
こんにちは、富士通研究所コンピューティング研究所の萩原です。 文部科学省「次世代計算基盤に係る調査研究」事業の一環として、 2023/7/9~7/13 に Moscone West (San Francisco) で開催された国際会議 Design Automation Conference 60 (https://www.dac.com/) に参加しました。 今回は、DACから見て取れる半導体設計の研究開発動向と、 Stanford大学と富士通研究所の共著で発表した論文について報告します。
半導体チップの多機能化・高機能化の要求から、 3次元積層ダイやチップレットといったマルチダイを採用したアーキテクチャが 多く出てきています。例えば、AMD からは Instinct MI300 が、 Intel からは Meteor Lake が発表されています。 次世代計算基盤でもマルチダイの検討を進めています。マルチダイのアーキテクチャでは、 様々なプロセスで別々に作製したダイを組み合わせて動作させる必要があるため、 設計・検証共に複雑であり、EDA (Electric Design Automation) ツール の活用方法が肝になります。
このような背景を踏まえ、本記事では、DACから見て取れる半導体設計の研究開発動向として、 3つのトピックを紹介します。 まず、設計の複雑化により半導体製造コストが上がっていることから、 半導体の高付加価値化の取り組みというトピックを取り上げます。 次に、複雑化した設計にかかっている人的時間的コストを減らすための手段として、 AIを活用した半導体開発支援というトピックを取り上げます。 最後に、こういった新たな設計手法の研究開発を推し進めるため、 また、より多種多様な人々が設計することで新たな半導体チップを生み出すための環境として重要な、 オープンソースとコミュニティという観点から、 ハードウェアの民主化というトピックを取り上げます。
また、コンピューティング研究所では、3次元積層アーキテクチャにおいて課題となっている 放熱に関してStanford大学と連携して取り組んでいます。 今回のDACではその成果を発表できましたので、この内容についても紹介します。
Design Automation Conference概要
Design Automation Conference (以下DAC) は今年60回目となる EDA 分野のトップカンファレンスです。主に、半導体の設計自動化ツールやそのアルゴリズム、 コンピュータ・アーキテクチャなどに関する話題を扱っています。 今年の参加者数は約4000人、展示会の出展社数は125社でした。 昨年より現地のみ開催に戻りましたが、コロナ前と比較するとまだ参加者・出展者とも少ない状況です。 ただし、論文投稿数については、2020以前から継続的に増加傾向となっています。 今回の投稿数は1156、採択は263でした (採択率22.7%)1。

DACから見て取れる研究開発動向
トランジスタ単価上昇による高付加価値化
上記で述べたように、半導体の開発コストはどんどん増加しており、その割合は年平均55%にもなります。 半導体チップ自身が複雑化していることから検証に時間がかかる上、 高機能化した半導体を使いこなすためのソフトウェアの開発コストも大きくなることも要因です。
トランジスタあたりでみても28nmプロセスまでは製造コストは下がってきましたが、それ以降停滞しています。 特に7nm以降では増加に転じていますので、トランジスタ当たりの付加価値も上げていかねばなりません。
より高付加価値の半導体を作るために、近年ではエンドユーザーと直接つながるApple、Tesla、Amazon.com、Microsoftなどが、 ソリューションなどの様々なサービスを提供しながら、提供するサービスに最適な半導体を作るという形で、半導体開発工程の垂直統合が進んでいます。 2000年ぐらいまではサービスを提供する会社と半導体を設計する会社は別でしたが、 2020年以降はこれらが統合されるようになってきています2。
垂直統合の例として、85万個のコアを搭載したウェハスケールのAIアクセラレータを発表したCerebras社はアーキテクチャの工夫のほか、
- ダイを跨ぐ配線を許容するリソグラフィ技術
- 膨大な数のピンを捌くためのパッケージング技術
- 巨大なチップに電力を供給するための専用PCB基盤技術
- 空冷と水冷を組み合わせた高効率な冷却技術
といったデバイスからシステム筐体に至るまで様々な技術を垂直統合してアクセラレータを構築しています3。
AIを活用した半導体開発支援
