Introduction
Hello everyone. This is Kawakami from the Fujitsu Laboratories Platform Innovation project. The new Fugaku supercomputer has been delivered to Port Island located off the coast of Kobe. Developed jointly by RIKEN and Fujitsu, this supercomputer has entered the trial run phase this year ahead of schedule. As of June, it has already won four "firsts" in worldwide supercomputer rankings (TOP500, HPCG, HPL-AI, Graph500), so it is off to a very promising start. My department is involved in researching and developing techniques to accelerate deep learning (DL) processes on Fugaku and PRIMEHPC FX1000/700, which is our product that uses the same CPU as Fugaku. In this post, I will talk about our efforts to port oneDNN (library software used to accelerate DL processes) to Fugaku, and to contribute and incorporate our source code into Intel's main branch of oneDNN.
Software stack for deep learning processes
Applications that make use of deep learning processes (hereinafter called “DL processes”) normally consists of a software stack formed from two layers: a framework layer and a library layer (as shown below). When a user wants to run an application that uses a DL process, they use an API provided by the framework to define the neural network for the process to run and to describe processing details. The framework calls library software functions and calculates the actual DL process based on the provided definition and process details. The systems that run DL processes come in various forms and sizes (such as supercomputers, the cloud, PCs, and smartphones), and the hardware in the system that is actually running the process might be a CPU or GPU. By separating the software stack into two layers like this, different systems and hardware executing the DL process are merged in the library layer, so users can use the same framework. This is beneficial because it allows for the same ease of use for all users with regard to defining networks and describing processes.
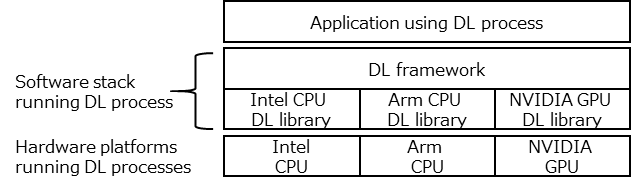
Individually optimized library software is available to maximize system and hardware performance. This software is normally developed by the vendors who develop and manufacture the hardware. For example, Intel and NVIDIA have developed and made available libraries for Intel CPUs and NVIDIA GPUs, respectively. Fugaku and FX1000/700 are equipped with A64FX CPUs, which offer an expanded instruction set called Scalable Vector Extension (SVE) for High Performance Computing on top of the Armv8-A instruction set (the same CPU found in Android smartphones and iPhones). A64FX is the first CPU in the world to offer both the Armv8-A instruction set and the SVE instruction set (hereinafter, they are referred as “Armv8-A instruction set” together), so there was no DL process library optimized for this CPU.
Development of a DL process library for the Arm architecture
There was no DL process library for the Armv8-A instruction set, so we needed to develop a new one. However, even if we at Fujitsu developed a new library on our own, users would not use it unless it could easily be used from the framework. We therefore decided to use the oneDNN DL library, developed by Intel for the x64 instruction set, as a reference implementation. oneDNN is the de facto standard for DL process libraries using CPUs, and it is already supported by a range of frameworks. A deep learning library for Armv8-A that includes APIs for oneDNN could therefore be used without a user having to modify a framework.
The source code for oneDNN has been released as OSS (https://github.com/oneapi-src/oneDNN), so it can be obtained and recompiled for the Armv8-A instruction set. However, oneDNN contains many implementations optimized at the assembler level for the x64 instruction set, so simply recompiling the original source code would not provide enough performance. This was the start of our difficulties. We will discuss this later in this post.
