 Hello, this is Fan Yang, from the Human-reasoning Project of AI Lab. We are thrilled to announce that our paper, "Is Weakly-supervised Action Segmentation Ready For Human-Robot Interaction? No, Let's Improve It With Action-union Learning," has been selected as a finalist for the "IROS 2023 Best Paper Award on Cognitive Robotics." This prestigious recognition is a testament to our team's relentless pursuit of excellence and innovation in the field of human action recognition. Our paper introduces Action-union Learning, a novel approach designed to improve the readiness of weakly-supervised action segmentation in human sensing, which could significantly reduce the annotation cost and improve the training efficiency in the implementation of Fujitsu Actlyzer and Kozuchi.
Hello, this is Fan Yang, from the Human-reasoning Project of AI Lab. We are thrilled to announce that our paper, "Is Weakly-supervised Action Segmentation Ready For Human-Robot Interaction? No, Let's Improve It With Action-union Learning," has been selected as a finalist for the "IROS 2023 Best Paper Award on Cognitive Robotics." This prestigious recognition is a testament to our team's relentless pursuit of excellence and innovation in the field of human action recognition. Our paper introduces Action-union Learning, a novel approach designed to improve the readiness of weakly-supervised action segmentation in human sensing, which could significantly reduce the annotation cost and improve the training efficiency in the implementation of Fujitsu Actlyzer and Kozuchi.

Paper Information
- Paper Title: Is Weakly-supervised Action Segmentation Ready For Human-Robot Interaction? No, Let's Improve It With Action-union Learning
- Paper Authors: Fan Yang, Shigeyuki Odashima, Shoichi Masui, and Shan Jiang
- Conference: IEEE/RSJ International Conference on Intelligent Robots and Systems 2023
Overview
Action segmentation plays an important role in enabling robots to automatically understand human activities. To train the action recognition model, while obtaining action labels for all frames is costly, annotating timestamp labels for weak supervision is cost-effective. However, existing methods may not fully utilize timestamp labels, which leads to insufficient performance. To alleviate this issue, we proposed a novel learning pattern in our training stage, which maximizes the probability of action union of surrounding timestamps for unlabeled frames. In our inference stage, we provided a new refinement solution to generate better hard-assigned action classes from soft-assigned predictions. Importantly, our methods are model-agnostic and can be applied to existing frameworks. On three commonly used action-segmentation data, our method outperforms previous timestamp-supervision methods and achieves new state-of-the-art performance. Moreover, our method uses less than 1% of fully-supervised labels to obtain comparable or even better results.
Related Work
Training action-segmentation models typically require numerous labels in conventional approaches. In the ideal case, frame-wise labels (i.e., labels at each frame) should be provided for full supervision. However, two challenges exist in the utilization of frame-wise labels: first, annotating action labels in each frame is costly, and second, the temporal boundaries of actions can be ambiguous, and different annotators may provide varying labels, leading to data bias. To alleviate such challenges, recent studies have proposed timestamp annotation and corresponding weakly-supervised training methods. Instead of annotating action labels for every frame, the timestamp annotation only requires one frame for labeling in a temporal action segment that includes multiple frames. This not only reduces the annotation cost but also decreases discrepancies in temporal boundaries because annotators can select high-confidence timestamps for labeling.

To train action-segmentation models with timestamp labels, two popular solutions have been proposed. The first solution employs a handful of timestamp labels for supervised learning, whereas the second one attempts to generate pseudo labels for unlabeled frames and further apply them in model training. These two solutions are not isolated; instead, they are integrated into the typical timestamp training scheme: The first solution is used to initialize the model, allowing it to generate pseudo labels for the second solution, and then both solutions are jointly applied in the following training stage. Recent research has focused on the second solution specifically on how to generate high-quality pseudo labels. Although timestamp supervision is a promising approach in current action-segmentation studies, a performance gap remains between timestamp-supervised and fully-supervised approaches. This prompts us to investigate whether timestamp labels could be utilized more effectively.
Proposed Method
Action-union Learning
Although the action probability of an unlabeled frame is unknown, we can infer the probability of Action Union (AU) for it. For example, consider two successive timestamps that have action labels
and
, each unlabeled frame between them should have the probability of action union as
. Therefore, in the training stage, we propose the third type of learning solution: we generate action-union labels based on the timestamp annotations for all unlabeled frames and maximize the probability of action union. This allows us to form highly reliable learning targets for all unlabeled frames, in contrast to previous works that only depend on unreliable pseudo labels.