ここまで述べてきた通り、半導体の大規模化・複雑化が指数関数的に進んでいますが、 その一方で半導体開発技術者の数は指数関数的には増えません。 北米でも2030年までに2万3千人のエンジニアが不足するだろうと予測されています4 (日本でも半導体開発技術者は不足しています)。 このような人材不足に対応するため、AIによる半導体開発支援が本格化してきています。 本節の最後で紹介するように、DACでも多くのAI関連技術を適用した研究成果の発表がありました。
設計自動化へのAI適用の研究・技術開発は今後も更に進んでいくと考えられますが、課題が2点あります。
1つ目はAIによる設計をどう評価・検証するかという点です。 AIの設計結果を人々が信用するには、AIがどのように(how)、なぜ(why)その設計を導き出したのかを理解する必要があります。 これには説明可能なAIが有用であると考えられます5。 設計自動化へのAI適用における課題の2つ目は、AIへ入力する設計データや技術ノウハウの暗号化です。 過去の設計データや技術ノウハウを暗号化により盗まれないような形にしつつ、 AIとしては国家単位で強力なものを作り上げるため、 暗号化されたデータを直接AIに入力するという仕組みを実現するために国家で進めていく動きが米国で出始めています6。
それでは、DACの発表からAIを活用した半導体開発支援技術の例として5分野を紹介します。
1. アーキテクチャのパラメタ探索
CPUやAIアクセラレータの設計において、性能・電力・コストを最適にする バッファサイズや演算器量などのパラメタの組み合わせを探索する際、 AIやソルバを併用する技術として、以下のような論文が発表されていました。
- A High-accurate Multi-objective Exploration Framework for Design Space of CPU (中国科学院) [paper]
- A Comprehensive Automated Exploration Framework for Systolic Array Designs (UCLA) [paper]
- A Model-Specific End-to-End Design Methodology for Resource-Constrained TinyML Hardware (北京大学) [paper]
2. 論理合成時の面積・性能の最適化
等価な論理への書き換えによる面積や性能をAIを使って最適化する技術として、 以下の様な論文が発表されました。
- Automating Constraint-Aware Datapath Optimization using E-Graphs (Intel) [paper]
- AGD: A Learning-based Optimization Framework for EDA and its Application to Gate Sizing (仁川大学校) [paper]
3. タイミングや電力の解析
SPICEシミュレーションや電力予測は正確に行うと非常に時間がかかるため、 予めAIに学習させておき、簡易的な計算でタイミングや電力を見積もる技術として、 以下の発表がありました。
- TOTAL: Multi-Corners Timing Optimization Based on Transfer and Active Learning (北京航空航天大学) [paper]
- PROPHET: Predictive On-Chip Power Meter for Hardware DNN Accelerator (香港科技大学) [paper]
- RL-CCD: Concurrent Clock and Data Optimization using Attention-Based Self-Supervised Reinforcement Learning (Georgia Tech, Synopsys) [paper]
3つ目の論文は Best Paper Award を受賞した7、 Georgia Tech の Sung Kyu Lim 教授の研究グループと、Synopsys社の共著発表です。 Sung Kyu Lim教授の研究グループはトップカンファレンスでの発表や受賞しているとともに、多くの商用ツールへの適用実績もある、世界有数のEDA研究グループです。
本論文では、クロックとデータパスの同時最適化 (Concurrent Clock and Data Optimization; CCD) に強化学習を使った RL-CCD を提案しています。