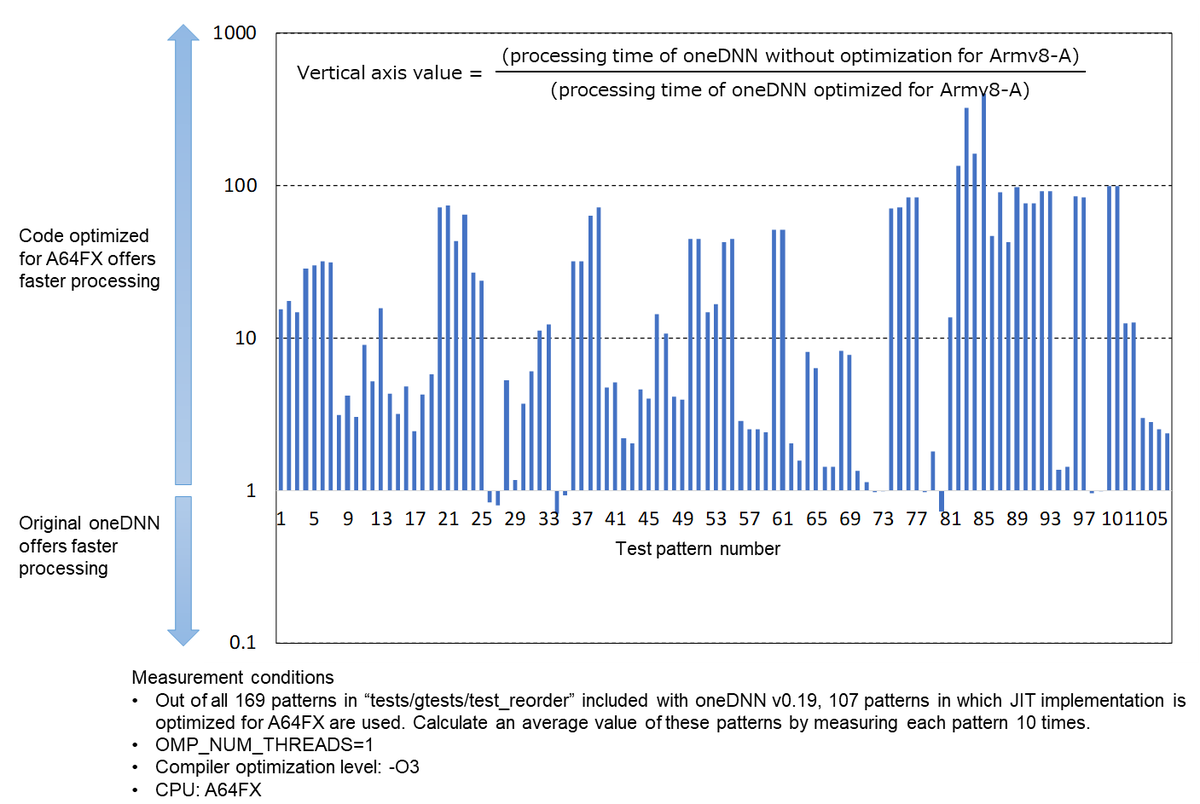
The chart below is an example of the increases in processing speed we obtained through optimizing code for Armv8-A. oneDNN can be used to run a range of processes used in DL processing, such as convolution, batch_normalization, eltwise, pooling, and reorder. The chart below compares the processing speed for the reorder process (in which data types are converted or reordered) when the oneDNN source code is compiled without modification for the Armv8-A instruction set, and when the source code is compiled after our optimizations were implemented. The software processing speed obtained with the original oneDNN source code compiled without modification is normalized as a value of 1. As shown in the chart, we were able to increase the speed up to 400 times over, depending on the type of test pattern (although our optimizations actually decreased the speed for several test patterns, there would be no problem when using this together with a framework due to the small absolute values in measurement errors and processing times). Optimizing code for A64FX also resulted in extraordinary processing speed increases in other processes as well.
Contribution of source code to the main branch of oneDNN
I mentioned earlier that oneDNN source code has been released as OSS, but that is not all. It is being developed using an open development style that allows anyone to submit a pull request for source code they want to improve (request to incorporate improved source code into oneDNN). When a pull request has been submitted, the new source code is reviewed for bugs and tested to confirm that it improves the processing speed of oneDNN or helps to expand its functionality. If it passes both the review and test, it is incorporated into oneDNN. oneDNN is a software developed initially for CPUs with the x64 instruction set. The source code for our version of oneDNN, ported to and optimized for the Armv8-A instruction set, is available at https://github.com/fujitsu/oneDNN. However, we thought that it would be beneficial for Fugaku users and many users in the world of CPUs that use the Armv8-A instruction set, if an implementation highly tuned for the main branch of oneDNN (the de facto DL process library) had been incorporated from the start. We therefore decided to work with Intel and actively submit a pull request to incorporate our changes into the main branch of oneDNN.
