 こんにちは人工知能研究所の山根です。今日は、Fujitsu Kozuchiに搭載されているFujitsu AutoML for Visionについてご紹介します。
こんにちは人工知能研究所の山根です。今日は、Fujitsu Kozuchiに搭載されているFujitsu AutoML for Visionについてご紹介します。
このブログは、Fujitsu Kozuchi のAIコアエンジンを紹介する連載ブログのひとつです。ブログの最後で、これまでのブログをまとめておさらいできます!
画像内の物体を認識できるAIを開発するには、大量の学習データの準備、大規模な計算リソース、そしてAIに関する専門的な知識が必要です。この課題を解決するFujitsu AutoML for Visionを紹介します。
Fujitsu AutoML for Visionは、画像内の認識したいものを、利用者が自然言語で指示できるようにすることで、画像AIを簡単に使えるようにする技術です。例えば、利用者は特定の物体の検出や、その数を数えることをAIに指示できます。都市や森林などの場所の認識、天候などシーンの識別も可能です。この時、大量のデータセットや大規模な計算リソースは必要ありません。
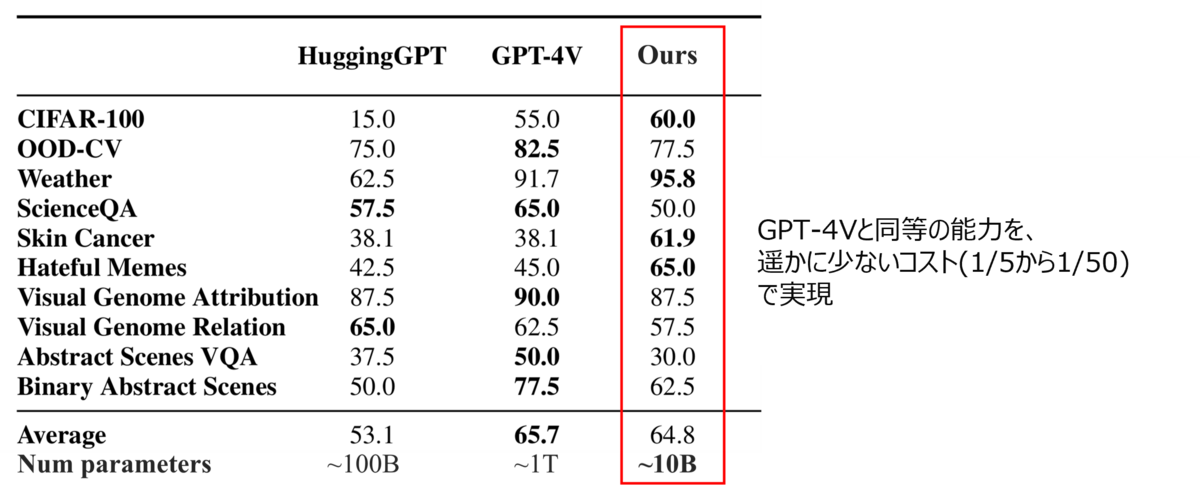
Fujitsu AutoML for Visionは、GPT-4Vと同等の精度かつ大幅に少ないコストで、様々な画像タスクを実行できます。この技術は、富士通が研究開発した先端AI技術を迅速に試すことができるプラットフォームFujitsu Kozuchiの主要なAIコアエンジンの一つです。
Fujitsu AutoML for Visionの価値と利用イメージ