物理設計においてタイミング違反を解消するには、 クロックを修正するか、データパスを修正するか、など複数の最適化戦略があります。 このとき、違反エンドポイント (タイミング違反の起きている場所) により各最適化戦略に対するエラー改善効果は異なるため、 最適化戦略によって優先すべきエンドポイントが異なってきます。 従来のCCDではこの最適化戦略による優先順位の違いを考慮していないために、うまく最適解が得られません。
RL-CCDでは、
- パスのoverlapを検出することでエンドポイントの候補を絞る Graph Neural Network (GNN)
- エンドポイントのサンプリング確率を出力する自己教師ありAttention機構
- Total Negative Slack 8 を報酬とした強化学習
により、クロック最適化において優先すべきエンドポイントの選択および順位付けを実現しています。 5-12nmプロセス・テクノロジにおける評価を行い Negative Slack を 66.5%削減できることを示しました。
RL-CCDではより良いクロックパス最適化を実現しましたが、 将来的にはフルフロー最適化に拡張し、PPA (Power, Performance, Area) への影響を定量化することを目指しているそうです。 より低コストでより高性能な半導体回路開発に繋がる本研究の今後に注目したいと思います。
4. IPの改ざん・盗用対策
第三者に製造やRTL実装を依頼する際、トロイの木馬などを埋め込まれないようにするために、 実装情報を解析して危険なパタンが埋め込まれてないかをGraph NeuralNetworkを用いて検出する技術、 並びに、 IPの盗用を防ぐために回路に透かしを埋め込み、それを検出する技術の発表もありました。
- Hybrid Obfuscation of Chiplet-Based Systems (McGill Univ.) [paper]
- ActiWate: Adaptive and Design-agnostic Active Watermarking for IP Ownership in Modern SoCs [paper]
5. セキュリティ
セキュリティについてはAIを使った攻撃への対処方法の他、 AIモデルの盗用を防いだり、AIに入力されるデータのプライバシを確保するためのデータ暗号化・難読化の技術も提案されていました。
- MPass: Bypassing Learning-based Static Malware Detectors (精華大学) [paper]
- Safe DNN-type Controller Synthesis for Nonlinear Systems via Meta Reinforcement Learning (華東師範大学) [paper]
- IP Protection in Tiny ML (Washington Univ.) [paper]
- Primer: Fast Private Transformer Inference on Encrypted Data (Indiana Univ.) [paper]
- Gamora: Graph Learning based Symbolic Reasoning for Large-Scale Boolean Networks (UCSB他) [paper]
5件目の論文は Best Paper Award を受賞した9、 Nan Wu 氏 (UCSB)、Cunxi Yu 准教授 (発表時University of Utah、現在はUniversity of Maryland) の研究グループなどによる共著論文です。
RTL合成ツールにより生成されたゲートレベルのネットリストは構造化されていないため、 機能検証や悪意のある回路 (例えばトロイの木馬や知的財産権を侵害する回路) の検出が非常に困難です。 ネットリストから抽象化された機能ブロックを推論 (生成) することでこれらの検証や検出がしやすくなりますが、 従来の推論手法はケーラビリティが低く、大規模回路への適用が難しいこと、計算が非効率であることが課題でした。
本論文で提案する Gamora では、GNNを利用することでスケーラビリティおよび汎用性の高い推論手法を実現しています。 機能情報と構造情報を同時に処理できることから高速である上、GNNの学習により大規模で複雑な回路への適用も可能です。 実験ではGPUも活用し、従来手法よりも最大6桁の高速であることを示しました (精度92%)。
半導体回路設計において不可欠なネットリストはグラフとして表現されるため GNN との相性が良く、 これまでも多くのEDA関連論文で採用されています。 先述したもう1件の Best Paper Award でも GNN を活用しており、今後も EDA 分野における GNN の存在感は大きくなりそうです。