Incidentally, the improvements we made optimizing oneDNN for the Armv8-A instruction set were quite extensive, such as incorporating a required descriptor called Xbyak_aarch64 (explained later). For minor changes, all you need to do is modify the source code and submit a pull request. However, when submitting a pull request for large-scale changes to source code or for changes to APIs for parts related to the framework for oneDNN, you must first write a document called a Request For Comments (RFC) that describes what will be changed and summarizes the plan for doing so. Then, you must submit a pull request for the RFC itself for review and then merging. I put a lot of effort into writing the RFC knowing that this would benefit the many users of Fugaku and Armv8-A in the world. I treated this even more seriously than writing a research paper. It was a ton of work. But I finally did it. I submitted my RFC pull request. Before long, I received a question from an Intel developer on the RFC. I worked late into the night to make sure my answer was thorough. Then I went to sleep. And then I woke up. And then there was the next question. The Intel developer was located in the US, and because of the time difference the next question had been sent by the time I woke up. Not getting discouraged, I sent my response. Then I went to bed. And then I woke up. Next, the Intel developer had invited a developer from Arm to join in, since my RFP concerned an Arm product. It was now two-on-one battle. The Arm developer was located in the U.K. It was like we were playing volleyball and Arm and Intel had teamed for a spike fake-out. I could barely keep up. However, I were somehow able to answer all of their questions and they ultimately approved the RFC I had submitted. (Actually, they were really great people that treated me very kindly and asked purely technical questions. The fact that their questions came right after I responded due to the time difference actually meant that the process was going smoothly and shortened the time up to merging of the RFC.)
Once the RFC was merged, I next needed to submit a pull request for source code modified based on the RFC. I was able to keep up with the “spike fake-outs” by Arm and Intel, and ultimately had the source code merged. Having the source code (optimized for the Armv8-A instruction set) merged in an OSS project spearheaded by Intel caused quite a commotion in Fujitsu. It makes sense though. After all, from Intel’s perspective this would help collaborating companies. Of course, the primary reason for this was that Intel opened the door on pull requests for other CPUs. So first of all, I would like to express my gratitude here for Intel. The secondary reason for this is that our source code was technically solid and that Intel recognized that it would help in developing DL process libraries. I do have to admit that I am a bit proud of this.
Development of Xbyak_aarch64
It is now time to discuss at some depth the technical aspects of porting and optimizing oneDNN for the Armv8-A instruction set. One of the key technologies in Intel's oneDNN is that it incorporates a JIT assembler called Xbyak (see the figure below).
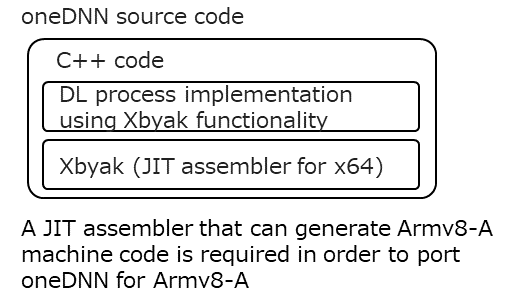
Xbyak is a software developed by Shigeo Mitsunari of Cybozu Labs and released as OSS (https://github.com/herumi/xbyak). Xbyak offers the following features.
- Assembler programs can be written in C++
- Executable code is generated during execution
If you consider just the first feature, you might wonder how this is any different from an inline assembler or specifying assembler instructions using intrinsic functions. However, Xbyak allows an entire subroutine including the header of the loop processing section and the footer section to be written completely at the assembler level, which means the developer can create their intended instruction sequence without any unintended instructions being inserted when compiling. The second feature is very powerful. This allows optimal executable code to be created independently in a way that takes platform information (such as the number of CPU cores, amount of cache memory, and corresponding instruction set) during execution into consideration, as well as parameters determined during execution. This allows for highly optimized executable codes to be created. For example, it would be possible to generate executable codes with optimal loop segmentation based on the number of CPU cores or the amount of cache memory. In another case, when it is guaranteed that conditional branch processing is never executed depending on the parameter determined at the time of execution, executable codes omitting the conditional branch processing can be generated. If interested, you can find out more about Xbyak in a presentation created by its developer, Shigeo Mitsunari (https://www.slideshare.net/herumi/xbyak). Xbyak itself also comes with sample code for reference.
