
こんにちは、人工知能研究所AI品質プロジェクトの金月です。富士通研究所では、AIの品質向上に向けた研究を行っています。深層学習モデルの精度低下を正解データなしで修復する研究成果が、IEEE ICIP2022にて採択されたのでその概要をご紹介します。
- IEEE International Conference on Image Processing 2022 (ICIP2022)
Multi-Step Test-Time Adaptation with Entropy Minimization and Pseudo-Labeling
Hiroaki Kingetsu; Kenichi Kobayashi; Yoshihiro Okawa; Yasuto Yokota; Katsuhito Nakazawa
モデル修復技術 High Durability Learningについて
富士通研究所では、機械学習モデルの運用時における経年変化や環境変化によって起きる精度低下を自動的に修復する High Durability Learning (HDL)と呼ばれる技術を開発しています。また、High Durability LearningではAI運用時の精度モニタリングや、精度低下の原因を特定することができるダッシュボードを提供することで、モデルの品質を維持することを支援します。これら精度低下の修復技術は複数の要素技術によって構成されており、条件・環境・タスクに応じて適切な技術を選択して適用することで、様々な分野・業種での活用できます。
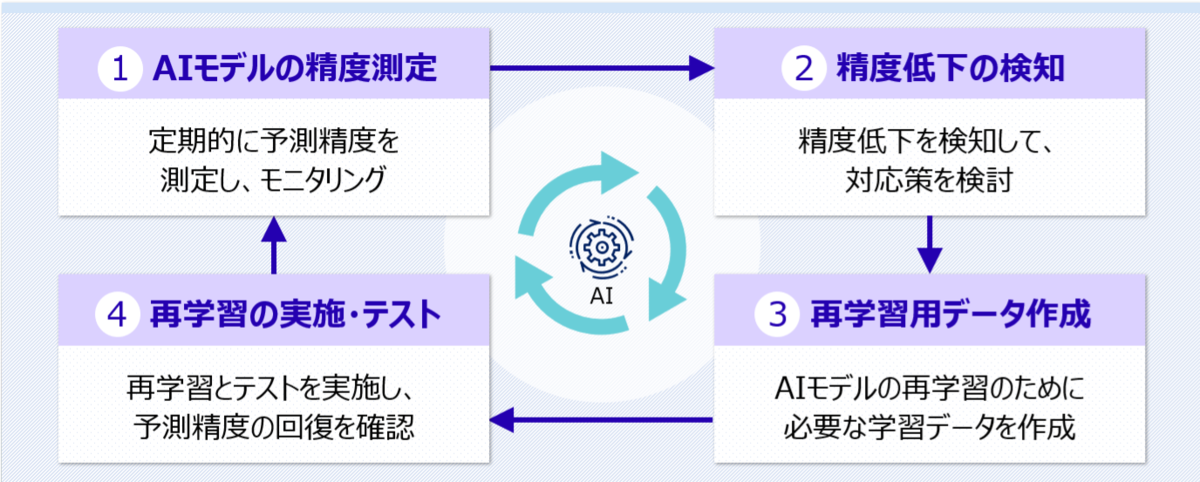

今回採択された論文は、このHigh Durability Learningの中核技術の一つとして、深層学習を用いた画像分類モデルの精度低下を正解データなしで逐次修復する研究成果になります。 このブログでは修復として記述しますが、技術用語としてはドメイン適応(Domain Adaptation)やテスト時適応(Test-time Adaptation)と呼ばれています。
今回の研究の目的
深層学習モデルは、学習データを用いて学習を行うことで、学習データに含まれる特徴を学習し、未知のデータに対してもその特徴を用いて予測を行うことができます。しかし、学習データに含まれる特徴が変化した場合、学習済みのモデルはその変化に対応できなくなり、精度低下を起こします。その原因の一つとして、運用時の画像データに含まれる自然的に生じる摂動、Natural Perturbationがあります。このNatural Perturbationには明度やコントラスト、色調の変化などがあります。 本研究ではこれらのNatural Perturbationに対する運用時の逐次適応を目的とします。 予めNatural Perturbationに対する耐性を強くする(ロバストにする)モデルの構築にはデータ拡張技術などがあります。データ拡張技術はモデルの精度向上のために取り入られますが、このようなNatural Perturbationを予め学習データに含めることで、学習時にそのNatural Perturbationに対応できるようにする手法であるとも考えられます。しかし、データ拡張を行うことで学習データが増える分、学習時間が長くなります。また、すべての起こりうるNatural Perturbationを事前に予想し、対応しつくすことは難しいでしょう。 精度低下を引き起こしてしまうような下図の画像データの場合、通常は人がアノテーションをつけた正解データを含む学習データを再作成する必要があります。しかし、正解データを用意することは高コストであり、また、正解データを用意することができない場合もあります。そこで、本研究では、正解データなしで深層学習モデルの精度低下を修復する方法を提案しています。