ハードウェアの民主化
半導体チップ設計には設計ツールが不可欠ですが、商用設計ツールのライセン スは非常に高価です。これが、カスタムチップを作る際の足枷になってるとし て、米国ではこれらのツールのオープンソース化を国を挙げて支援しています。
OpenROADは2018年6月に設 立された、オープンソースのSoC自動設計ツールチェーン開発プロジェクトで、 米DARPA (アメリカ国防高等研究計画局) の研究開発プログラムに採択されています。
OpenROADで公開されているツールチェーンを使えば RTL から GDS (マスクレイアウト) を自動で作成することができます。 また、半導体チップ設計にはツールの他に PDK (Process Design Kit) も必要ですが、これは Global Foundries 180nm, SkyWater 130nm, Nangate 45nm, FreePDK45, Predictive PDK (ASAP) 7nmのプラットフォームが提供されています10。
DAC では Open-Source EDA Birds-of-a-Feather Sessionが開催され、 各ツールの最新状況や活用事例などに関する発表が行われました。 Receptionの裏の開催であるにも関わらず多くの参加者がおり、オープンソースEDAの盛り上がりを感じさせるセッションでした。 このセッションでは、
- 大規模設計に対応するためのクラウド環境構築
- Karan Singh (AWS) "Semiconductor Design and Verification on AWS"
- Sameer Shende (University Oregon) "E4S: A Platform for EDA on Commercial Cloud Platforms"
- 設計データのAI入力用への変換ツール
- Rongjian Liang (Nvidia) “CircuitOps and AutoDMP (GenAI and Macro Placement)”
- 学習用データ収集など、AI設計実現に必要な各種課題に取り組むためのコミュニティ立ち上げ
- Vijay Janapa Reddi (Harvard), Amir Yazdanbakhsh (Google) “Architecture 2.0: Challenges and Opportunities with ML-Aided Design”
など、多種多様な発表がありました。
また、商用化のためのプロトタイプ開発においては、設計の他にもチップ試作費など多大なコストがかかります。 更に半導体プロセス複雑化により設計自体も困難になっているため、技術支援も必要です。 最先端研究と実用化の間に横たわるLab-to-Fabの死の谷を各企業が越えられるよう、国家として継続的に、資金および技術の支援を行っています11。
なお、日本でも、東京大学d.labおよび産業技術総合研究所がNEDO事業として AIチップ設計拠点を構築し、 設計環境や技術サポートなどを提供しています。
Stanford大学との共同研究成果の発表
文部科学省の科学技術試験研究委託事業「次世代計算基盤に係る調査研究」とは別に、 我々はStanford大学Subhasish Mitra教授と、3次元集積ICに関する共同研究に取り組んでいます。 DAC の Technical Session で Stanford大学Ph.D. Candidate の Dennis Rich 氏が共同研究の成果として "Thermal Scaffolding for Ultra-Dense 3D Integrated Circuits" を発表しましたので、 内容をご紹介します(paperはこちら)。
微細化の限界とデータ転送帯域の不足という2つの課題への解決策として、 近年3次元積層ダイが実用化されつつあります (AMD 3D V-Cache™など)。 しかしながら、従来のチップではヒートシンクを使ってダイを冷却していたため、 このまま3次元積層すると積層した複数のダイの内、ヒートシンクから遠いダイの冷却が困難になります。 このため、特に発熱量が大きいCPUやアクセラレータなどの演算器を載せたダイの積層は非常に難しくなります (AMD 3D V-Cache™でも演算コアは積層していません)。
本共同研究では、複数の演算ダイを積層し、より高い計算性能をもつチップを実現するために、 下図の新しい放熱構造を提案しています。
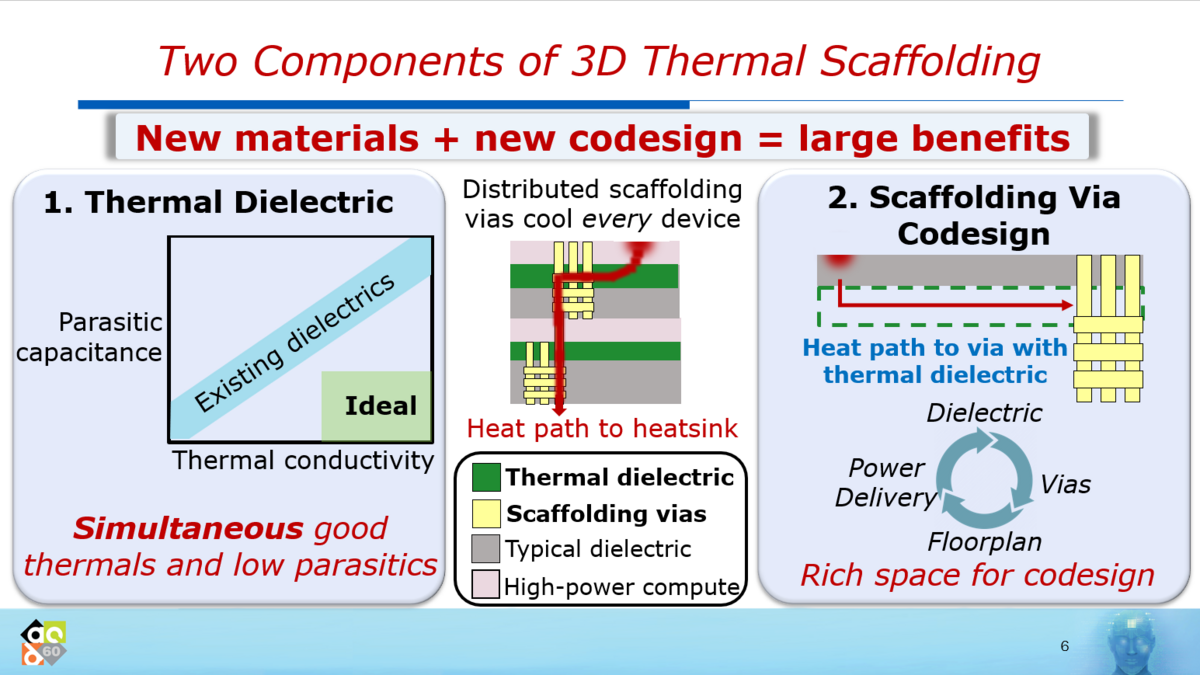