Action Inference
In the inference stage, while previous methods only consider label smoothing in the training stage, we suppose that the smoothness of action sequences is important in the prediction stage. We propose a novel refinement method to generate more accurate hard-assigned action labels. More specifically, we partition the prediction into chunks, and then, in each chunk, we jointly maximize the temporal smoothness of hard-assigned labels, as well as the combinatorial likelihood between soft-assigned and hard-assigned labels.

Experimental Results
Our results significantly outperform previous timestamp-supervision studies: 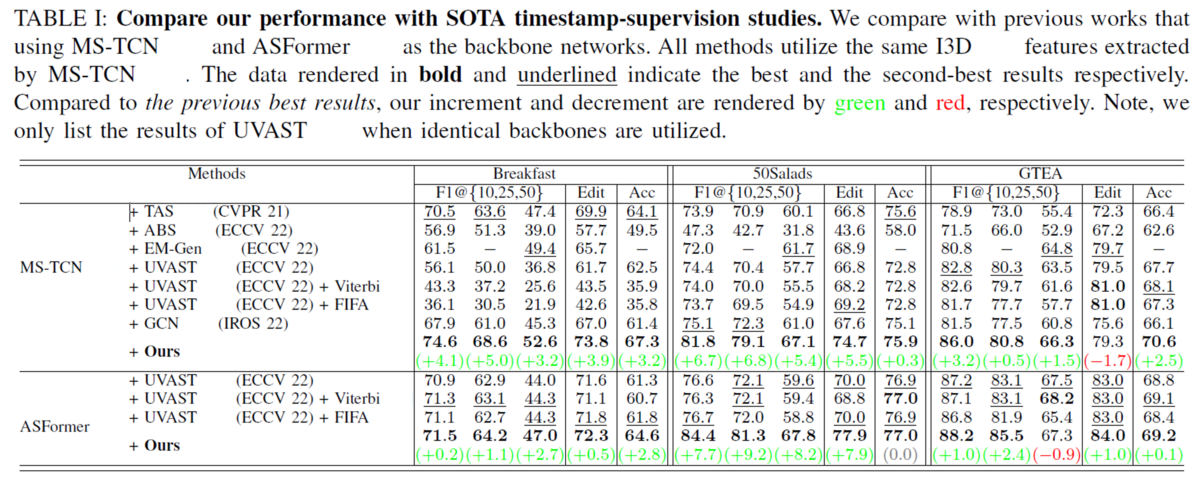
Our results are comparable with fully-supervision studies: 
Visualizing results:
Impacts of This Work
We proposed a new SOTA method for timestamp-supervised action segmentation. In the training stage, we designed a novel action-union learning to enhance representation learning when only using limited timestamp labels. In the inference stage, we presented a new refinement solution to obtain improved hard-assigned action labels. Experimental results on multiple benchmarks demonstrate the effectiveness of our method. Our ablation studies further reveal the details of how our method can improve performance step-by-step. As a model-agnostic solution, we hope that our work has revealed a new direction to train action segmentation with limited labels and inspire future works to discover more effective training patterns.
References
- Ding Guodong, et al. "Leveraging Action Affinity and Continuity for Semi-supervised Temporal Action Segmentation". ECCV 2022.
- Rahaman Rahul et al. "A Generalized and Robust Framework for Timestamp Supervision in Temporal Action Segmentation". ECCV 2022.
- Behrmann Nadine et al. "Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation". ECCV 2022.
- Li Zhe et al. "Temporal action segmentation from timestamp supervision". CVPR 2021.
- Fangqiu Yi et al. "ASFormer: Transformer for Action Segmentation". BMVC 2021.
- Abu Farha et al. "MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation". CVPR 2019.
- Souri Yaser et al. "FIFA: Fast Weakly Supervised Action Segmentation Using Mutual Consistency". GCPR 2019.
- Richard Alexander et al. "NeuralNetwork-Viterbi: A Framework for Weakly Supervised Video Learning". CVPR 2018.
- Lea Colin et al. "Temporal convolutional networks for action segmentation and detection". CVPR 2017.
- Kuehne Hilde et al. "The language of actions: Recovering the syntax and semantics of goal-directed human activities". CVPR 2014
- Stein Sebastian et al. "Combining embedded accelerometers with computer vision for recognizing food preparation activities". UbiComp 2013.
- Fathi Alireza et al. "Learning to recognize objects in egocentric activities". CVPR 2011.