周辺技術の紹介(関連研究)
本論文は、画像分類モデルに学習時と分布が異なる画像データが入力された場合に、モデルを入力データに適応させて精度低下を修復する手法となります。適応の条件設定としては、正解データなし・逐次学習(オンライン学習)という条件になっています。逐次入力される正解データがない画像に対して、モデルの重みを適宜変更することで、精度低下したモデルを修復します。また特別なモジュールや別途追加のレイヤーの重みや記憶メモリ等を必要とせず、学習済みモデルのみで完結するため、既存のどの深層学習画像分類CNNモデルに対しても適用可能です。
(関連研究1)半教師あり学習とCatastrophic Forgettingについて
半教師あり学習とは、教師(正解データ)を用いて学習したあとに(あるいは同時に)、大量の正解データがついていない画像データ(ここではテストデータと呼ぶことにします)のみを用いて学習を強化する技術です。この研究は古くからありますが、最もシンプルかつ効果が高い手法として疑似ラベル法[2]が広く知られています。疑似ラベル法は、教師あり学習で学習したモデルを用いて、未知の画像データに対して予測を行い、その予測結果を正解データとして用いて学習を行うことで、未知の画像データに対する予測精度を向上させる手法です。 しかし、半教師あり学習は教師ありの学習データとテストデータの間に分布の相違がある場合にはうまく機能しません。
また逐次学習を行う場合にはCatastrophic Forgetting(破滅的忘却)という問題があります。ある学習済み機械学習モデルに次々と画像を追加すれば、そのモデルの精度が向上すると誤解されることがありますが、実際にはそのように単純には行きません。重みを逐次に変化させていっても、むしろ、モデルの精度が低下することがあります。これこそが新しいタスクを学習すると、モデルが学習した知識を忘れてしまうCatastrophic Forgettingと呼ばれるものです。これは逐次学習を行う場合には必ず問題となるニューラルネットワークの特性です。この問題の解決にはモデルが獲得した知識を忘れないようにする必要がありますが、どのようにすれば解決できるのでしょうか? 最もシンプルにはいままで学習した画像データを保っておき、新しい画像データを学習するときに、いままで学習した画像データも一緒に学習するという方法が考えられます。しかし、この方法は、画像データの量が多くなると、メモリの容量が増大するため、実用的ではありません。また、画像データを保持するために、別途記憶メモリを用意する必要があります。他には、メタ学習といった勾配法の工夫や、特定の層を固定した転移学習などにより解決が試みられています。
(関連研究2)転移学習について
転移学習とはある学習済みモデルを用いて、新しいタスクを学習するときに学習済みモデルの重みを下地に使うことで高精度なモデルを構築する手法です。そのような学習済みモデルの学習データは、一般的な巨大なデータセットか、あるいは類似の別タスクであることが普通です。転移学習には多くの条件や環境によっていろいろな適応がこれまでに考案されており、その方法は多岐に渡ります。たとえば、Few-shot LearningやZero-shot Learningなどがあります。その他、これまでに紹介した半教師あり学習やドメイン適応なども転移学習と深い関わりがあります。学習テクニックの一つである知識蒸留(Knowledge Distillation)はソフトターゲットを(あるときはノイズを加えて)より小さなモデルに転移させる手法とも言えるでしょう。
(関連研究3)テスト時適応について
さて、ここで解きたい問題は運用時にNatural Perturbationが乗ったような状態の画像データへのモデルの適応です。どの知識を用いて学習済みモデルからテストデータへ適応をすればよいでしょうか? またforgettingをせずに新しい画像データに適応するためにはどのように転移すればよいでしょうか? Test-time Entropy Minimization[3]はこの問題に対する先駆けとなる研究です。この研究では、テスト時にモデルの出力に着目し、そのエントロピーを最小化するようにモデルの重みを更新することで、モデルの出力を安定させます。このとき、Batch Normalization層に置けるアフィン変換に関係のある学習可能なパラメータのみを更新し、他の層は固定することで、モデルのforgettingを抑えつつ、既存知識を利用して適応することが可能になっています。
提案手法 Multi-step Layer Adaptation
仕組み
提案手法 Multi-step Layer Adaptation は、この先行研究[2][3]の発展的な位置づけにあたります。Cluster Hypothesisによると同じ分類クラスに属する画像は(元データに比べて)低次元の空間上の同じクラスタに射影することができると考えられています。 この仮説はNatural Perturbationがないクリーンな学習データにも、それにNatural Perturbationが乗ったデータに対しても、同じように成り立つと考えるのは自然でしょう。つまり、直感的にはNatural Perturbationが含まれたデータの射影空間は学習データと同じようにクラスタの形に近くなるべきであり、さらにデータ数が同じであれば学習データと同様な大きさのクラスタになると仮定できます。 提案手法はこの仮定に基づいて正解データなしで計算可能な相互情報量を利用した損失関数を用いて、モデルの修復を試みます。さらに決定境界とこのクラスタ群の距離の調節を後ステップに加えることで、対象となる層の働きを考慮した各々の損失関数で学習される複数の適応ステップにより高精度な画像分類モデルになるよう重みを修正します。疑似ラベル法単体では十分に訓練されたモデルでは効果がないどころか悪化することがありましたが、学習を工夫することでその働きをうまく活かせる結果を得ることができました。

結果
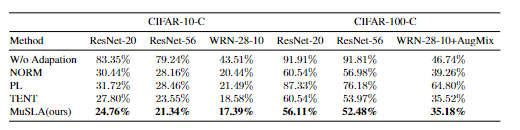
下表の通り、Natural Perturbationが乗った画像データに対して、適応なし(W/o Adaptation)ではエラー率が非常に高くなるのに対し、提案手法(MuSLA)はそれを抑えこむことに成功しました。また、従来手法よりも低いエラー率を達成することができました。
この新しい適応手法は、より現実的な設定を想定した上でさらに頑健なモデルを構築できる工夫を加え、High Durability Learningの修復技術の一つとして提供されます。
関連論文
[1] Hendrycks, Dan, and Thomas Dietterich. "Benchmarking neural network robustness to common corruptions and perturbations." ICLR 2019.
[2] Lee, Dong-Hyun. "Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks." ICML Workshop 2013.
[3] Wang, Dequan, et al. "Tent: Fully test-time adaptation by entropy minimization." ICLR 2021.