本論文では、熱抵抗の低い新材料の利用とScaffolding構造の2つを提案しています。 また、設計フローを確立し、このフローを用いて3種類のアクセラレータを設計し、熱解析により本提案の有用性を示しました。 熱解析の結果、本提案により7nmテクノロジで設計したアクセラレータを17ダイ積層できるようになることを示しました。 なお、解析に使用したアクセラレータの内1つは、富士通研究所で検討中のデータを使用しています。
本論文の技術はまだシミュレーションでの検討に留まっており、多数の演算ダイを積層したチップの実現はまだ先です。 しかしながら、実現すれば既存のものとは全く異なる演算処理能力をもつCPUやアクセラレータが完成します。 このようなハードウェアの性能を最大限引き出すには、それに合ったアルゴリズムやソフトウェアスタックも不可欠です。 革新的な演算器の登場に備え、将来のハードウェアの特性を予測・理解し、 適切なアルゴリズムやソフトウェアスタックを研究開発していくことも、コンピューティング研究所の仕事です。
終わりに
産休育休から新型コロナ禍を経て、7年振りの海外出張でした。 何から何まで不安でしたが、無事出張を終え、報告も終えようとしています。
国内外共に学会もハイブリッド開催や (オンラインなしの) 現地開催が増えてきました。 移動を伴わないオンライン参加は特に家庭事情がある身には助かりますが、 対面でのコミュニケーションを代替することは困難と感じます。 特に初対面の方との出会いは対面とオンラインでは印象が全く異なります。 今回の出張では、DACの聴講の他、EDAベンダへの訪問もしたこともあり、本当に多くの方と出会い、様々なお話をすることができました。
今回得た知見と縁を最大限に生かし、今後も次世代コンピューティング基盤を支える技術の研究に邁進していきたいと思います。
謝辞
本調査は文部科学省「次世代計算基盤に係る調査研究」事業で実施されたものです。
- HPCwire: DAC Celebrates 60 Years of Innovation with Top Industry Speakers and Record Submissions↩
- 7/9(Sun) What the Next Semiconductor Upcycle Will Look Like for EDA (Charles ShiPrincipal, Research AnalystNeedham & Company, LLC)↩
- 7/12(Wed) SKYTalk: The Cerebras CS-2: Designing an AI Accelerator Around the World’s Largest 2.6 Trillion Transistor Chip [YouTube]↩
- 7/10(Mon) Visionary Talk: Systems 2030 - What's Needed to Succeed in the Next Decade of Design without Resorting to Human Cloning (Mike Ellow) [YouTube]↩
- 7/10(Mon) Keynote: "Corsi e Ricorsi: Here We Go Again" (Alberto Sangiovanni-Vincentelli) [YouTube]↩
- 7/12(Wed) Keynote: Taking AI to the Next Level (Walden Rhines) [YouTube]↩
- Testing Reinforcement Learning in Chip Design | Synopsys Blog↩
- データ到着のタイミング制約までの猶予時間を Slack と呼び、0 より小さいとタイミング違反となる。クロック・ドメイン内のマイナスの Slack の和が Total Negative Slack であり、この値が大きいほどタイミング収束が難しいと考えられる。(参考資料:TimeQuestによるタイミング解析を学ぶ:必修! FPGAタイミング解析の基礎(5) - MONOist)↩
- Best Paper Recipients 2023↩
- https://github.com/The-OpenROAD-Project/OpenROAD-flow-scripts/tree/master/flow/platforms↩
- 7/10(Mon) SKYTalk Microelectronics Security: A Growing National Imperative (Devanand ShenoyU.S. Department of Defense) [YouTube]↩