Incidentally, Xbyak is a software that generates executable code for the x64 instruction set. It therefore cannot be used for A64FX, which implements the Armv8-A instruction set. In order to port oneDNN to Armv8-A, we needed to create new software that would implement the same functionality as Xbyak for the Armv8-A instruction set. There are more than 4,000 types of instructions in the Armv8-A instruction set, if operand variations are also included. In other words, we needed to implement and verify more than 4,000 functions to generate machine code. By the way, there are more than 10,000 instructions for x64. You would not even want to count that many.
This presented a massive development challenge. However, we were fortunate to receive technical advice and help from the developer of Xbyak, Mr. Mitsunari (please refer to a blog written by Mr. Mitsunari(https://blog.cybozu.io/entry/xbyak_for_fugaku) and a related article of Gijutsu-Hyohron Co., Ltd. (https://gihyo.jp/news/interview/2020/12/1801)), and were ultimately able to release Xbyak for Armv8-A under the name Xbyak_aarch64 on https://github.com/fujitsu/Xbyak_aarch64. As I mentioned earlier, your Android smartphone or iPhone contains a CPU that uses the Armv8-A instruction set (however, it does not support SVE instructions). That means you can run executable code for the Armv8-A instruction set generated using Xbyak_aarch64. Someday, you may even find software made using Xbyak_aarch64 running on your smartphone.
Having completed Xbyak_aarch64, we could now start preparing to port oneDNN to A64FX. Xbyak is used to implement a range of processes used by DL processing for oneDNN, such as convolution, batch_normalization, eltwise, pooling, and reorder. We decided first to use Xbyak_aarch64 to port the simplest process, reorder, to the Armv8-A instruction set. As we continued to master implementation and debugging methods using JIT assembler, we were finally able to complete our implementation and verify its functionality. We decided to see how good Fujitsu Laboratories Xbyak_aarch64 really is, so we compared the difference in processing speed between an implementation using Xbyak_aarch64 with an implementation where the original oneDNN algorithm was written as is in C++. The graph included in the “Development of a DL process library for the Arm architecture” section shows the results of our measurements. We were surprised by the results even though we created it ourselves. We did not expect a two-digit or more increase in speed, with a maximum increase 400 times over.
Development of Xbyak_translator_aarch64
Completing Xbyak_aarch64 essentially allowed us to port oneDNN for A64FX. However, there was still one problem. We did not have enough time to develop the port. Using Xbyak_aarch64 to rewrite may sound simple, but it actually involves several steps (see the figure below).
- Check for functions implemented with Xbyak in the source code for oneDNN, and then check the Intel CPU reference manual to determine which processes are run by the Intel CPU instructions generated by each function.
- Check for sections of oneDNN source code implemented using Xbyak, and then determine what executable code is generated and what processes are performed by the executable code overall.
- In order to generate executable code for Armv8-A (determined in Step 2), check the Armv8-A reference manual to determine which Armv8-A instructions should be used, and then use functions provided by Xbyak_aarch64 to code them.

This would be a lot of work. It would be like having to translate a foreign language you do not know, into another foreign language you also do not know. Luckily, I had Dr. Honda, who is an expert at optimization, sitting nearby for help. Even so, oneDNN has a lot of processes for DL and porting everything would be a difficult task even for a brilliant researcher. On the other hand, developers who could code while understanding the implementation at the assembler level are few and far between these days, so it would be difficult to gather a team even if that option was a possibility. I was stuck. I decided to develop a JIT assembler translator that could generate Armv8-A executable code without (more or less) having to rewrite source code implemented using Xbyak. I called it Xbyak_translator_aarch64 (codename:Xbyak Instrumentality Project).
The figure below shows how Xbyak_translator_aarch64 (“Translator” below) works. Translator generates machine code for Armv8-A instructions as follows.
- Xbyak is used to generate x64 machine code.