Fujitsu AutoML for Visionを支えているのは、専門家がいなくても、画像タスクを実行できるAIソリューションを、自動的に構築できる技術です。Fujitsu AutoML for Visionをご理解いただけるように、順番に説明します。
まず、利用者は画像AIに何をしてほしいのかを入力します。普通の会話で使うようなシンプルな言葉で、AIへの質問文と、どのような回答が欲しいのかを選択肢で示します。例えば、質問は「この画像にはクジラが何頭いますか?」、回答の選択肢は[0,1,2,多数]というテキストを、画像と共に入力します。

質問に答えるために、Fujitsu AutoML for Visionは、学習済のさまざまな画像AIモデルの中から、最も適した画像AIモデルを選択します。このシステムの要となるのは、LLM Plannerと呼ばれる特別に訓練された大規模言語モデル(LLM)です。このPlannerにより、利用者からの質問に対応するための最適な画像AIモデルを選択することが可能になります。世界中には数多くの学習済の画像AIモデルが存在しますが、モデルの能力がそれぞれ異なるため、最も適切なものを決定することは、とても難しいです。
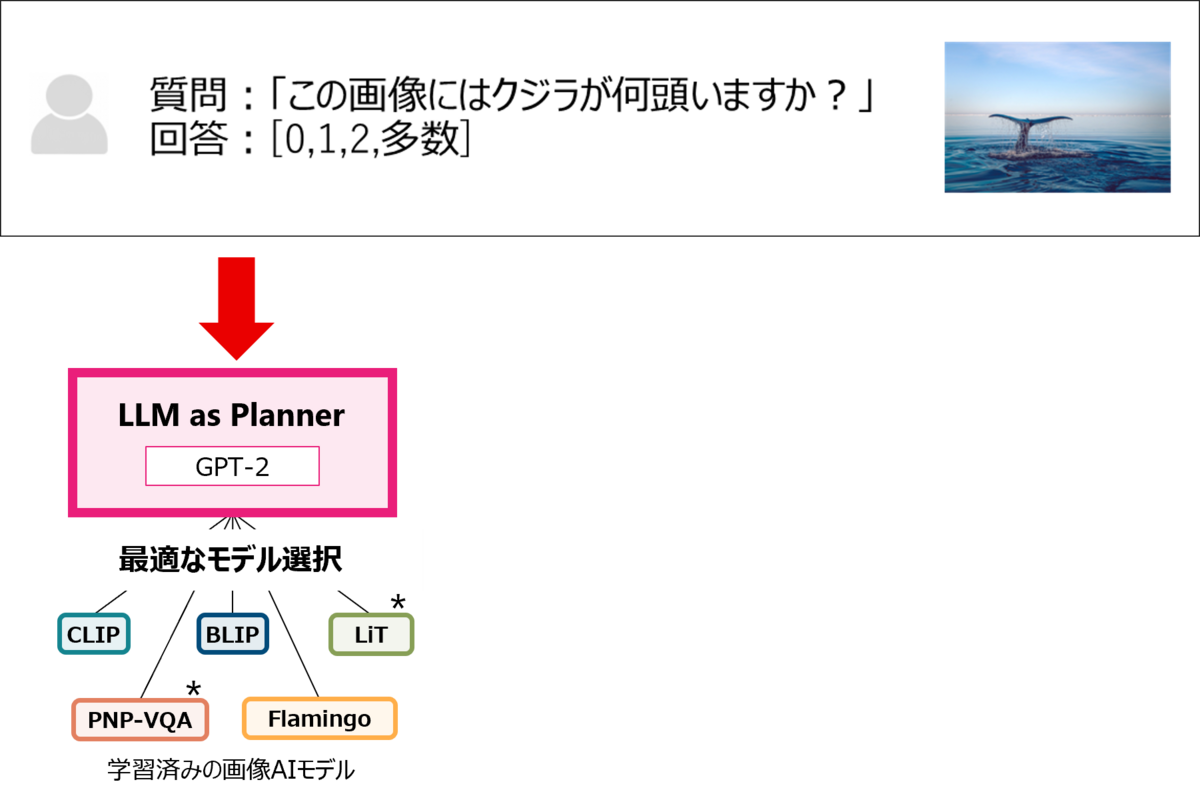
Fujitsu AutoML for Visionは、最も適した画像AIモデルを効率的に選択し、それを用いて質問に対する回答を出力します。利用者は、それぞれのAIモデルの特長や、AIに関する専門知識がなくても、質問と回答の選択肢を入力するだけで、多数のAIモデルを使いこなすことができるようになります。
