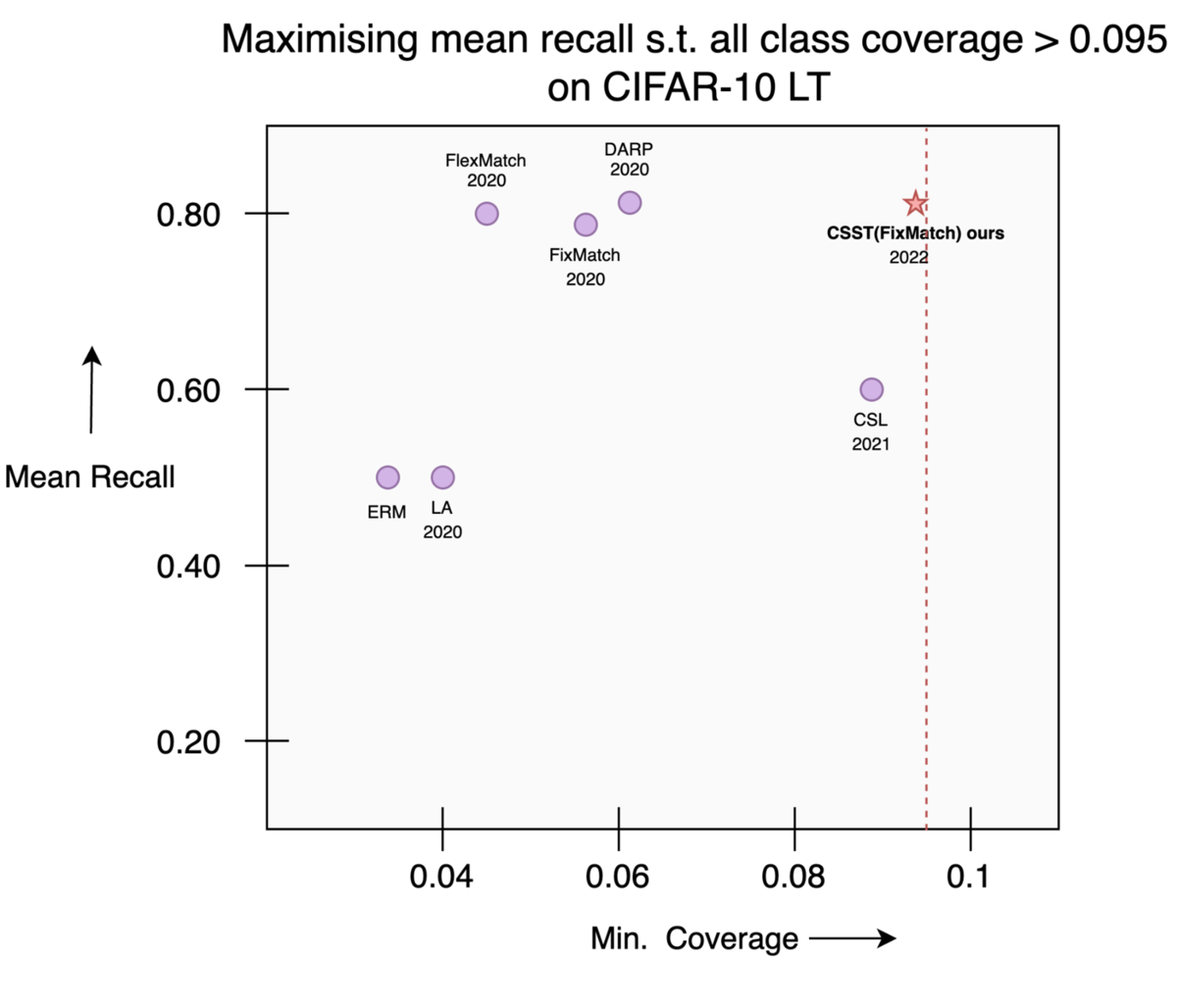
以下の図6は最悪時のrecallについての結果を表していて,図7はカバレッジ制約についての結果を表しています.
図6に関して,縦軸が最悪時のrecallを表していて,横軸がクラスごとのrecallの平均(平均recall)を表しています.
グラフよりERM, CSL[Narasimhan et al 2021], LA[Menon et al 2020]などラベルなしデータを活用できない教師あり学習の手法は性能が低いこと,
FixMatch[Sohn et al 2020], FlexMatch[Zhang et al 2021]などの自己訓練学習の手法は平均recallの点では性能が良いが最悪時のrecallの点では性能が低いこと,
提案手法は目的としている最悪時のrecallに関してDARP[Kim et al 2020]などのクラス不均衡なデータセットのための自己訓練学習の手法より優っていることが分かります.
また図7をみると,これらの既存の自己訓練学習の手法は制約付きの最適化において制約をうまく扱うことができないことが分かります.

参考文献
- Elad Eban, et al. Scalable learning of non-decomposable objectives, Artificial intelligence and statistics. PMLR, 2017
- Jaehyung Kim, Youngbum Hur, Sejun Park, Eunho Yang, Sung Ju Hwang, and Jinwoo Shin, Distribution aligning refinery of pseudo-label for imbalanced semi-supervised learning, Advances in Neural Information Processing Systems, 33, 2020
- Aditya Krishna Menon, Sadeep Jayasumana, Ankit Singh Rawat, Himanshu Jain, Andreas Veit, and Sanjiv Kumar. Long-tail learning via logit adjustment. In International Conference on Learning Representations, 2020
- Harikrishna Narasimhan and Aditya K Menon. Training over-parameterized models with non-decomposable objectives. Advances in Neural Information Processing Systems, 34, 2021
- Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Advances in Neural Information Processing Systems, 33 2020
- Colin Wei, Kendrick Shen, Yining Chen, and Tengyu Ma. Theoretical analysis of self-training with deep networks on unlabeled data. In International Conference on Learning Representation, 2021
- Bowen Zhang, Yidong Wang, Wenxin Hou, Hao Wu, Jindong Wang, Manabu Okumura, Takahiro Shinozaki, FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling, Advances in Neural Information Processing Systems, 34, 2021
- Qizhe Xie, Zihang Dai, Eduard Hovy, Thang Luong, and Quoc Le. Unsupervised data augmentation for consistency training. Advances in Neural Information Processing Systems, 33: 6256–6268, 2020
終わりに
富士通研究所では一緒に働ける方やインターンシップを随時募集しています.もし興味を持たれた方がいらっしゃいましたら,自律学習PJの小橋がカジュアル面談を行いますので,是非ご連絡ください.