- The machine code generated in Step 1 is decoded, then the instruction type (add, sub, mov, vpaddd, vpsubd, vpmovusdw, etc.) and operand information (register operand: register type [general-purpose 32/64-bit register, xmm/ymm/zmm register], register index, memory operand: addressing mode, address register, displacement, etc.) are obtained.
- Based on the information obtained in Step 2, this is converted into the corresponding Armv8-A instruction sequence (a single x64 instruction is converted into one or more Armv8-A instructions), the Xbyak_aarch64 function corresponding to this instruction sequence is called, and an Armv8-A machine code sequence is generated.
- Steps 1 through 3 are performed for all x64 machine code generated using Xbyak.
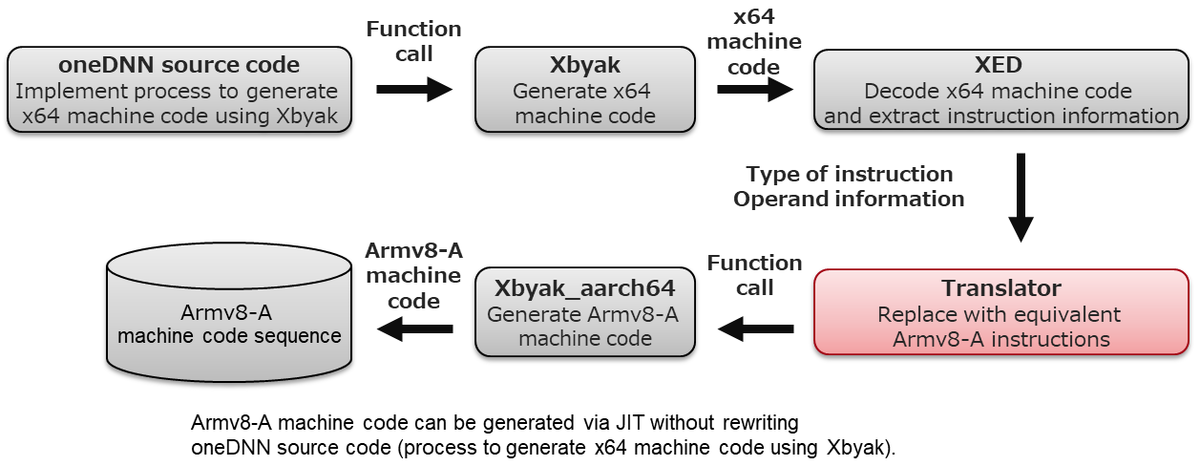
The process for decoding x64 machine code (in Step 2) could be taken care of with a library called Intel XED released by Intel as OSS, so no development was required for this step. Development of Translator therefore mainly focused on defining the correspondence relationship between x64 instructions and Armv8-A instruction sequences (from Step 3).
Actually, this kind of approach was not considered when I was first thinking of implementing Xbyak_translator_aarch64. I tried implementing this without going through steps 1 and 2 above, leaving the Xbyak interface (function call arguments and return values) as is but modifying the implementation within, and directly calling Xbyak_aarch64 functions. However, I could not get this to work. The x64 instruction set has a long history of expansion, and uses an extremely complicated instruction encoding system. It would not be possible to quickly learn what information was encoded, and where. When working with this kind of software, the thing to worry about is bugs that cause erroneous behavior at the instruction level (this was true for developing Xbyak_aarch64 as well). If even a single mistake was made in converting x64 instructions into Armv8-A instructions, the program would not run correctly. I could also tell that debugging a conversion error later on would be extremely difficult. The subroutines generated by oneDNN using Xbyak can be very complicated, with the most complicated subroutines consisting of instructions with more than 10,000 steps. Imagine that the program runs fine but the calculation it provides is wrong. That means there was some mistake made converting an instruction somewhere in a block of 10,000 steps. How would you find it?
I decided to rethink my approach. First, we would generate all the x64 machine code. We would then reverse assemble it and extract information from each x64 instruction in a way that made it easy to understand. Then we could deal with it as shown in the figure above. We were lucky to get an advice from Mr. Mitsunari quickly, suggesting that this approach meant we could use Intel XED for the reverse assembly process. This allowed us to develop Xbyak_translator_aarch64 without any issue.