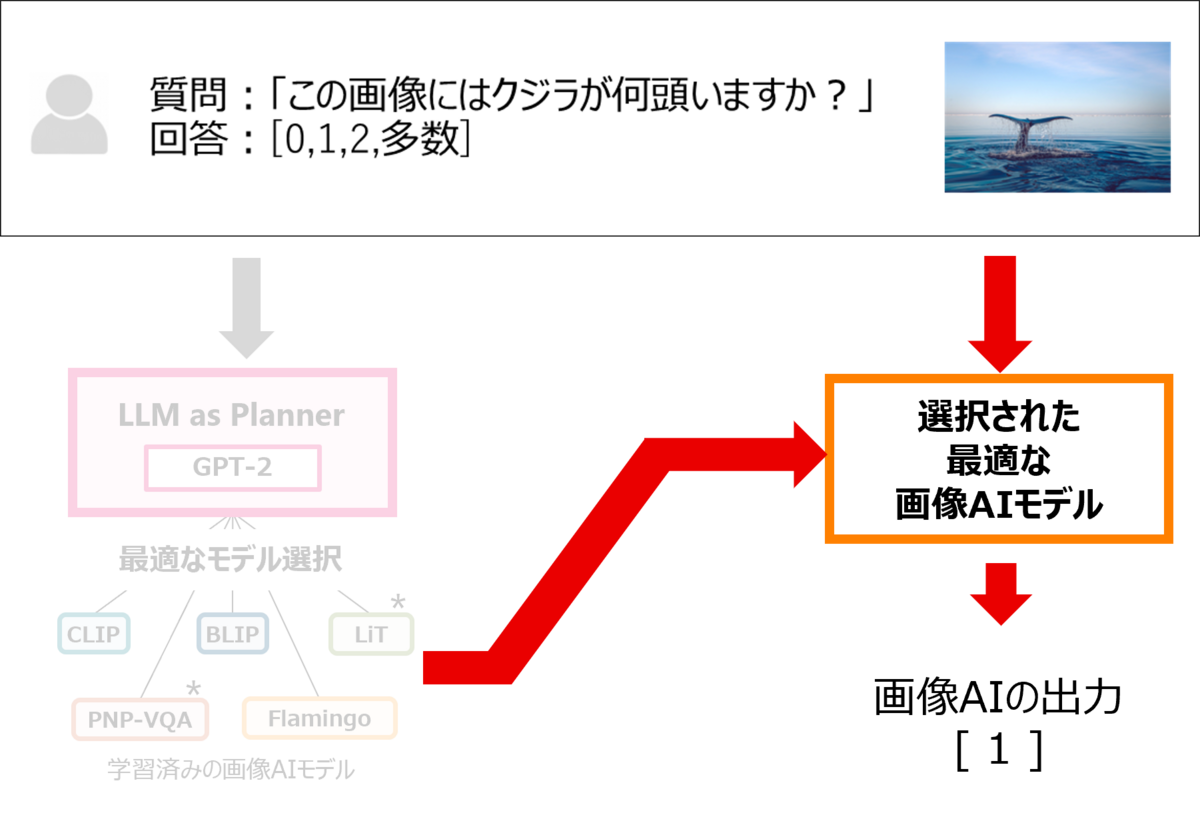
このように、利用者は学習データを必要とせずに、質問に対する回答を得ることができます。その精度は、GPT-4Vに匹敵し、コストはごくわずかです。
さらに、Fujitsu AutoML for Visionは、学習データを用いて認識精度を高めることも可能です。既存の学習済みの画像AIモデルは、多種多様な物体を幅広く認識することができますが、特定の物体(例えば、特定の種類のクジラ)をより高精度に認識したい場合もあるかと思います。そのような場合には、その物体の画像でAIモデルを再学習(ファインチューニング)することが有効です。学習済みモデルは、既に大量なデータを学習しているため、新たに準備するデータは、特定の目的に特化した学習データ(この場合、特定のクジラの画像)のみで、再学習させることができます。 このように、利用者は最小限の学習データを準備すれば、より高精度な画像認識AIを得ることができます。
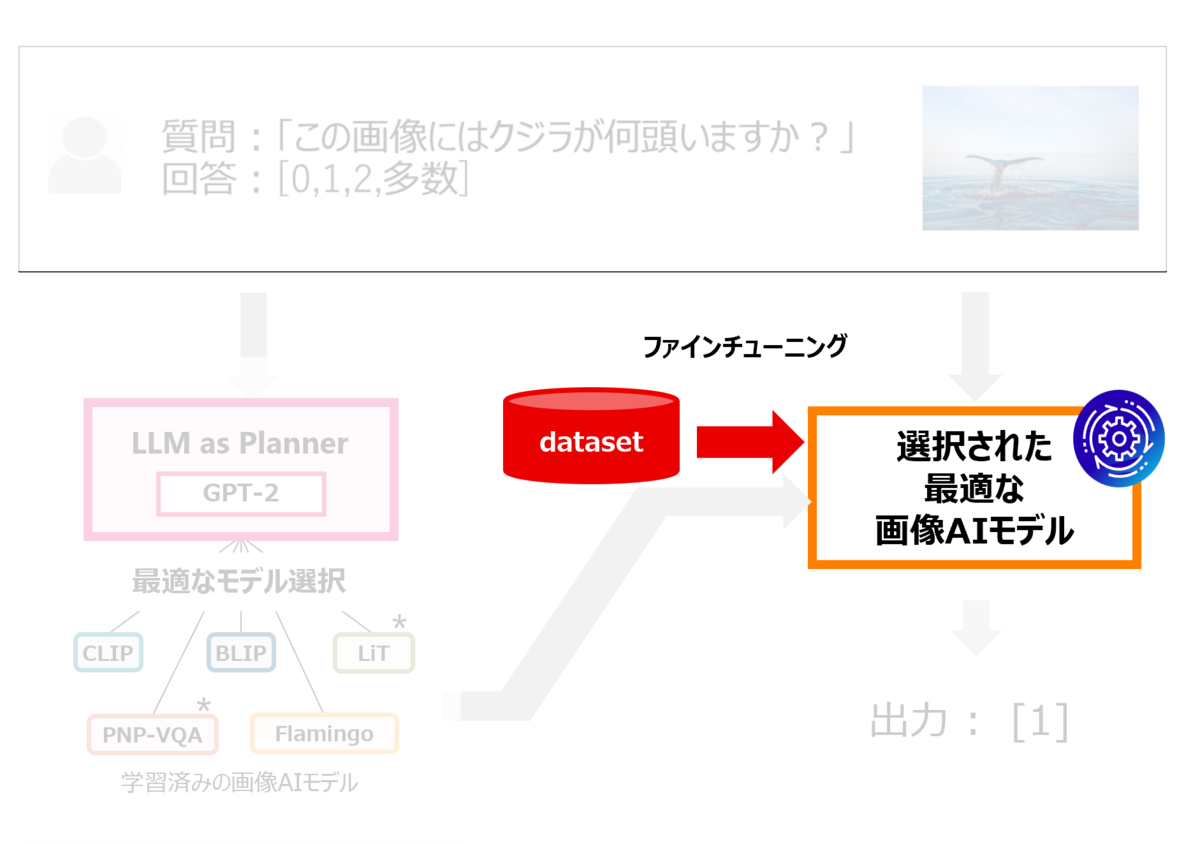
*2024.5時点では、図中★の部分は、デモには含まれません。 *2024.5時点では、Fujitsu AutoML for Vision は、UIは英語のみです。
Fujitsu AutoML for Visionの技術の特長
LLM as Plannerは、競合する他の手法と比較して、最高レベルの識別精度で、高い計算能力とデータ効率が特長です。
Fujitsu Kozuchiで適用検証を始めませんか