You might be wondering whether there was enough processing overhead for Translate. Good question. Actually, the process that generates Armv8-A machine code sequences does take some time, since it needs to generate x64 machine code using Xbyak, decode it, and then generate corresponding Armv8-A machine code. Having said that, it takes less than a second. Consider a DL process such as learning a neural network to identify images. This is done by repeatedly processing teaching image data consisting of millions of images. This would take a supercomputer several hours or days to calculate. It takes only a second to generate executable code, which is a negligible amount in comparison. How DL processes calculate data in this way was also taken into consideration when selecting the development process that was ultimately used.
Translator would allow us to take oneDNN source code implemented for x64, and to reuse it for the Armv8-A instruction set without having to rewrite it. Translator would take care of any differences in the x64 and Armv8-A instruction sets. oneDNN is still actively developed today. New DL processes are added daily, and Xbyak continues to be used to further optimize it for the x64 instruction set. We can now offer these new functions and optimizations for Armv8-A at a much quicker pace. We actually have tried using Translator to port parts of oneDNN v1.6 implemented with Xbyak to Armv8-A. In about two weeks, we were able to get it running with sufficient processing speed1 on A64FX. It took Intel more than four years of continual optimization to develop oneDNN for x64. We were surprised how quickly it could be ported. The source code for Translator has also been released as OSS, and can be found at https://github.com/fujitsu/Xbyak_translator_aarch64. Please take a look if you are interested.
Achieving the highest level of processing speed for CPU-based DL
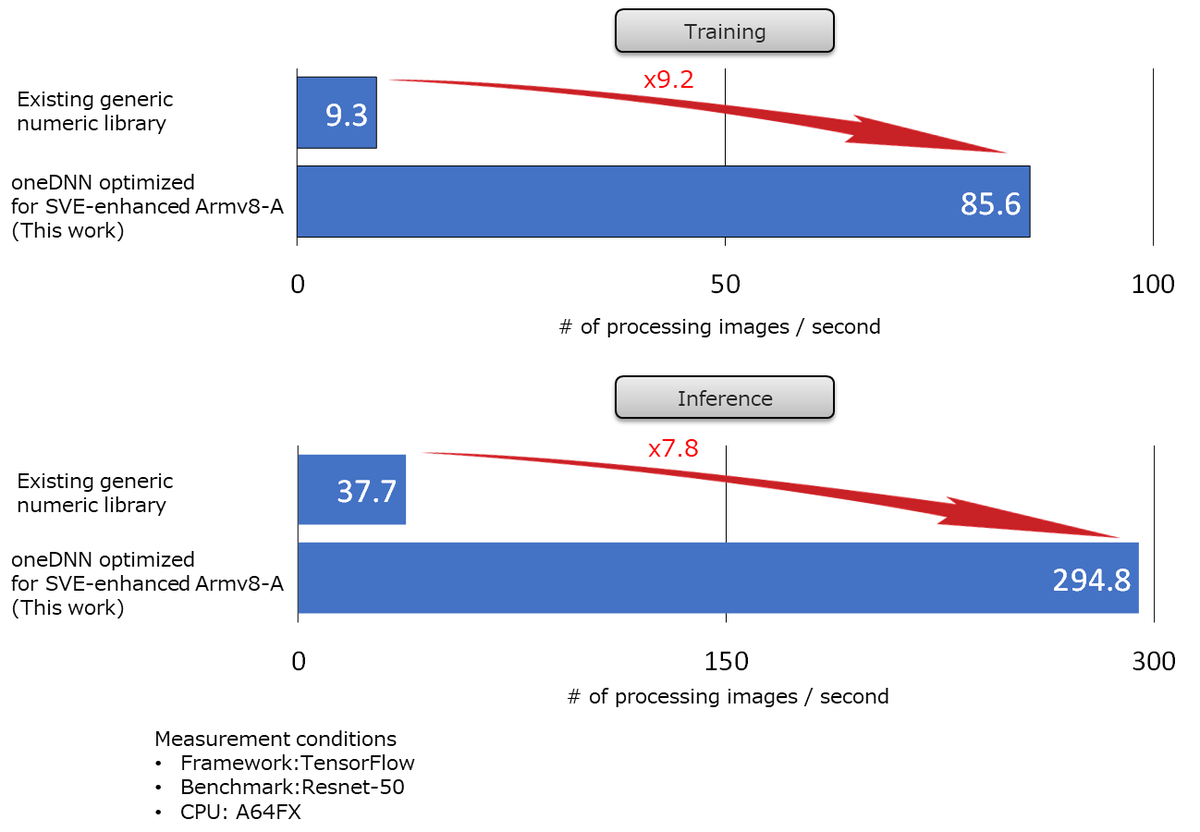
With two software in our hands, Xbyak_aarch64 and Xbyak_translator_aarch64, we have completed the porting of oneDNN for Armv8-A instruction set. The chart below shows the measured processing speed of Resnet-50 when TensorFlow was used as a framework software. When running on A64FX, the original oneDNN just compiled for Armv8-A is hundreds of times slower than that of optimized for Armv8-A as shown in the chart at the beginning. So, we compared our oneDNN with a generic numerical processing library. Our oneDNN optimized for Armv8-A allows for a significant speedup of 9.2 times in the training process and 7.8 times in the inference process.
We can generate instruction-level optimized executable code using Xbyak_aarch64, and we used Xbyak_translator_aarch46 to save a significant amount of development time through source code diversion for x64.
We have also released a version of oneDNN that incorporates Xbyak_translator_aarch64 and that uses a method that indirectly generates JIT code for the Armv8-A instruction set from implementations for the x64 instruction set. This version is located at https://github.com/fujitsu/oneDNN. As I mentioned at the beginning of this post, Xbyak_aarch64 and the JIT implementation for the reorder process have been sent out a pull request to the original oneDNN, and have been formally incorporated. We'll be sending out pull requests for other processes as well.
We are developing Xbyak_aarch64/Xbyak_translator_aarch64/oneDNN optimized for Armv8-A with an open style. We disclose all the source code at the https://github.com/fujitsu. Anyone involved in developing Xbyak_aarch64, Xbyak_translator_aarch64, or oneDNN is very much welcomed. If you would like to add functionality or try improving the source code, please do consider posting an ISSUE, submitting a pull request, or mail to arm_dl_oss[at mark]ml.labs.fujitsu.com.
Conclusion
We have finally optimized and ported the oneDNN DL process library software (which continues to be developed as OSS) for the Armv8-A instruction set so that it can run at high speed on the Fugaku supercomputer. In this article, we introduced JIT assembler Xbyak_aarch64 for Armv8-A (a key technology required for porting oneDNN), and discussed the development history of Xbyak_translator_aarch64 which accelerates port development. The Xbyak_aarch64 JIT assembler we developed has been officially incorporated into the main branch of oneDNN along with the source code generated using Xbyak_aarch64, which is optimized for the Armv8-A instruction set. We plan to continue to submit pull requests for our implementation optimized for Armv8-A. We will continue our research and development, dreaming of the day when the DL will be close enough to you to run our software on your smartphone.
Authors

Kentaro KAWAKAMI(the right side in the photo)
He joined Fujitsu Laboratories Ltd. in 2007. He has been involved in R&D of image codec LSIs and wireless sensor nodes, and is currently engaged in R&D of AI software for Arm HPC. His GitHub account name is "kawakami-k".
Kouji KURIHARA(the left side in the photo)
He joined Fujitsu Laboratories Ltd. in 2009. He has been involved in R&D of embedded multi-core processor software, HEVC codec LSIs, wireless sensor nodes and visualization of wireless communication interference, and is currently engaged in R&D of AI software for Arm HPC. His GitHub account name is "kurihara-kk".
Naoto FUKUMOTO(the center in the photo)
He joined Fujitsu Laboratories Ltd in 2012. He has been involved in R&D of optimization for various HPC applications and library software. Since 2019, he leads R&D of AI software for Arm HPC as a manager.
-
It is said to have roughly 70% the performance of the latest Intel CPUs. In order to get the maximum performance out of A64FX, optimized JIT code should be assembled using Xbyak_aarch64 directly for handling bottlenecks instead of going through Translator.↩