このエンジンは、専門知識を必要とせず、低コスト、最小限の学習データと計算資源で、画像AIの活用を容易にします。私達は、この技術を使うことで、新しいアプリケーションの開発を促進することができると考えています。技術は社会をよくする可能性を秘めています、しかし、高いコストのため充分に技術が活用されないということが、しばしば起こります。Fujitsu AutoML for Visionによって、低いコストで、最先端の技術を活用することができるようにすることで、社会にポジティブな影響を生み出す機会が増えると考えています。
Fujitsu AutoML for Visionが実際に活用されている例を紹介します。東京都の八丈島は、海岸からでもホエールウォッチングができることで知られていますが、観光客にとってクジラが現れる時間・場所が分からないという課題があります。そこで海岸沿いに取り付けられたカメラからの映像をFujitsu AutoML for Visionで分析し、クジラが検知された場所・時間をリアルタイムで観光客に発信するシステムの開発を進めています。
Fujitsu AutoML for Visionのご紹介デモやトライアル環境については、以下よりお問い合わせください。
Fujitsu AutoML for Visionの他にも、Fujitsu KozuchiのAIコアエンジンをTechBlogで紹介しています。
・AI画像生成blog.fltech.dev
・Fujitsu Neuro-Symbolic Explainerblog.fltech.dev
・マルチカメラトラッキングblog.fltech.dev
・画角変更検知blog.fltech.dev
・敵対的サンプル攻撃検知blog.fltech.dev
・富士通LLMバイアス診断blog.fltech.dev
・Fujitsu Auto Data Wranglingblog.fltech.dev